Malvastrum bright yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_001777305.1 |
| Isolate |
USA |
| Release date |
2016/10/19 |
| Submitter |
Alabi,O.J., Villegas,C., Gregg,L., Murray,K.D., Gregg,L.L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
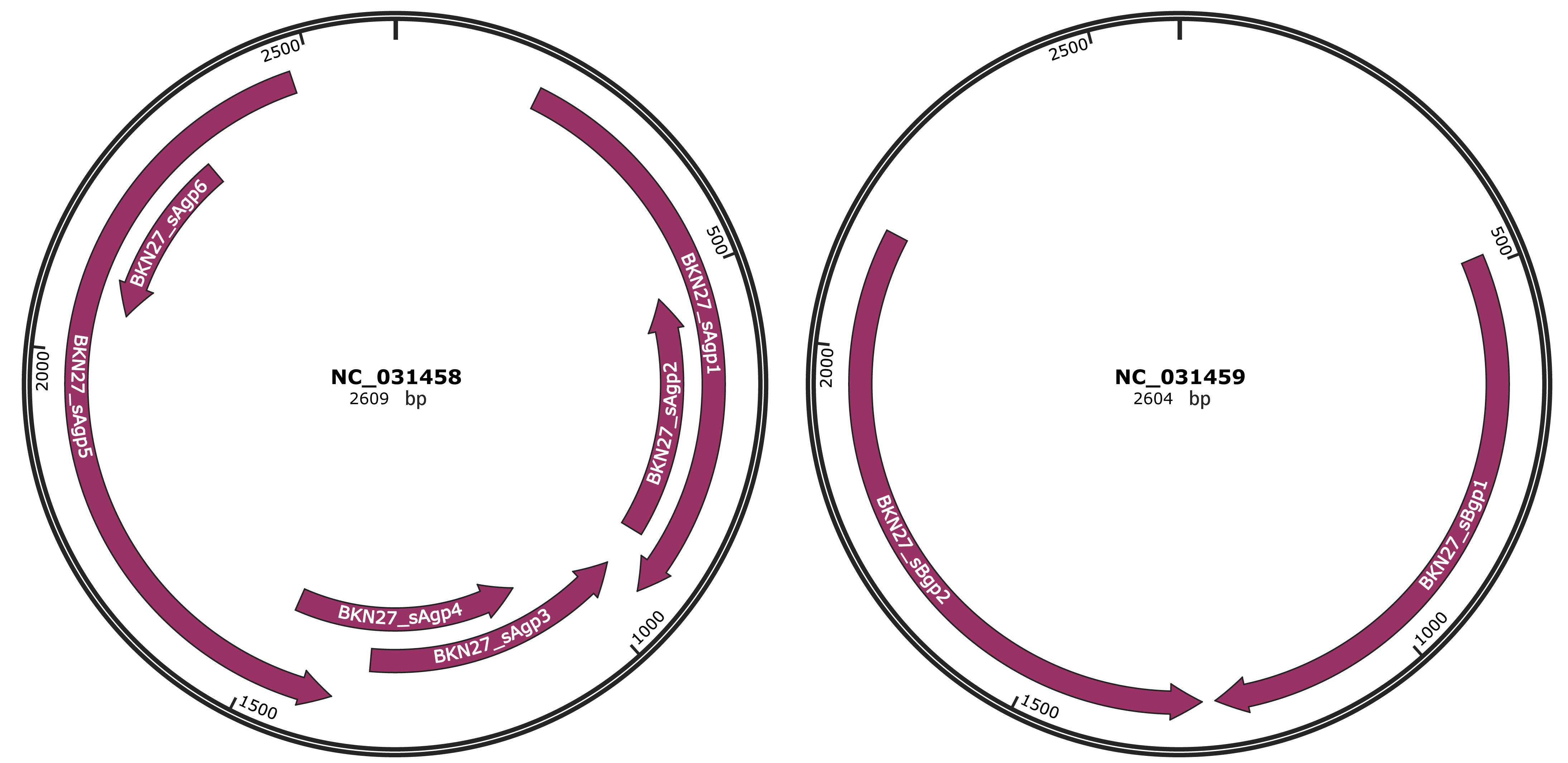
JBrowse
Genome
ACCGGATGGCCGCGCGATTTTTCCCCCCCCTTTAGCTGGCGCTCCTCTTTAATTTGAGTTAAAGCGTATCGCTTTCGCATCGTCCAATGATATTGCGCCTGACGAGTCTAGTTATTTGCAACAACTTGGTCCCTAAGTTGTTAGTGCGTTATAAATTAAAGAGGCTTTGGCCCACTAAATTTAATTCAAAATGCCTAAGCGCGACCTCCCATGGCGCTCGATCGCGGGAACGTCAAAGGTTAGTCGCAATGCTAACTATTCGCCTCGTGCAGGAAGTGGGCCAAAAGTTAACAGGGCCGCTGAATGGGTTAACAGGCCTATGTATAGGAAGCCCAGGATATACAGGCTCATGAGAAGCCCTGATGTCCCAAAGGGGTGTGAAGGCCCGTGTAAGGTCCAGTCTTATGAACAGCGTCATGATATCTCTCATGTGGGTAAGGTTATGTGTGTGTCTGATATCACACGTGGTAATGGGCTTACCCATCGAGTTGGTAAGCGTTTCTGTGTTAAGTCTATGTATATTCTAGGTAAGGTGTGGATGGATGATAATATTAAGTTGAAGAACCACACGAACAGTGTGATGTTCTGGTTGGTCAGGGATCGAAGACCCTATGGTAATCCTATGGACTTTGGACAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCCACGATCAAGAACGATCTTCGAGATCGTTTCCAGGTCATGCACAAATTCTATGCCAAAGTCACAGGTGGTCAATATGCAAGCAACGAGCAGGCTATAGTTAGGCGTTTTTGGAAGCTGAACAACCACGTCGTGTATAACCACCAGGAAGCAGGGAAATACGATAACCATACTGAGAACGCCCTTTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACTTTGAAGATTCGGATCTATTTCTACGATTCGATTCAAAATTAATAAAATTTGAATTTTATTGAATGATTTTCAAGTACATAATTAACATACGATCTGTCTGTTGCGAATCGAACAGCTCTAATTACATTGTTTATTGAAATCACACCTAACTGATCTAAATACATAATAACCAAATGTCTAAATCTAGCTAAATAGGTCGACCCAGAAGCTGTCATCGATGTCGTCCAGACTTGGAAGTTCAGAAATGCTTTGTGGAGATCCAACGCTCTCCTCAGGTTGTGGTTGAACCGTATTTGTACATGGTACACTCTGGTCCTCGTGTATAGATTGTCTTTTACCCGGTAAATCTTGAAATAGAGGGGATTTTCTATCTCCCAGATATACACGCCATTCTCTGCCTGACGTACAGTGATGAGCTCCCCTGTGCGTGAATCCATGTCCCGTACAGCCTATGTGGAAGTAGATGGAGCAACCGCAATCCAGATCAATCCGCCGTCTCCTGATGGCCCTCTTCTTGGCTTGCCTGTGTGCTGTCTTGATAGAGGGCGGATGTGAGGGTGACGAAGACCACATTCTTGATGGTCCAGTTCCTGAGTGCTGTGTTTTCCTCTTTGTTCAGGAAATCTTTATAGCTGGCACCCTCACCAGGATTGCAAAGCACGATTGATGGGATTCCCCCTTTAATTTGAACTGGCTTTCCGTATTTGCAATTTGACTGCCAGTCCTTCTGGGCCCCCAGAAGTTCTTTCCAGTGCTTTAGCTTTAGATATTGCGGTGCGACGTCATCAATGACGTTATACTCCACTTCGTTCGAATAGACTCTTGGGTTGAAGTCTAGATGTCCACTAAGGTAATTATGTGGGCCTAGGGCACGAGCCCACATCGTCTTCCCTGTCCTCGAGTCACCTTCTACTATGATACTCACTGGTCTCTCCGGCCGCGCAGCGGAACTCCTTCCAAAATATTCGTCCGCCCATGCTTGCATCTCGTCTGGAACTCTAGTGAACGAGGAGAGTTGAAACGGAGGAACCCATTGTTCCGGAGCCTTAGCGAATATTTTCTCTAGGTTGGAGCGTATGTTATGGTTTTGCAGCACAAAGTCCTTTGGCTGCTCCTCCTTTAAAACCGCCATGGCAGCTTGAACAGATCCAGCATTCAACGCCTTGGCATATGAATCGTTAGCCGATTGTTGACCTCCTCTAGCAGATCTGCCGTCGATTTGGAATTCTCCCCAGTCAACTGTATCTCCGTCCTTCTCGATGTAGGACTTGACGTCGGAGCTGGATTTAGCTCCCTGTATGTTCGGATGGAAATGTGTTGACCTGGTTGGGGAGACCAAATCGAAGAATCTGTAATTCGTGCACTGGTACTTGCCTTCGAATTGGATGAGAACGTGGAGATGAGGCTCCCCATTCTTATGGAATTCCCTGCATATTCTGATGAACTTCTGGTTAACCGGTGTTTTTATGTTTAGTAACTGGGAAAGTGCTTCTTCTTTGCTAAGAGAGCACTCTGGATATGTGAGGAAATAGTTTTTTGCTGAGACTTTAAACTTTTTAACCGATGGCATTTTTGTAATAAGAAGGGTGTACCCCGATTGAGCTCTCTCTCAAACTGCGCTACTAATTGGGGTAATGGGGTATTATATATACTAGAAGTCTCTATTACGGATTAGCGACACGTGGCGGCCATCCGCTATAATATT
ACCGGATGGCCGCGCGATTTTTCCCCCCCTCCACGTGGCGCGCATCGGTGGCTCGTGTTCCTCCAGTTCCCTCCGCACACGCGCCCACGCGCACTACCCCTCCCCTCTTGGCGCTCTCCTGGTGGCCCCCCTCAACGTGGCGTCTCTCAAGTGGAGCTCTGGCGCTACTTTGGGCCATATTGTCAGTGGGTATCGTTTGACTAACGCTTTAATTCGAATTAAAGCTTAAAGCTACATTTGTTTGTCGCGCGATTACATTTGATTTGTGAACGATTTTATCGCGCTACCTCATGATGGCCCACTGTACTTGTAGGTAGACGTGGCTGATTCTAGACCGTGTTGCCGAGTCTATTTAAGATTATTTTGAATCATCCTTTGTTATATATTGGGGCCGACTAACAAAATTGATCAGGAAAGACTCGGCTAGAACTACGTGTATATCATTGTTTATAAGCCCGGTTCGACTATTTGATAAACCCTAATTATGTATTCTCCAAGGTTTAAGCGTGGTTCTTCCTTCGTTGCACGTCGTTATTATCCTCGAAACAATGTGTTTAAGCGTTCAACCATCTCGAAGCGAGATGATGGGAAACGTCGATCAGGGAAGTCAACTAAACCCATTGATGAGCCCAAAATGACAGCCCAACGTATACACGAGAACCAGTTCGGCCCGGAGTTTGTTATGGCCCATAATTCAGCCATATCCACGTTCATCAGTTTCCCTGGTTTGGGTAAGTCTCAACCGAACCGGAGCAGGTCTTATATCAAGTTGAAACGGCTTCGTTTCAAGGGGACGGTCAAGCTGGAACGTGTTCAGCCGGATATGAACATGGACGGTTCGAACTCTAAGGTCGACGGAGTGTTCTCTTTAGTCATTGTTGTGGATCGTAAACCCCACCTTGGTTCGTCTGGGTGTTTGCATACATTCGATGAACTGTTTGGTGCAAGGATCCACAGTCACGGTAACCTCAACATAACCCCTTCTTTGAAGGACCGTTACTATATAAGACACGTGTTCAAACGTGTGTTGTCTGTGGAGAAGGATACGATGATGGTAGACGTGGAAGGGTCAACTTGGCTCTCTAATAGGCGTTTTAATTGTTGGTCCACGTTTAAGGATTTAGAACATGATTCATGTAACGGTGTTTATGGCAATATTAGCAAGAACGCCCTATTAGTTTATTATTGTTGGATGTCTGACACGATGTCTAAGGCGTCATGCTTTGTATCGTTTGACCTTGATTATGTTGGTTGATCAATAAAACAATATTTTCATTGCAAAGATTTGGGCTCTGAAGCCTTACAATTACTATTAATACATTCTTGGACTGTAGATCTAACTAGCTCGTTTAATTGTCCCAATGATATTGTTATGTTCGATTCTGCTCTCTGGGTTCCCACAACTGAAGCAGACTCTCCCGGGTCCAAAACGCTGGACCCCAGCCTACTTAGGTGTCTGTACGGGTGCTGTTCGTTTTGTATCTCTGAGTCCGCATCTGATTGGGCTATTCCTATTGCACTCCTGGAAGCCCATGATTCACCAGGCCTTATTTCAATTGGACCTCTGAGCCCAAGTCTCGACATGGACGCGCATCTTATGGGCTTCCTTTCCCATTTGCCATAGTCGACGTGGGAGAAGTCTATATCTTTGTCGGTGAACTGTTTTGACAGTATCTTTACCGTCGGTGCCCGGAAGGGTATATCCACTGAGTGTTTCGCCGTCGACAATTTCAGTTTCCCCTTGAATTTCGCGAAATGGGTCCTCTGATGAACATTCGTATCGCAAACTCTGTAGTAGAGTTTCCACGGAATTGGGTCTTTGAGCGAAAAGAAAGATGCCGAGAAATAGTGGAGATCTATGTTGCACCTGATCGGAAAAGTCCATGACGCCTGTAACGACTCGTTATCCGTCATCCTTTTGTCGTGGATCTCCACAATCACCGTCCCTGTGGCGTTAATCGGAACTTGTTGTCTGTATTCTATGACGCAATGGTCTATCTTCATGCAACTCCGACTTATCCTCGCCGTGAACTGTGACGCCGTTGACGGAAACTGCAATACTATCTCGTTCAGGTCATGCGAAAGCTGATATTCGTCGCGATGTGACTCTATGTAGTTGAATGCGCTAGGAGGAAACGCTAACTGAGATTCCATCTGAGAAAGAACGGCCGCGCAGCGGCACCAATTCTTGAATATGAACTCCTGAAGAAGAAATTAGGGTTTGTTTGTGAAAACAGTCGATGAACTATCGTCGACGAAGAAGAATGTTTCTGGGTATCCCAGAAATTAACCCAAGAAATGAAAAACAGTTGTTTGATATCTTATGATTATGTGAATTGTGTCTATGAAATAGAAGAAATTCGTTAGTTGAATCGGATATGAACATGGGTTAGACGAGGAAAAGAGAGCACTCTGGATATGTGAGGAAATAGTTTTTTGCTGAGACTTTAAACTTTTAACCGATGGCATTTTTGTAATAAGAAGGGTGTACCCCGATTGAGCTCTCTCTCAAACTGCGCTACTAATTGGGGTAATGGGGTATTATATATACTAGAAGTCTCTATTACGGATTAGCGACACGTGGCGGCCATCCGCTATAATATT
Gene Information
|
NCBI Accession
|
YP_009310090.1
|
|
Location
|
191-946 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGACCTCCCATGGCGCTCGATCGCGGGAACGTCAAAGGTTAGTCGCAATGCTAACTATTCGCCTCGTGCAGGAAGTGGGCCAAAAGTTAACAGGGCCGCTGAATGGGTTAACAGGCCTATGTATAGGAAGCCCAGGATATACAGGCTCATGAGAAGCCCTGATGTCCCAAAGGGGTGTGAAGGCCCGTGTAAGGTCCAGTCTTATGAACAGCGTCATGATATCTCTCATGTGGGTAAGGTTATGTGTGTGTCTGATATCACACGTGGTAATGGGCTTACCCATCGAGTTGGTAAGCGTTTCTGTGTTAAGTCTATGTATATTCTAGGTAAGGTGTGGATGGATGATAATATTAAGTTGAAGAACCACACGAACAGTGTGATGTTCTGGTTGGTCAGGGATCGAAGACCCTATGGTAATCCTATGGACTTTGGACAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCCACGATCAAGAACGATCTTCGAGATCGTTTCCAGGTCATGCACAAATTCTATGCCAAAGTCACAGGTGGTCAATATGCAAGCAACGAGCAGGCTATAGTTAGGCGTTTTTGGAAGCTGAACAACCACGTCGTGTATAACCACCAGGAAGCAGGGAAATACGATAACCATACTGAGAACGCCCTTTTGTTGTATATGGCATGTACTCATGCCTCTAACCCTGTGTATGCAACTTTGAAGATTCGGATCTATTTCTACGATTCGATTCAAAATTAA |
|
Protein Sequence
|
MPKRDLPWRSIAGTSKVSRNANYSPRAGSGPKVNRAAEWVNRPMYRKPRIYRLMRSPDVPKGCEGPCKVQSYEQRHDISHVGKVMCVSDITRGNGLTHRVGKRFCVKSMYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGNPMDFGQVFNMFDNEPSTATIKNDLRDRFQVMHKFYAKVTGGQYASNEQAIVRRFWKLNNHVVYNHQEAGKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSIQN |
|
NCBI Accession
|
YP_009310091.1
|
|
Location
|
524-880 |
|
Protein Name
|
C5 protein |
|
Coding Region
|
ATGAGTACATGCCATATACAACAAAAGGGCGTTCTCAGTATGGTTATCGTATTTCCCTGCTTCCTGGTGGTTATACACGACGTGGTTGTTCAGCTTCCAAAAACGCCTAACTATAGCCTGCTCGTTGCTTGCATATTGACCACCTGTGACTTTGGCATAGAATTTGTGCATGACCTGGAAACGATCTCGAAGATCGTTCTTGATCGTGGCAGTACTGGGCTCGTTGTCGAACATGTTGAACACCTGTCCAAAGTCCATAGGATTACCATAGGGTCTTCGATCCCTGACCAACCAGAACATCACACTGTTCGTGTGGTTCTTCAACTTAATATTATCATCCATCCACACCTTACCTAG |
|
Protein Sequence
|
MSTCHIQQKGVLSMVIVFPCFLVVIHDVVVQLPKTPNYSLLVACILTTCDFGIEFVHDLETISKIVLDRGSTGLVVEHVEHLSKVHRITIGSSIPDQPEHHTVRVVLQLNIIIHPHLT |
|
NCBI Accession
|
YP_009310092.1
|
|
Location
|
943-1341 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAGCTCATCACTGTACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATTTACCGGGTAAAAGACAATCTATACACGAGGACCAGAGTGTACCATGTACAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAAGCATTTCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGACCTATTTAGCTAGATTTAGACATTTGGTTATTATGTATTTAGATCAGTTAGGTGTGATTTCAATAAACAATGTAATTAGAGCTGTTCGATTCGCAACAGACAGATCGTATGTTAATTATGTACTTGAAAATCATTCAATAAAATTCAAATTTTATTAA |
|
Protein Sequence
|
MDSRTGELITVRQAENGVYIWEIENPLYFKIYRVKDNLYTRTRVYHVQIRFNHNLRRALDLHKAFLNFQVWTTSMTASGSTYLARFRHLVIMYLDQLGVISINNVIRAVRFATDRSYVNYVLENHSIKFKFY |
|
NCBI Accession
|
YP_009310093.1
|
|
Location
|
1088-1477 |
|
Protein Name
|
transcriptional activator protein |
|
Coding Region
|
ATGTGGTCTTCGTCACCCTCACATCCGCCCTCTATCAAGACAGCACACAGGCAAGCCAAGAAGAGGGCCATCAGGAGACGGCGGATTGATCTGGATTGCGGTTGCTCCATCTACTTCCACATAGGCTGTACGGGACATGGATTCACGCACAGGGGAGCTCATCACTGTACGTCAGGCAGAGAATGGCGTGTATATCTGGGAGATAGAAAATCCCCTCTATTTCAAGATTTACCGGGTAAAAGACAATCTATACACGAGGACCAGAGTGTACCATGTACAAATACGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAAGCATTTCTGAACTTCCAAGTCTGGACGACATCGATGACAGCTTCTGGGTCGACCTATTTAGCTAG |
|
Protein Sequence
|
MWSSSPSHPPSIKTAHRQAKKRAIRRRRIDLDCGCSIYFHIGCTGHGFTHRGAHHCTSGREWRVYLGDRKSPLFQDLPGKRQSIHEDQSVPCTNTVQPQPEESVGSPQSISELPSLDDIDDSFWVDLFS |
|
NCBI Accession
|
YP_009310094.1
|
|
Location
|
1389-2474 |
|
Protein Name
|
replication-associated protein |
|
Coding Region
|
ATGCCATCGGTTAAAAAGTTTAAAGTCTCAGCAAAAAACTATTTCCTCACATATCCAGAGTGCTCTCTTAGCAAAGAAGAAGCACTTTCCCAGTTACTAAACATAAAAACACCGGTTAACCAGAAGTTCATCAGAATATGCAGGGAATTCCATAAGAATGGGGAGCCTCATCTCCACGTTCTCATCCAATTCGAAGGCAAGTACCAGTGCACGAATTACAGATTCTTCGATTTGGTCTCCCCAACCAGGTCAACACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGAGAAGGACGGAGATACAGTTGACTGGGGAGAATTCCAAATCGACGGCAGATCTGCTAGAGGAGGTCAACAATCGGCTAACGATTCATATGCCAAGGCGTTGAATGCTGGATCTGTTCAAGCTGCCATGGCGGTTTTAAAGGAGGAGCAGCCAAAGGACTTTGTGCTGCAAAACCATAACATACGCTCCAACCTAGAGAAAATATTCGCTAAGGCTCCGGAACAATGGGTTCCTCCGTTTCAACTCTCCTCGTTCACTAGAGTTCCAGACGAGATGCAAGCATGGGCGGACGAATATTTTGGAAGGAGTTCCGCTGCGCGGCCGGAGAGACCAGTGAGTATCATAGTAGAAGGTGACTCGAGGACAGGGAAGACGATGTGGGCTCGTGCCCTAGGCCCACATAATTACCTTAGTGGACATCTAGACTTCAACCCAAGAGTCTATTCGAACGAAGTGGAGTATAACGTCATTGATGACGTCGCACCGCAATATCTAAAGCTAAAGCACTGGAAAGAACTTCTGGGGGCCCAGAAGGACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGGGGAATCCCATCAATCGTGCTTTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTGAACAAAGAGGAAAACACAGCACTCAGGAACTGGACCATCAAGAATGTGGTCTTCGTCACCCTCACATCCGCCCTCTATCAAGACAGCACACAGGCAAGCCAAGAAGAGGGCCATCAGGAGACGGCGGATTGA |
|
Protein Sequence
|
MPSVKKFKVSAKNYFLTYPECSLSKEEALSQLLNIKTPVNQKFIRICREFHKNGEPHLHVLIQFEGKYQCTNYRFFDLVSPTRSTHFHPNIQGAKSSSDVKSYIEKDGDTVDWGEFQIDGRSARGGQQSANDSYAKALNAGSVQAAMAVLKEEQPKDFVLQNHNIRSNLEKIFAKAPEQWVPPFQLSSFTRVPDEMQAWADEYFGRSSAARPERPVSIIVEGDSRTGKTMWARALGPHNYLSGHLDFNPRVYSNEVEYNVIDDVAPQYLKLKHWKELLGAQKDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENTALRNWTIKNVVFVTLTSALYQDSTQASQEEGHQETAD |
|
NCBI Accession
|
YP_009310095.1
|
|
Location
|
2060-2317 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGGAGCCTCATCTCCACGTTCTCATCCAATTCGAAGGCAAGTACCAGTGCACGAATTACAGATTCTTCGATTTGGTCTCCCCAACCAGGTCAACACATTTCCATCCGAACATACAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGAGAAGGACGGAGATACAGTTGACTGGGGAGAATTCCAAATCGACGGCAGATCTGCTAGAGGAGGTCAACAATCGGCTAACGATTCATATGCCAAGGCGTTGA |
|
Protein Sequence
|
MGSLISTFSSNSKASTSARITDSSIWSPQPGQHISIRTYRELNPAPTSSPTSRRTEIQLTGENSKSTADLLEEVNNRLTIHMPRR |
|
NCBI Accession
|
YP_009310096.1
|
|
Location
|
485-1255 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATTCTCCAAGGTTTAAGCGTGGTTCTTCCTTCGTTGCACGTCGTTATTATCCTCGAAACAATGTGTTTAAGCGTTCAACCATCTCGAAGCGAGATGATGGGAAACGTCGATCAGGGAAGTCAACTAAACCCATTGATGAGCCCAAAATGACAGCCCAACGTATACACGAGAACCAGTTCGGCCCGGAGTTTGTTATGGCCCATAATTCAGCCATATCCACGTTCATCAGTTTCCCTGGTTTGGGTAAGTCTCAACCGAACCGGAGCAGGTCTTATATCAAGTTGAAACGGCTTCGTTTCAAGGGGACGGTCAAGCTGGAACGTGTTCAGCCGGATATGAACATGGACGGTTCGAACTCTAAGGTCGACGGAGTGTTCTCTTTAGTCATTGTTGTGGATCGTAAACCCCACCTTGGTTCGTCTGGGTGTTTGCATACATTCGATGAACTGTTTGGTGCAAGGATCCACAGTCACGGTAACCTCAACATAACCCCTTCTTTGAAGGACCGTTACTATATAAGACACGTGTTCAAACGTGTGTTGTCTGTGGAGAAGGATACGATGATGGTAGACGTGGAAGGGTCAACTTGGCTCTCTAATAGGCGTTTTAATTGTTGGTCCACGTTTAAGGATTTAGAACATGATTCATGTAACGGTGTTTATGGCAATATTAGCAAGAACGCCCTATTAGTTTATTATTGTTGGATGTCTGACACGATGTCTAAGGCGTCATGCTTTGTATCGTTTGACCTTGATTATGTTGGTTGA |
|
Protein Sequence
|
MYSPRFKRGSSFVARRYYPRNNVFKRSTISKRDDGKRRSGKSTKPIDEPKMTAQRIHENQFGPEFVMAHNSAISTFISFPGLGKSQPNRSRSYIKLKRLRFKGTVKLERVQPDMNMDGSNSKVDGVFSLVIVVDRKPHLGSSGCLHTFDELFGARIHSHGNLNITPSLKDRYYIRHVFKRVLSVEKDTMMVDVEGSTWLSNRRFNCWSTFKDLEHDSCNGVYGNISKNALLVYYCWMSDTMSKASCFVSFDLDYVG |
|
NCBI Accession
|
YP_009310097.1
|
|
Location
|
1273-2154 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGAATCTCAGTTAGCGTTTCCTCCTAGCGCATTCAACTACATAGAGTCACATCGCGACGAATATCAGCTTTCGCATGACCTGAACGAGATAGTATTGCAGTTTCCGTCAACGGCGTCACAGTTCACGGCGAGGATAAGTCGGAGTTGCATGAAGATAGACCATTGCGTCATAGAATACAGACAACAAGTTCCGATTAACGCCACAGGGACGGTGATTGTGGAGATCCACGACAAAAGGATGACGGATAACGAGTCGTTACAGGCGTCATGGACTTTTCCGATCAGGTGCAACATAGATCTCCACTATTTCTCGGCATCTTTCTTTTCGCTCAAAGACCCAATTCCGTGGAAACTCTACTACAGAGTTTGCGATACGAATGTTCATCAGAGGACCCATTTCGCGAAATTCAAGGGGAAACTGAAATTGTCGACGGCGAAACACTCAGTGGATATACCCTTCCGGGCACCGACGGTAAAGATACTGTCAAAACAGTTCACCGACAAAGATATAGACTTCTCCCACGTCGACTATGGCAAATGGGAAAGGAAGCCCATAAGATGCGCGTCCATGTCGAGACTTGGGCTCAGAGGTCCAATTGAAATAAGGCCTGGTGAATCATGGGCTTCCAGGAGTGCAATAGGAATAGCCCAATCAGATGCGGACTCAGAGATACAAAACGAACAGCACCCGTACAGACACCTAAGTAGGCTGGGGTCCAGCGTTTTGGACCCGGGAGAGTCTGCTTCAGTTGTGGGAACCCAGAGAGCAGAATCGAACATAACAATATCATTGGGACAATTAAACGAGCTAGTTAGATCTACAGTCCAAGAATGTATTAATAGTAATTGTAAGGCTTCAGAGCCCAAATCTTTGCAATGA |
|
Protein Sequence
|
MESQLAFPPSAFNYIESHRDEYQLSHDLNEIVLQFPSTASQFTARISRSCMKIDHCVIEYRQQVPINATGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDIDFSHVDYGKWERKPIRCASMSRLGLRGPIEIRPGESWASRSAIGIAQSDADSEIQNEQHPYRHLSRLGSSVLDPGESASVVGTQRAESNITISLGQLNELVRSTVQECINSNCKASEPKSLQ |