Malvastrum yellow mosaic Jamaica virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002867575.1 |
| Isolate | Jamaica |
| Release date | 2018/8/26 |
| Submitter | Graham,A.P., Roye,M.E. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
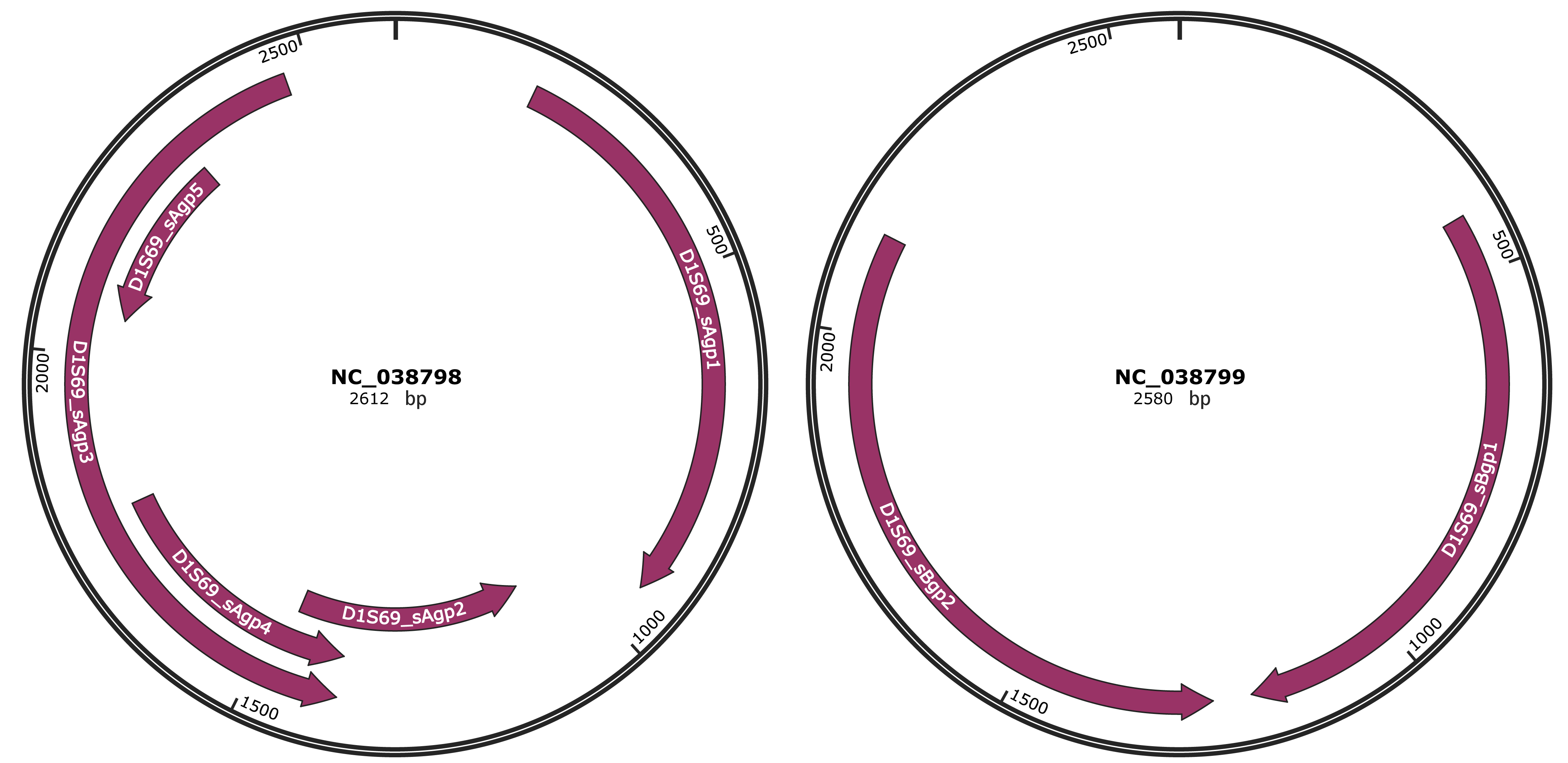
JBrowse
Genome
NC_038798
ACCGGATGGCCGCGCTTTGGTGACACTGTCACCCTCGCTTTAATTTCGAATTAAAGCGGGCTCCGCTTTTGTTCTGACCAATCATATTGCGCCTGACGCGCCTAAATATTTTAAACAACTTGGGCCCTAAGTTGTTGTCTGGGCTATATATGAAAAGCGTATTGGGCCATAGTGGTTAACCCAATATGTCTAAGCGGGATGCCCCATGGCGTTCAATGGCGGGAATGTCAAAGGTCCGCCGTACTCTTAATTATTCTCCTCGTGCAGGTTTGGGCCCTAAGTTCAACAAGGCCGCTGAGTGGGTGAACAGGCCCATGTACAAGAAGCCCAGGATATATCGGACGCTAAGGACCTCAGATGTGCCGAGAGGCTGTGAAGGCCCGTGCAAGGTCCAGTCATATGAACAGCGCCATGATATCTCACATGTCGGGAAGGTCATGTGTATATCCGATGTCACACGTGGTAATGGCATCACCCATCGTGTGGGCAAGCGTTTCTGTGTTAAGTCTGTGTATATATTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGCGTTATGTTCTGGTTGGTCAGGGATCGTAGACCGTATGGCACTCCTATGGATTTCGGTCAGGTATTCAACATGTATGACAACGAGCCTAGCACTGCAACCATCAAGAATGATCTACGTGATCGTTATCAGGTCATGCACAGGTTCTATGGCAAGGTCACAGGTGGTCAATATGCCAGCAACGAGCAGGCATTGGTCAGGCGATTCTGGAAGGTCAACAATCATGTGGTATACAATCATCAAGAGGCTGGCAAATATGAGAATCATACGGAGAATGCCCTATTATTGTACATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAAATTTAAATTTTATTTCATGATCTTCTAGTACATATCTTACATACGATTTGTCTGTTGCAAACTGAACAGCTCTAATTACATTGTTAATTGAAATCACGCCTAACTCGTCTAAATACATATTAACTAGTTGTCTAAACCTAACTAAATAAGTTGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAAGTAAGCTTTGTGGAGACCCAACACTCTCCTCAGGTTGTGGTTGAACCGTATTTGTATGTGATACACCCTGGTTCTGGTGTATAACAGGTCTTCTACTCTGTATATCATGAAATAGAGGGGATTTTCTATCTTCCAGATATACACGCCATTCTCTGCCTGATGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGTCCTGTACAGTCTATGTGGAAGTAGATGGAGCACCCGCACTCTAGATCAATCCTGCGTCTCCTGATGGCCCTCCTCTTGGCTTGTTTGTGTGCCTTCTTGATAGAGGGGGGCTGTGAGGGTGATGAAGATAGCATTCTTGAGAGTCCAGTTCCTGAGACCTGTGTTTTCCTCTTTGTTCAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGCTGGTATCCCGCCTTTAATTTGAACTGGCTTCCCGTACTTGCAATTTGATTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGATGTTATACTCCACATCGTTTGAGAAGACCTTTGAATTGAAGTCCAGGTGGCCACTGAGATAGTTATGTGGGCCTAAGGCACGAGCCCACATCGTCTTCCCTGTTCTCGAGTCACCCTCTACTATGAGACTTACTGGTCTCTCCGGCCGCGCAGCGGCACCTCTCCCAAAATAACTGTCCGACCATTCTTGCATCTCGTCGGGAACGTTAGTGAAAGAGGAGAGGGGAAACGGAGGAGACCATGGATCCGGAGCCTTCATGAAAATCCGATGAGCATTGGCAACCAAATTGTGATGTTGAAGGAAGAAATGTTGAGGCTGCTCCTCCTTGATTATTTGAAGAGCCTCTTCAGCAGAAGAGGCATTCAACGCCTTGGCATATGTGTCGTTAGCCGATTGGCAACCTCCTCTAGCACTTCTACCGTCGATCTGGAATTCCCCCCATTCCAGTGTGTCTCCGCCCTTGTTGACATAGGACTTGACGTCGGAGCTCGACCTAGCTCCCTGTATGTTTGGATGGAAATGTGTTGACCGAGTTGTGGGTACCAGGTCGAAGAATCTGTTATTCGTGCATGCATATTTCCCTTCGAACTGTATAAGCACGTGGAGATGAGGCTTCCCATTTTGATGAAACTCTCTGCAGATCTTGATAAACTTCTTGTTTACTGGAGTTGAAAGGTTTTGCAGTTGAGATAATGCTTCCTCTTTGCTAAGTGAACAGTCTGGATAAGTTAGGAAATAGTTTTTGGCATTTATTTTAAAACGTTTAACTGATGGCATTTTTGTAATAATAGGGTGTTCCCCAATTGAGCTCCTCTCAAACTTGCTCATGCAATTGGGGAAACGGGGTACAATATATACTAGAACCCTCAATAGAACTTTAGATCTCGTTCGCACACGTGGCGGCCATCCGCTATAATATT
NC_038799
ACCGGATGGCCGCCCGCGCCCCCCTCCCTCACGCGCGTGGAGTTCTCCCATTCTCACGCGGCGCTCTGATGGTGCCACCTGTCCTCTCCGCTCTCGCTCCCTCTCCCAGATGGTGCCACCTGGCTCCCGCTCCCCAACGTGCTTAGTGCGCGAGTGTGCTTTATTCCACTGACTGACCTTTAATTCAAATTAAAGAGGTGTTTGACTAGATCGCGCGAGTTGGGCCAAATTTGACTGGCCCAGTTTATGATACACTCGACGTGGCCGATTATCGACCATGTTGCTGAGTTAGTTTACTATACATGTTGAACAACCTTGTCGTATTTAAATGGTATACTTATATGGCGTATTTTATGTAACTCAGCTGTATACCACGTTTATATTACTAGCCATAATTACAATTTATCTGTCATTAATATTTGATCATGTATTCTTTTAAGAATAAACGTGGTTTCGTCTTTAATCAGCGTCGATTTCATTCAAGGAACATTGTGTCTAATCGATCAACTAGATTTAAGAAATCTGATGGGAAACGTCGACTGGGTAATTCAGCTAAGTCCAATGATGAGCCTAAGATGTCAGCCCAGTGCATACATGAGAATCAATATAGTCCAGAGTTTGTTATGTCAAATAACTCGGCTATATCTACATTTATCAGTTATCCTAACCTGGGAAAGACAGAACCCAGTCGAAGTAGGTCCTATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTTAAGATTGAGCGTGTTCAATCTGATGTTAACATGGATGATTCTGTCCCCAAGTTGGAAGGTGTCTTCTCACTCGTTGTAGTTGTGGATCGTAAACCACATTTGGGTCAGACTGGTTGTTTGCATACATTCGACGAACTATTTGGTGCATTGATCCACAGTCATGGTAACCTCAGCATAACTCCTTCTCTGAAAGACCGTTTCTATATTAGACACGTGTTCAAACGTGTGTTGTCTGTGGATAAGGAAACGACGATGTTTGACGTGGAAGGGTGTACATCGCTGTCTAATAGACGATTCAATTGTTGGGCATCGTTCAAAGATCTTGACCATGACTCGTGCAAGGGTGTTTATGATAATATTAGCAAGAATGCTCTATTAGTGTATTATTGTTGGATGTCAGACACTATGTCTAAAGCATCTAGTTTTGTATCGTTCGATCTCGATTATGTTGGGTGATTAATAAAATAACATTTTATTATATATTATTGAATAATAATATTAAAACTCTATTGCAAAGATTTGGGCTGAGAAGCCCTACAATTACTATTAATACACTCTTGGACTGTTGTCCTGACTAATTCATTTAATTGGCCCAATGACATCGTGATGTTGGATTCCGCTCTCTGGGCCCGTAATACTGAAGCAGACTCTCCCGGGTCCAGAACTGTTGTGCCTAGCCTGCTCATATGTCTGTATGGATGCAGTTCGTTTTCTACTTCTGAGTCCACATCTGAATGGCCCATTCCCAATGTACTCCTGGAAGCCCATGATTCACCAGGCCTTATTTCAATTGGGCCTCTTAAGCCTACTCTCGACATGGATGCGCATCGTATGGGCTTCCTCTCCCATTTCCCATAGTCCACATGCGAGAAGTCCACATCTTTGTCTGTAAACTGTTTGGACAGGATCTTGACCGTCGGTGCCCGAAACGGGATATCCACCGAGTGTTTGGCTGTGGACAATTTCAGCTTCCCCTTGAACTTGGCGAAGTGGGTTCTCTGATGAACATTCGTATCAGAAACTCTGTAATAGAGTTTCCAAGGAATTGGGTCTTTTAGAGAGAAGAAGGAAGCTGAGAAATAGTGGAGATCTATGTTGCATCTGATCGGAAAAGTCCATGACGCCTGTAATGACTCATTGTCTGTCATCCTCTTGTCATGGATCTCCACGATTACTGTCCCAGAAGCGTTAATTGGGACCTGTTGCCTGTACTCTATGACACAATGGTCGATCTTCATACAGCTTCTGCTAAGTCTAGCGCTTATTTGTGCCGCCGTCGAAGGGAATTGCAAGATTATCTCAGTTAAGTCGTGGCAGAGTTGATATTCATCTCTGTGGGACTCTATGTAGTTGAAGGCACATGGGGGATTTACTAGCTGAGAATCCATCTGAGAAATGAAGGCCGCGCAGCGGCACTGGTTGCTGAGGTTGATCTGCTAAAGAAAAATCTAGGGTTTTTCTGTTTTTGAACAGACTAATAATTTCATGGGAAGGATAGATGATTTCTGGGAAACCCAGAAGTTTAAAGGAAATAAGGAAGAACACTCGTTTAAGTTCACAGAAGTTTATAGTGTTCTTGAGAAAAGGGAGAAATATGAAAAGGAAAATGATGTTTATGTAGTTAGATCTGACATGGATTATATAGACAGTCATATATTTAAGTTATAATGGCATTTTCCGTAAATATGGGTGTTCCCCAATTGAGGCTCTGGGTGTTCCCCAATTGAGGCTCTCTCAAACTTGCTCATGCAATTGGGGAAACGGGGTACAATATATACTAGAACCCTCAATAGAACTTTAGATCTCGTTCGCACACGTGGCGGCCATCCGCTATAATATT
Gene Information
| NCBI Accession | YP_009507999.1 |
|---|---|
| Location | 186-941 |
| Protein Name | CP |
| Coding Region | ATGTCTAAGCGGGATGCCCCATGGCGTTCAATGGCGGGAATGTCAAAGGTCCGCCGTACTCTTAATTATTCTCCTCGTGCAGGTTTGGGCCCTAAGTTCAACAAGGCCGCTGAGTGGGTGAACAGGCCCATGTACAAGAAGCCCAGGATATATCGGACGCTAAGGACCTCAGATGTGCCGAGAGGCTGTGAAGGCCCGTGCAAGGTCCAGTCATATGAACAGCGCCATGATATCTCACATGTCGGGAAGGTCATGTGTATATCCGATGTCACACGTGGTAATGGCATCACCCATCGTGTGGGCAAGCGTTTCTGTGTTAAGTCTGTGTATATATTAGGGAAGATATGGATGGATGAGAACATCAAGCTCAAGAACCACACGAACAGCGTTATGTTCTGGTTGGTCAGGGATCGTAGACCGTATGGCACTCCTATGGATTTCGGTCAGGTATTCAACATGTATGACAACGAGCCTAGCACTGCAACCATCAAGAATGATCTACGTGATCGTTATCAGGTCATGCACAGGTTCTATGGCAAGGTCACAGGTGGTCAATATGCCAGCAACGAGCAGGCATTGGTCAGGCGATTCTGGAAGGTCAACAATCATGTGGTATACAATCATCAAGAGGCTGGCAAATATGAGAATCATACGGAGAATGCCCTATTATTGTACATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACATTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MSKRDAPWRSMAGMSKVRRTLNYSPRAGLGPKFNKAAEWVNRPMYKKPRIYRTLRTSDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATIKNDLRDRYQVMHRFYGKVTGGQYASNEQALVRRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_009508000.1 |
|---|---|
| Location | 1083-1472 |
| Protein Name | TrAP |
| Coding Region | ATGCTATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAAACAAGCCAAGAGGAGGGCCATCAGGAGACGCAGGATTGATCTAGAGTGCGGGTGCTCCATCTACTTCCACATAGACTGTACAGGACATGGATTCACGCACAGGGGAACTCATCACTGCACATCAGGCAGAGAATGGCGTGTATATCTGGAAGATAGAAAATCCCCTCTATTTCATGATATACAGAGTAGAAGACCTGTTATACACCAGAACCAGGGTGTATCACATACAAATACGGTTCAACCACAACCTGAGGAGAGTGTTGGGTCTCCACAAAGCTTACTTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCAACTTATTTAGTTAG |
| Protein Sequence | MLSSSPSQPPSIKKAHKQAKRRAIRRRRIDLECGCSIYFHIDCTGHGFTHRGTHHCTSGREWRVYLEDRKSPLFHDIQSRRPVIHQNQGVSHTNTVQPQPEESVGSPQSLLELPSLDDIDDSFWVNLFS |
| NCBI Accession | YP_009508001.1 |
|---|---|
| Location | 1384-2469 |
| Protein Name | Rep |
| Coding Region | ATGCCATCAGTTAAACGTTTTAAAATAAATGCCAAAAACTATTTCCTAACTTATCCAGACTGTTCACTTAGCAAAGAGGAAGCATTATCTCAACTGCAAAACCTTTCAACTCCAGTAAACAAGAAGTTTATCAAGATCTGCAGAGAGTTTCATCAAAATGGGAAGCCTCATCTCCACGTGCTTATACAGTTCGAAGGGAAATATGCATGCACGAATAACAGATTCTTCGACCTGGTACCCACAACTCGGTCAACACATTTCCATCCAAACATACAGGGAGCTAGGTCGAGCTCCGACGTCAAGTCCTATGTCAACAAGGGCGGAGACACACTGGAATGGGGGGAATTCCAGATCGACGGTAGAAGTGCTAGAGGAGGTTGCCAATCGGCTAACGACACATATGCCAAGGCGTTGAATGCCTCTTCTGCTGAAGAGGCTCTTCAAATAATCAAGGAGGAGCAGCCTCAACATTTCTTCCTTCAACATCACAATTTGGTTGCCAATGCTCATCGGATTTTCATGAAGGCTCCGGATCCATGGTCTCCTCCGTTTCCCCTCTCCTCTTTCACTAACGTTCCCGACGAGATGCAAGAATGGTCGGACAGTTATTTTGGGAGAGGTGCCGCTGCGCGGCCGGAGAGACCAGTAAGTCTCATAGTAGAGGGTGACTCGAGAACAGGGAAGACGATGTGGGCTCGTGCCTTAGGCCCACATAACTATCTCAGTGGCCACCTGGACTTCAATTCAAAGGTCTTCTCAAACGATGTGGAGTATAACATCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAATCAAATTGCAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGGATACCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACACAGGTCTCAGGAACTGGACTCTCAAGAATGCTATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAAACAAGCCAAGAGGAGGGCCATCAGGAGACGCAGGATTGA |
| Protein Sequence | MPSVKRFKINAKNYFLTYPDCSLSKEEALSQLQNLSTPVNKKFIKICREFHQNGKPHLHVLIQFEGKYACTNNRFFDLVPTTRSTHFHPNIQGARSSSDVKSYVNKGGDTLEWGEFQIDGRSARGGCQSANDTYAKALNASSAEEALQIIKEEQPQHFFLQHHNLVANAHRIFMKAPDPWSPPFPLSSFTNVPDEMQEWSDSYFGRGAAARPERPVSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSKVFSNDVEYNIIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLNKEENTGLRNWTLKNAIFITLTAPLYQEGTQTSQEEGHQETQD |
| NCBI Accession | YP_009508002.1 |
|---|---|
| Location | 1384-1782 |
| Protein Name | REn |
| Coding Region | ATGTGGGCTCGTGCCTTAGGCCCACATAACTATCTCAGTGGCCACCTGGACTTCAATTCAAAGGTCTTCTCAAACGATGTGGAGTATAACATCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAATCAAATTGCAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGGATACCAGCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACACAGGTCTCAGGAACTGGACTCTCAAGAATGCTATCTTCATCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAAACAAGCCAAGAGGAGGGCCATCAGGAGACGCAGGATTGA |
| Protein Sequence | MWARALGPHNYLSGHLDFNSKVFSNDVEYNIIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLNKEENTGLRNWTLKNAIFITLTAPLYQEGTQTSQEEGHQETQD |
| NCBI Accession | YP_009508003.1 |
|---|---|
| Location | 2055-2312 |
| Protein Name | AC4 |
| Coding Region | ATGGGAAGCCTCATCTCCACGTGCTTATACAGTTCGAAGGGAAATATGCATGCACGAATAACAGATTCTTCGACCTGGTACCCACAACTCGGTCAACACATTTCCATCCAAACATACAGGGAGCTAGGTCGAGCTCCGACGTCAAGTCCTATGTCAACAAGGGCGGAGACACACTGGAATGGGGGGAATTCCAGATCGACGGTAGAAGTGCTAGAGGAGGTTGCCAATCGGCTAACGACACATATGCCAAGGCGTTGA |
| Protein Sequence | MGSLISTCLYSSKGNMHARITDSSTWYPQLGQHISIQTYRELGRAPTSSPMSTRAETHWNGGNSRSTVEVLEEVANRLTTHMPRR |
| NCBI Accession | YP_009508004.1 |
|---|---|
| Location | 426-1196 |
| Protein Name | NSP |
| Coding Region | ATGTATTCTTTTAAGAATAAACGTGGTTTCGTCTTTAATCAGCGTCGATTTCATTCAAGGAACATTGTGTCTAATCGATCAACTAGATTTAAGAAATCTGATGGGAAACGTCGACTGGGTAATTCAGCTAAGTCCAATGATGAGCCTAAGATGTCAGCCCAGTGCATACATGAGAATCAATATAGTCCAGAGTTTGTTATGTCAAATAACTCGGCTATATCTACATTTATCAGTTATCCTAACCTGGGAAAGACAGAACCCAGTCGAAGTAGGTCCTATATCAAGTTGAAACGACTCCGTTTCAAAGGGACTGTTAAGATTGAGCGTGTTCAATCTGATGTTAACATGGATGATTCTGTCCCCAAGTTGGAAGGTGTCTTCTCACTCGTTGTAGTTGTGGATCGTAAACCACATTTGGGTCAGACTGGTTGTTTGCATACATTCGACGAACTATTTGGTGCATTGATCCACAGTCATGGTAACCTCAGCATAACTCCTTCTCTGAAAGACCGTTTCTATATTAGACACGTGTTCAAACGTGTGTTGTCTGTGGATAAGGAAACGACGATGTTTGACGTGGAAGGGTGTACATCGCTGTCTAATAGACGATTCAATTGTTGGGCATCGTTCAAAGATCTTGACCATGACTCGTGCAAGGGTGTTTATGATAATATTAGCAAGAATGCTCTATTAGTGTATTATTGTTGGATGTCAGACACTATGTCTAAAGCATCTAGTTTTGTATCGTTCGATCTCGATTATGTTGGGTGA |
| Protein Sequence | MYSFKNKRGFVFNQRRFHSRNIVSNRSTRFKKSDGKRRLGNSAKSNDEPKMSAQCIHENQYSPEFVMSNNSAISTFISYPNLGKTEPSRSRSYIKLKRLRFKGTVKIERVQSDVNMDDSVPKLEGVFSLVVVVDRKPHLGQTGCLHTFDELFGALIHSHGNLSITPSLKDRFYIRHVFKRVLSVDKETTMFDVEGCTSLSNRRFNCWASFKDLDHDSCKGVYDNISKNALLVYYCWMSDTMSKASSFVSFDLDYVG |
| NCBI Accession | YP_009508005.1 |
|---|---|
| Location | 1247-2128 |
| Protein Name | MP |
| Coding Region | ATGGATTCTCAGCTAGTAAATCCCCCATGTGCCTTCAACTACATAGAGTCCCACAGAGATGAATATCAACTCTGCCACGACTTAACTGAGATAATCTTGCAATTCCCTTCGACGGCGGCACAAATAAGCGCTAGACTTAGCAGAAGCTGTATGAAGATCGACCATTGTGTCATAGAGTACAGGCAACAGGTCCCAATTAACGCTTCTGGGACAGTAATCGTGGAGATCCATGACAAGAGGATGACAGACAATGAGTCATTACAGGCGTCATGGACTTTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCAGCTTCCTTCTTCTCTCTAAAAGACCCAATTCCTTGGAAACTCTATTACAGAGTTTCTGATACGAATGTTCATCAGAGAACCCACTTCGCCAAGTTCAAGGGGAAGCTGAAATTGTCCACAGCCAAACACTCGGTGGATATCCCGTTTCGGGCACCGACGGTCAAGATCCTGTCCAAACAGTTTACAGACAAAGATGTGGACTTCTCGCATGTGGACTATGGGAAATGGGAGAGGAAGCCCATACGATGCGCATCCATGTCGAGAGTAGGCTTAAGAGGCCCAATTGAAATAAGGCCTGGTGAATCATGGGCTTCCAGGAGTACATTGGGAATGGGCCATTCAGATGTGGACTCAGAAGTAGAAAACGAACTGCATCCATACAGACATATGAGCAGGCTAGGCACAACAGTTCTGGACCCGGGAGAGTCTGCTTCAGTATTACGGGCCCAGAGAGCGGAATCCAACATCACGATGTCATTGGGCCAATTAAATGAATTAGTCAGGACAACAGTCCAAGAGTGTATTAATAGTAATTGTAGGGCTTCTCAGCCCAAATCTTTGCAATAG |
| Protein Sequence | MDSQLVNPPCAFNYIESHRDEYQLCHDLTEIILQFPSTAAQISARLSRSCMKIDHCVIEYRQQVPINASGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKPIRCASMSRVGLRGPIEIRPGESWASRSTLGMGHSDVDSEVENELHPYRHMSRLGTTVLDPGESASVLRAQRAESNITMSLGQLNELVRTTVQECINSNCRASQPKSLQ |
References More References in PubMed
| 1 |
Graham AP, et al. Virus Genes. 2010 Apr;40(2):256-66. doi: 10.1007/s11262-009-0430-6. Epub 2009 Dec 19. PMID: 20024609 |
|---|---|
| 2 |
First report of the complete sequence of Sida golden yellow vein virus from Jamaica. Stewart CS, et al. Arch Virol. 2011 Aug;156(8):1481-4. doi: 10.1007/s00705-011-1030-z. Epub 2011 May 29. PMID: 21625977 |
| 3 |
Stewart C, et al. Arch Virol. 2014 Sep;159(9):2509-12. doi: 10.1007/s00705-014-2063-x. Epub 2014 Apr 1. PMID: 24687859 |