Macroptilium mosaic Puerto Rico virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000846245.1 |
| Isolate | Puerto Rico |
| Release date | 2015/2/12 |
| Submitter | Brown,J.K., Idris,A.M., Hiebert,E., Bird,J. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
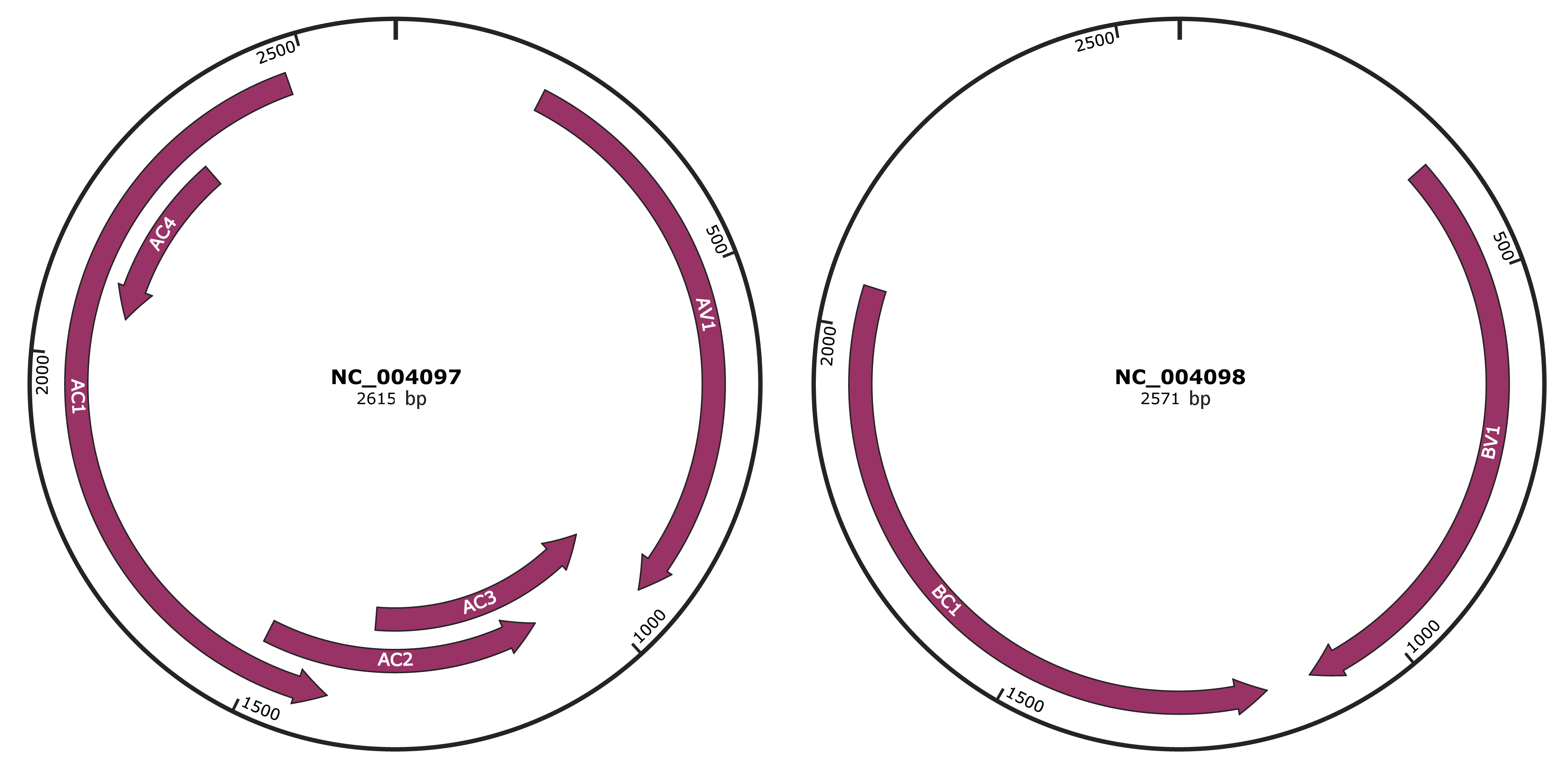
JBrowse
Genome
NC_004097
ACCGGATGGCCGCGCTTTCCCTTCCTTTCCGTACATCGCATGGAATGCTTTAATTTGAATTAAAGATGACTTTGTTTGCGTTGTCCAATCATGTGTGTGCTGGAAAGTTAAATTATTTAACTTGGTCTTTAAGTTTATGACTTTTGGTTATAAATTCAAATTAAATGTACCTGTTGTGACAGTGCTTTAATTCGACATGCCTAAGCGGGATGCCCCGTGGCGCTCTTCTGCGGGAACCTCTAAGGTTAGCCGTAATTTGAATTATTCTCCCGGGGGAGGCCCAAAATCCAACAGGGCCAATGCATGGGTTAATAGGCCCATGTACAGGAAGCCCAGGATATATCGGATGTACAGGACTCCCGATGTTCCTAGAGGCTGTGAAGGACCCTGTAAAATCCAGTCGTTTGAACAACGCCATGATGTGTCTCATATTGGTAAGGTTATGTGTATATCTGATGTTACACGTGGTAACGGTATTACTCATCGCGTTGGCAAACGTTTCTGTGTTAAGTCTGTTTACATTTTAGGCAAAGTTTGGATGGACGACAACATCAAGTTGAAGAATCATACCAACAGTGTAATGTTTTGGTTGGTTAGGGATCGAAGACCATATGGCACTCCTATGGAATTTGGTCAAGTATTTAATATGTTTGATAATGAGCCTAGCACTGCTACTATTAAGAACGATTTACGAGATCGTTTCCAGGTCATGCACAAGTTTTATTCAAAGGTTACAGGTGGACAATATGCAAGTAATGAACAGTCGCTGGTTAAGCGATTTTGGAAGGTTAACAACCATGTTGTGTATAATCATCAAGAAGCTGCTAAGTACGAGAACCATACTGAGAACGCATTATTGTTGTATATGGCATGTACACATGCTTCTAATCCTGTATATGCTACTTTGAAAATTCGGATATATTTTTACGATTCGATAATGAATTAATAAAATTTGAATTTTATTTCATGATTTTCAAGCACGTCATTTACATAACTTCTGTCCGTTGCATATGAGACAGCTTTGATTACATTGTTAATTGAAATAACTCCTAAATTATCTAAATAAGACAGTACAAGGTATTTAAATCTATTTAAATAAATCTGCCCAGAAGCTGTCGTCAATGTCGTCCAGACTTGGAAATTGAAGAAGGCTTTGTGGAGAGCCAACGCTTTCCTCAGGTTGTGGTTGGCTCGGATTTGAATGTCGAACACCGTGCTGTTCGTGTACATTGGCTTCTCCACGTTGATTATTTTGAAATAGAGGGGATTTATAATCTCCCAAATAAAAACGCCATTCGTTGCTTGAACTGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGATTTGCGCAACTAATATGAATGTATATTGAACAGCCACACTCTAGATCTAACCTTCTACGTCGAGTCTGTCTCTTGGCGTGACGATGACGCGGTTTGATTGAAGGTGGAGTAGAGTGGTTCCTCAATGGAGACGTAGATGGCGTTTTTCTGTGCCCAGTCATTGAGTGATTTGTTTTTCTCTTCGCTGAGATACTCTTTATATGATGAATGGGGGCCAGGATTGCATAGGAAGATAGTGGGAATTCCTCCTTTAATTTGAATTGGCTTTCCGTATTTGCAGTTTGATTGCCAATCACGTTGGGCCCCCATGAACTCTTTAAAGTGTTTCAGATAATGCGGATCAACGTCATCTATGACGTTATACCATGCATGATTGGAGTAAATTCTCGGGTTGAGATCGATATGACCACATAGGTAATTGTGAGGACCCAGACTTCGGGCCCATATTGTCTTGCCTGTTCTTGATGGTCCTTCAACGATGATTGATATAGGTCTCAACGGCCGCGCAGCGGAATCGGAAATATTTTCGTTAACCCAGTCCGACATAATTAAAGGGACATTGTTGAAAGTGGATAACTGAAATGGAGGAACCCACGGTTCCGTTGGTGGTGTGAATATTTTCTCCAGATTAGAACGGATGTTGTGATATTGGACAACGAAATCTTTTGGCTGTTCTTCTTTTAATACCGTCATTGCAGCTTCAATACAATCTGCATTTAACGCTTTTGCATATGAGTCGTTTGCGGATTGTTGTCCTCCTCTTGCAGATCTACCGTCGATCTGGAATTGGCCCCATTCAATGGTGACTCCATCCTTGTCGATGTATGCTTTAACATCTGAACTTGATTTAACTCCCTGTATGTTCGGATGGAAATGTGTTGACCGTGTTGGGGATACCAAGTCGAATAATCTTTGATTTGTGCAGACGAATTTTCCTTCGAACTGAATAAGCACGTGAAGATGAGGTTGCCCATCTTCGTGTAATTCTTCGCAAATCTTGATGTACTTCTTATCTGTTGGAGTCTGTATATTAAGCAATTGTGAGAGGGTTTCTTCTTTTGAAATAGAACATCGAGGATATGTGAGAAAGTAGTTCTTTGAGCTCACTCTAAATCTCTTTGGTGGTGGCATTTTTGTAAATAAGGCGATGTCACCAATCGAGCTCTCTCAACTCTCTCTATTGTATTGGTGACTGGTGTACAATATATACTAGAGGGCTCTATAGAACTTATTATCCTCTTCGTACACGTGTAGGCCATCCGTTATAATATT
NC_004098
ACCGGATGCCCGCCCGCGTTTCTTTAGTCCGTACGCCGCATTTGCTGGACGATTTTGTCCCTACTTTTGACGAGTTGTTTTGAACCGTTGGATAAAGTTAATCTATCGCGCAATTTGAATTTGCATTATTGACGATGGTACCGATGATTTGGCGTTATGAACAATGTGTTTTTACTCTGACACATTGTCTGTGTATGATGACGTGGTCCAGTTAAAATTCAAATTGGAAGACATGTTAAGTCGTTCATGATTTTTGTTTTTTATATAAATGGGGGAAACTTATTATTTAAAATCATGATATGATATTGAACGAGTGACTTTTATTGATTAATGCTCGATTTGAAGATGTATTCGTCAAGACAAAGACGTCAAACTTCTTACCCACGAGGAGGTTATTCACGTAATCATCTTTCTAAGCGTTCAACTATTGGTAAACGTAATAATGGTAGACGTCGACCTAATAATTTTGGTAAGGTTATTGATGAACCCAAAATGTTGGTTCAACGTATACATGAGAACCAATTTGGACCTGATTTTGTTATGACTCATAATACATCCATTTCTACATTTATTAGTTTTCCTGCTCTTGGTAAGTCTGAGCCCAATCGTTGTAGGCAATATATTAAATTGAAACGTTTACGTTTCAAAGGAACCGTTAAGATCGAGCGTGTTCATGCTGATGTGAATATGGATGGTTTATCACCTAAGATTGAAGGCGTATTCTCTCTGGTTATAGTGGTTGATCGTAGACCTCATCTTACTCCAAGTGGATGCTTACACACCTTTGATGAACTATTTGGTGCAAGAATCCACAGTCACGGTAACTTGGCCATAACATCTTCATTGAAAGACCGTTATTATATTCGCCATGTGTTTAAACGAGTTATATCCGTTGAGAAAGACACGATGATGATCGACGTTGATGGTGGAACGGTCTTGTCTAATAGGCGTTTTAATTTTTGGTCGACGTTTAAAGATCTTGACCATGATTCATGTAACGGTGTATATGACAACATAAGCAAGAACGCCATTTTAGTTTATTATTGTTGGATGTCGGACACAATGTCTAAGGCATCGACATTTGTATCATTTGACCTTGATTATGTTGGCTAAATATGAATGAGAATGCTATTTTGTAGATATAAATGGTGAACAAGCAAAATTTAAAATTTTATTTGAAAGATTTCGGTAGACAAGGAGTACAATTATTATTAATACATTCATGTACTGTTGACCTAACAATTTCGTTTATTTGGGCCATTGATAATGTGATGTTTGATTGGGCTTTGTTTGCACCCACTATCGAAGCCGAATCACCTGGATCTAGTGCGGTGGTTCCTAGCCTGTTGAGATCTCTGTATGGGTGTATTGCGTTCTCTAATTCGGAGTCCGCATCCGTGTGCGATATTCCTATTGTGCTTCTTGAAGCCCAAGACTCACCTGGTCTTAATTCAATTGGGCCCTGAAGCTCATATCTTGATAAAGATGCGGACCTTATTATTTTCCTTTCCCACCTCCCATAGTCTACGTGCGAAAAATCCACGTCCTTATTCGTAAATTGTTTGGAAAGTATTTTTACAGTTGGTGCCCGGAAAGGAATATCCACTGAATGTTTCGCCGTAGACAGTTTGAGTTTGCCTTTGAATTTGGCAAAATGCGTCCTTTGATGAACATTTGTATCACAGACTCTGTAATACAATTTCCATGGAATTGGGTCTTTCAGCGAGAAGAAGGATGAAGAGAAATAGTGGAGATCTATGTTGCATCTTAAAGGAAAAGTCCATGAAGCTTGTAAAGACTCATTGTCTGTCATTCTTCTATCATGAATCTCCACTATTACTGAACCCGTCGCGTTTATAGGAACTTGTTGTCTGTATTCTATAACGCAATGATCGATTTTCATACAGCTACGACTGAGTCTTGCCGATAATTGCGATGTTGTTGAGGGGAATTGAAGAAGGATTTCAGTTAGGTCATGAGACAGTTGATATTCATCCCTGTGAGATTCAATATAATTAAATGCATTTGGAGGATTTGCTAACTGAGAATCCATTTAAAGAATAATGGCCGCGCAGCGGAATGCTAAGAAAATGATAAGCTATTGAAGAAGGATACAAGATTTTCAGAGACAAAGATATGACCAAGAGTTGAAAAAGGATTTTAGGTTTTCAGAATCATAGGAAGATAATAAATCGTCTATGGGTATGCGCTATTTTGAAGAGAGTGATAGTCCTATATATAGGCGCTCCTCAATCTGATTCGGTTTTAATTATGTTGTTCTTTCTGAAAAACTCATTAAAGTGAGAATGAAGTTAAAATGATAAAGTTCCGTTGTATGGTCTTCTAAATTAAAACCGAATTAATCTGAATCAGAAAATATATGCACGACATTGATGGGTTTTATTGTTGGTTTGTTCTTCTGAATGGCATTCGTGTAAATAAGAAGGTGTCACCAAATGAGCGCTCTCACCTCTCTCTATTGTATTGGTGACTGGTGTACAATATATACTAGAGGGTCTTATAGAACTTATTATCCTCTTCATACACGTGTAGGCCATCCGTTATAATATT
Gene Information
| NCBI Accession | NP_671458.1 |
|---|---|
| Location | 197-946 |
| Gene Name | AV1 |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCGTGGCGCTCTTCTGCGGGAACCTCTAAGGTTAGCCGTAATTTGAATTATTCTCCCGGGGGAGGCCCAAAATCCAACAGGGCCAATGCATGGGTTAATAGGCCCATGTACAGGAAGCCCAGGATATATCGGATGTACAGGACTCCCGATGTTCCTAGAGGCTGTGAAGGACCCTGTAAAATCCAGTCGTTTGAACAACGCCATGATGTGTCTCATATTGGTAAGGTTATGTGTATATCTGATGTTACACGTGGTAACGGTATTACTCATCGCGTTGGCAAACGTTTCTGTGTTAAGTCTGTTTACATTTTAGGCAAAGTTTGGATGGACGACAACATCAAGTTGAAGAATCATACCAACAGTGTAATGTTTTGGTTGGTTAGGGATCGAAGACCATATGGCACTCCTATGGAATTTGGTCAAGTATTTAATATGTTTGATAATGAGCCTAGCACTGCTACTATTAAGAACGATTTACGAGATCGTTTCCAGGTCATGCACAAGTTTTATTCAAAGGTTACAGGTGGACAATATGCAAGTAATGAACAGTCGCTGGTTAAGCGATTTTGGAAGGTTAACAACCATGTTGTGTATAATCATCAAGAAGCTGCTAAGTACGAGAACCATACTGAGAACGCATTATTGTTGTATATGGCATGTACACATGCTTCTAATCCTGTATATGCTACTTTGAAAATTCGGATATATTTTTACGATTCGATAATGAATTAA |
| Protein Sequence | MPKRDAPWRSSAGTSKVSRNLNYSPGGGPKSNRANAWVNRPMYRKPRIYRMYRTPDVPRGCEGPCKIQSFEQRHDVSHIGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKVWMDDNIKLKNHTNSVMFWLVRDRRPYGTPMEFGQVFNMFDNEPSTATIKNDLRDRFQVMHKFYSKVTGGQYASNEQSLVKRFWKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
| NCBI Accession | NP_671459.1 |
|---|---|
| Location | 943-1341 |
| Gene Name | AC3 |
| Protein Name | replication enhancer |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCAGTTCAAGCAACGAATGGCGTTTTTATTTGGGAGATTATAAATCCCCTCTATTTCAAAATAATCAACGTGGAGAAGCCAATGTACACGAACAGCACGGTGTTCGACATTCAAATCCGAGCCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAAGCCTTCTTCAATTTCCAAGTCTGGACGACATTGACGACAGCTTCTGGGCAGATTTATTTAAATAGATTTAAATACCTTGTACTGTCTTATTTAGATAATTTAGGAGTTATTTCAATTAACAATGTAATCAAAGCTGTCTCATATGCAACGGACAGAAGTTATGTAAATGACGTGCTTGAAAATCATGAAATAAAATTCAAATTTTATTAA |
| Protein Sequence | MDSRTGEPITAVQATNGVFIWEIINPLYFKIINVEKPMYTNSTVFDIQIRANHNLRKALALHKAFFNFQVWTTLTTASGQIYLNRFKYLVLSYLDNLGVISINNVIKAVSYATDRSYVNDVLENHEIKFKFY |
| NCBI Accession | NP_671460.1 |
|---|---|
| Location | 1088-1504 |
| Gene Name | AC2 |
| Protein Name | transactivation protein Trap |
| Coding Region | ATGACTGGGCACAGAAAAACGCCATCTACGTCTCCATTGAGGAACCACTCTACTCCACCTTCAATCAAACCGCGTCATCGTCACGCCAAGAGACAGACTCGACGTAGAAGGTTAGATCTAGAGTGTGGCTGTTCAATATACATTCATATTAGTTGCGCAAATCATGGATTCACGCACAGGGGAACCCATCACTGCAGTTCAAGCAACGAATGGCGTTTTTATTTGGGAGATTATAAATCCCCTCTATTTCAAAATAATCAACGTGGAGAAGCCAATGTACACGAACAGCACGGTGTTCGACATTCAAATCCGAGCCAACCACAACCTGAGGAAAGCGTTGGCTCTCCACAAAGCCTTCTTCAATTTCCAAGTCTGGACGACATTGACGACAGCTTCTGGGCAGATTTATTTAAATAG |
| Protein Sequence | MTGHRKTPSTSPLRNHSTPPSIKPRHRHAKRQTRRRRLDLECGCSIYIHISCANHGFTHRGTHHCSSSNEWRFYLGDYKSPLFQNNQRGEANVHEQHGVRHSNPSQPQPEESVGSPQSLLQFPSLDDIDDSFWADLFK |
| NCBI Accession | NP_671461.1 |
|---|---|
| Location | 1398-2474 |
| Gene Name | AC1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACCACCAAAGAGATTTAGAGTGAGCTCAAAGAACTACTTTCTCACATATCCTCGATGTTCTATTTCAAAAGAAGAAACCCTCTCACAATTGCTTAATATACAGACTCCAACAGATAAGAAGTACATCAAGATTTGCGAAGAATTACACGAAGATGGGCAACCTCATCTTCACGTGCTTATTCAGTTCGAAGGAAAATTCGTCTGCACAAATCAAAGATTATTCGACTTGGTATCCCCAACACGGTCAACACATTTCCATCCGAACATACAGGGAGTTAAATCAAGTTCAGATGTTAAAGCATACATCGACAAGGATGGAGTCACCATTGAATGGGGCCAATTCCAGATCGACGGTAGATCTGCAAGAGGAGGACAACAATCCGCAAACGACTCATATGCAAAAGCGTTAAATGCAGATTGTATTGAAGCTGCAATGACGGTATTAAAAGAAGAACAGCCAAAAGATTTCGTTGTCCAATATCACAACATCCGTTCTAATCTGGAGAAAATATTCACACCACCAACGGAACCGTGGGTTCCTCCATTTCAGTTATCCACTTTCAACAATGTCCCTTTAATTATGTCGGACTGGGTTAACGAAAATATTTCCGATTCCGCTGCGCGGCCGTTGAGACCTATATCAATCATCGTTGAAGGACCATCAAGAACAGGCAAGACAATATGGGCCCGAAGTCTGGGTCCTCACAATTACCTATGTGGTCATATCGATCTCAACCCGAGAATTTACTCCAATCATGCATGGTATAACGTCATAGATGACGTTGATCCGCATTATCTGAAACACTTTAAAGAGTTCATGGGGGCCCAACGTGATTGGCAATCAAACTGCAAATACGGAAAGCCAATTCAAATTAAAGGAGGAATTCCCACTATCTTCCTATGCAATCCTGGCCCCCATTCATCATATAAAGAGTATCTCAGCGAAGAGAAAAACAAATCACTCAATGACTGGGCACAGAAAAACGCCATCTACGTCTCCATTGAGGAACCACTCTACTCCACCTTCAATCAAACCGCGTCATCGTCACGCCAAGAGACAGACTCGACGTAG |
| Protein Sequence | MPPPKRFRVSSKNYFLTYPRCSISKEETLSQLLNIQTPTDKKYIKICEELHEDGQPHLHVLIQFEGKFVCTNQRLFDLVSPTRSTHFHPNIQGVKSSSDVKAYIDKDGVTIEWGQFQIDGRSARGGQQSANDSYAKALNADCIEAAMTVLKEEQPKDFVVQYHNIRSNLEKIFTPPTEPWVPPFQLSTFNNVPLIMSDWVNENISDSAARPLRPISIIVEGPSRTGKTIWARSLGPHNYLCGHIDLNPRIYSNHAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNCKYGKPIQIKGGIPTIFLCNPGPHSSYKEYLSEEKNKSLNDWAQKNAIYVSIEEPLYSTFNQTASSSRQETDST |
| NCBI Accession | NP_671462.1 |
|---|---|
| Location | 2060-2317 |
| Gene Name | AC4 |
| Protein Name | hypothetical protein |
| Coding Region | ATGGGCAACCTCATCTTCACGTGCTTATTCAGTTCGAAGGAAAATTCGTCTGCACAAATCAAAGATTATTCGACTTGGTATCCCCAACACGGTCAACACATTTCCATCCGAACATACAGGGAGTTAAATCAAGTTCAGATGTTAAAGCATACATCGACAAGGATGGAGTCACCATTGAATGGGGCCAATTCCAGATCGACGGTAGATCTGCAAGAGGAGGACAACAATCCGCAAACGACTCATATGCAAAAGCGTTAA |
| Protein Sequence | MGNLIFTCLFSSKENSSAQIKDYSTWYPQHGQHISIRTYRELNQVQMLKHTSTRMESPLNGANSRSTVDLQEEDNNPQTTHMQKR |
| NCBI Accession | NP_671463.1 |
|---|---|
| Location | 346-1113 |
| Gene Name | BV1 |
| Protein Name | movement protein |
| Coding Region | ATGTATTCGTCAAGACAAAGACGTCAAACTTCTTACCCACGAGGAGGTTATTCACGTAATCATCTTTCTAAGCGTTCAACTATTGGTAAACGTAATAATGGTAGACGTCGACCTAATAATTTTGGTAAGGTTATTGATGAACCCAAAATGTTGGTTCAACGTATACATGAGAACCAATTTGGACCTGATTTTGTTATGACTCATAATACATCCATTTCTACATTTATTAGTTTTCCTGCTCTTGGTAAGTCTGAGCCCAATCGTTGTAGGCAATATATTAAATTGAAACGTTTACGTTTCAAAGGAACCGTTAAGATCGAGCGTGTTCATGCTGATGTGAATATGGATGGTTTATCACCTAAGATTGAAGGCGTATTCTCTCTGGTTATAGTGGTTGATCGTAGACCTCATCTTACTCCAAGTGGATGCTTACACACCTTTGATGAACTATTTGGTGCAAGAATCCACAGTCACGGTAACTTGGCCATAACATCTTCATTGAAAGACCGTTATTATATTCGCCATGTGTTTAAACGAGTTATATCCGTTGAGAAAGACACGATGATGATCGACGTTGATGGTGGAACGGTCTTGTCTAATAGGCGTTTTAATTTTTGGTCGACGTTTAAAGATCTTGACCATGATTCATGTAACGGTGTATATGACAACATAAGCAAGAACGCCATTTTAGTTTATTATTGTTGGATGTCGGACACAATGTCTAAGGCATCGACATTTGTATCATTTGACCTTGATTATGTTGGCTAA |
| Protein Sequence | MYSSRQRRQTSYPRGGYSRNHLSKRSTIGKRNNGRRRPNNFGKVIDEPKMLVQRIHENQFGPDFVMTHNTSISTFISFPALGKSEPNRCRQYIKLKRLRFKGTVKIERVHADVNMDGLSPKIEGVFSLVIVVDRRPHLTPSGCLHTFDELFGARIHSHGNLAITSSLKDRYYIRHVFKRVISVEKDTMMIDVDGGTVLSNRRFNFWSTFKDLDHDSCNGVYDNISKNAILVYYCWMSDTMSKASTFVSFDLDYVG |
| NCBI Accession | NP_671464.1 |
|---|---|
| Location | 1172-2053 |
| Gene Name | BC1 |
| Protein Name | movement protein |
| Coding Region | ATGGATTCTCAGTTAGCAAATCCTCCAAATGCATTTAATTATATTGAATCTCACAGGGATGAATATCAACTGTCTCATGACCTAACTGAAATCCTTCTTCAATTCCCCTCAACAACATCGCAATTATCGGCAAGACTCAGTCGTAGCTGTATGAAAATCGATCATTGCGTTATAGAATACAGACAACAAGTTCCTATAAACGCGACGGGTTCAGTAATAGTGGAGATTCATGATAGAAGAATGACAGACAATGAGTCTTTACAAGCTTCATGGACTTTTCCTTTAAGATGCAACATAGATCTCCACTATTTCTCTTCATCCTTCTTCTCGCTGAAAGACCCAATTCCATGGAAATTGTATTACAGAGTCTGTGATACAAATGTTCATCAAAGGACGCATTTTGCCAAATTCAAAGGCAAACTCAAACTGTCTACGGCGAAACATTCAGTGGATATTCCTTTCCGGGCACCAACTGTAAAAATACTTTCCAAACAATTTACGAATAAGGACGTGGATTTTTCGCACGTAGACTATGGGAGGTGGGAAAGGAAAATAATAAGGTCCGCATCTTTATCAAGATATGAGCTTCAGGGCCCAATTGAATTAAGACCAGGTGAGTCTTGGGCTTCAAGAAGCACAATAGGAATATCGCACACGGATGCGGACTCCGAATTAGAGAACGCAATACACCCATACAGAGATCTCAACAGGCTAGGAACCACCGCACTAGATCCAGGTGATTCGGCTTCGATAGTGGGTGCAAACAAAGCCCAATCAAACATCACATTATCAATGGCCCAAATAAACGAAATTGTTAGGTCAACAGTACATGAATGTATTAATAATAATTGTACTCCTTGTCTACCGAAATCTTTCAAATAA |
| Protein Sequence | MDSQLANPPNAFNYIESHRDEYQLSHDLTEILLQFPSTTSQLSARLSRSCMKIDHCVIEYRQQVPINATGSVIVEIHDRRMTDNESLQASWTFPLRCNIDLHYFSSSFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTNKDVDFSHVDYGRWERKIIRSASLSRYELQGPIELRPGESWASRSTIGISHTDADSELENAIHPYRDLNRLGTTALDPGDSASIVGANKAQSNITLSMAQINEIVRSTVHECINNNCTPCLPKSFK |
References More References in PubMed
| 1 |
Idris AM, et al. Plant Dis. 1999 Nov;83(11):1071. doi: 10.1094/PDIS.1999.83.11.1071C. PMID: 30841284 |
|---|---|
| 2 |
Idris AM, et al. Plant Dis. 2002 May;86(5):558. doi: 10.1094/PDIS.2002.86.5.558C. PMID: 30818684 |
| 3 |
Bracero V, et al. Plant Dis. 2003 Sep;87(9):1022-1025. doi: 10.1094/PDIS.2003.87.9.1022. PMID: 30812812 |
| 4 |
Two Newly Described Begomoviruses of Macroptilium lathyroides and Common Bean. Idris AM, et al. Phytopathology. 2003 Jul;93(7):774-83. doi: 10.1094/PHYTO.2003.93.7.774. PMID: 18943157 |
| 5 |
Rodriguez RL, et al. Plant Dis. 2001 Oct;85(10):1119. doi: 10.1094/PDIS.2001.85.10.1119C. PMID: 30823289 |