Macroptilium common mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_001777205.1 |
| Isolate | Brazil |
| Release date | 2016/10/19 |
| Submitter | Passos,L.S., Teixeira,J.W.M., Lima,K.J., Rodrigues,J.S., Soares,E.C.S., Xavier,C.A.D., Araujo,A.S.F., Zerbini,F.M., Beserra,J.E.A. Jr. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
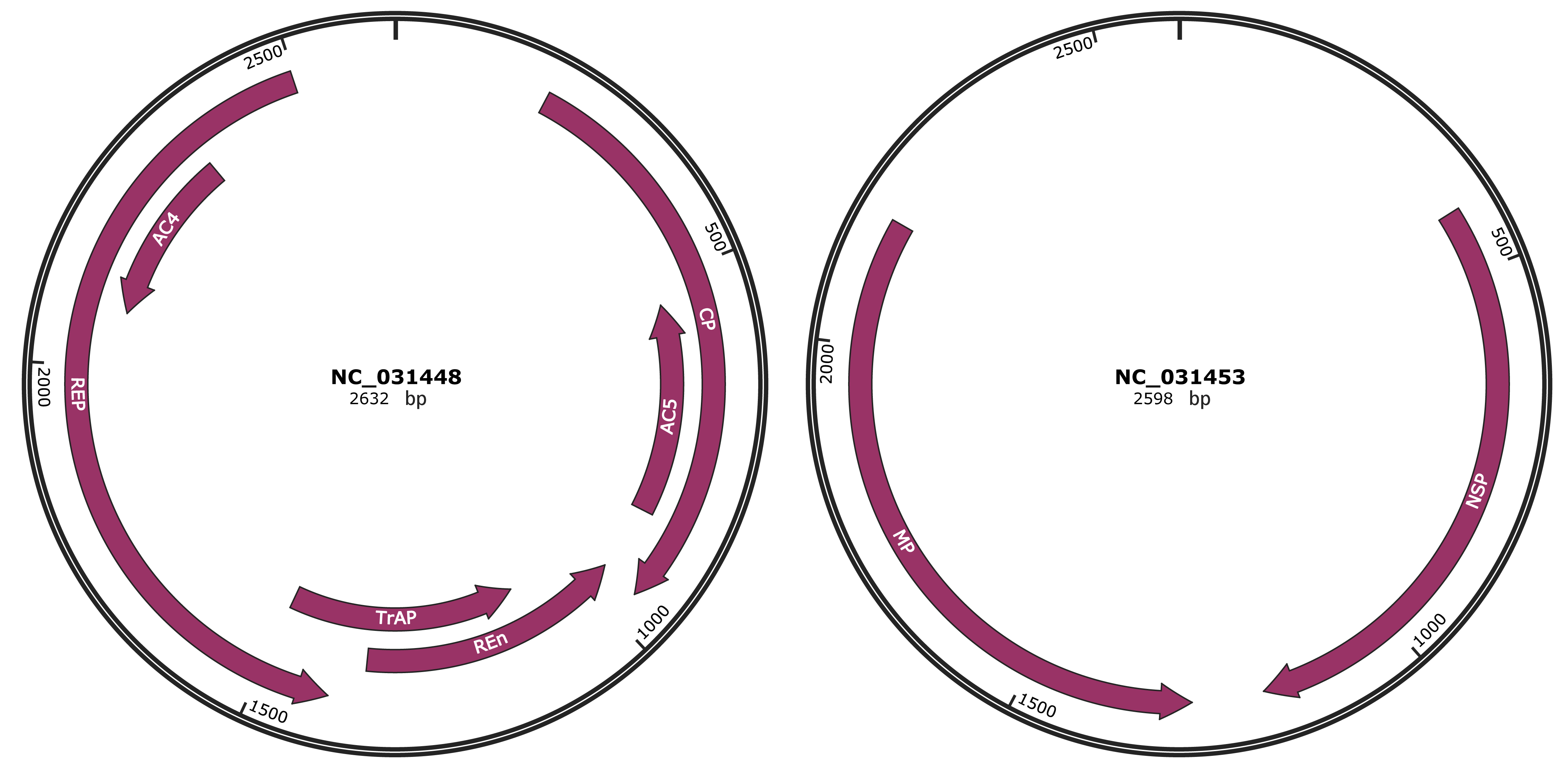
JBrowse
Genome
NC_031448
NC_031453
Gene Information
| NCBI Accession | YP_009310067.1 |
|---|---|
| Location | 205-960 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGGTTAAGCGGGATGCCCCATGGCGCCACATGGCAGGAACGTCTAAGATTAGTCGTTCGAGCAATTTTTCACCTCGGAGTGGAATTGGGCCAAAATTTAACAAGGCTTCTGAATGGGTTAACAGACCCATGTATAGGAAGCCCAGGATATATCGGACGTTAAGAAGTCCGGATGTTCCTAGGGGTTGTGAAGGCCCATGTAAAGTTCAGTCATTTGAACAACGACATGATGTGTCCCATGTTGGTAAGGTTATTTGTGTGTCTGACGTGACAAGGGGTAATGGTATTACCCATCGTGTAGGAAAACGTTTTTGTGTTAAGTCTGTGTATATACTAGGTAAGATATGGATGGACGAGAACATCAAGTTGAAGAACCATACCAATAGTGTGATGTTTTGGTTGGTCAGAGACCGTAGACCCTATGGTACTCCCATGGACTTTGGCCAAGTGTTCAACATGTTTGACAATGAGCCCAGTACTGCTACTGTTAAGAACGATCTTCGTGATCGTTTCCAAGTGATGCATAAATTTTATGCCAAAGTCACTGGTGGACAGTATGCGAGCAACGAGCAGGCATTGGTTAAGCGTTTTTGGAAGGTGAATAATTATGTTGTGTACAATCATCAAGAAGCAGGGAAGTACGAGAATCATACTGAGAACGCATTATTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACTTTGAAAATTCGGATCTATTTTTATGATTCGATATCCAATTAA |
| Protein Sequence | MVKRDAPWRHMAGTSKISRSSNFSPRSGIGPKFNKASEWVNRPMYRKPRIYRTLRSPDVPRGCEGPCKVQSFEQRHDVSHVGKVICVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQALVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | YP_009310068.1 |
|---|---|
| Location | 538-855 |
| Gene Name | AC5 |
| Protein Name | AC5 |
| Coding Region | ATGATTCTCGTACTTCCCTGCTTCTTGATGATTGTACACAACATAATTATTCACCTTCCAAAAACGCTTAACCAATGCCTGCTCGTTGCTCGCATACTGTCCACCAGTGACTTTGGCATAAAATTTATGCATCACTTGGAAACGATCACGAAGATCGTTCTTAACAGTAGCAGTACTGGGCTCATTGTCAAACATGTTGAACACTTGGCCAAAGTCCATGGGAGTACCATAGGGTCTACGGTCTCTGACCAACCAAAACATCACACTATTGGTATGGTTCTTCAACTTGATGTTCTCGTCCATCCATATCTTACCTAG |
| Protein Sequence | MILVLPCFLMIVHNIIIHLPKTLNQCLLVARILSTSDFGIKFMHHLETITKIVLNSSSTGLIVKHVEHLAKVHGSTIGSTVSDQPKHHTIGMVLQLDVLVHPYLT |
| NCBI Accession | YP_009310069.1 |
|---|---|
| Location | 957-1358 |
| Gene Name | REn |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAGTGGCGTATATATCTGGAGGATAACAAATCCCCTTTATTTCAAGATATGCAACGGGAGGATCCATCCACTACACACAACAACCAGAGTATACCACATACAGATAAGGTTCAACCACAACCTCAGGAACAGACTGGATCTTCACAAGGCATATCTCAATTTCCAAGTCTGGACGACATCGATTCAAGCTTCTGGGATGACTTATTTAAGTAGATTCAAGTATTTAGTTTTATTGTATATAGACCGTTTAGGAGTTATTTCTCTTAACAATGTAATCAGAGCTGTTCGTTTCGCAACAGACAAACCATATGTAAATTATGTACTTGAAAATCATGAAATAAAATACAAATTTTATTAA |
| Protein Sequence | MDSRTGELITARQAESGVYIWRITNPLYFKICNGRIHPLHTTTRVYHIQIRFNHNLRNRLDLHKAYLNFQVWTTSIQASGMTYLSRFKYLVLLYIDRLGVISLNNVIRAVRFATDKPYVNYVLENHEIKYKFY |
| NCBI Accession | YP_009310070.1 |
|---|---|
| Location | 1102-1500 |
| Gene Name | TrAP |
| Protein Name | trans-activating protein |
| Coding Region | ATGCAAAATTCGTCTTCCTCAACGCCCCCCTCTATCAAGATTCAACACAGAGCGGCCAAGAAGCGTCAACGTGCGATCAGGAGACGTCGCATTGATCTAGAGTGTGGCTGTTCAATTTTTCTACATATTAACTGCAGAGGACATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAGTGGCGTATATATCTGGAGGATAACAAATCCCCTTTATTTCAAGATATGCAACGGGAGGATCCATCCACTACACACAACAACCAGAGTATACCACATACAGATAAGGTTCAACCACAACCTCAGGAACAGACTGGATCTTCACAAGGCATATCTCAATTTCCAAGTCTGGACGACATCGATTCAAGCTTCTGGGATGACTTATTTAAGTAG |
| Protein Sequence | MQNSSSSTPPSIKIQHRAAKKRQRAIRRRRIDLECGCSIFLHINCRGHGFTHRGTHHCTSGREWRIYLEDNKSPLFQDMQREDPSTTHNNQSIPHTDKVQPQPQEQTGSSQGISQFPSLDDIDSSFWDDLFK |
| NCBI Accession | YP_009310071.1 |
|---|---|
| Location | 1406-2497 |
| Gene Name | REP |
| Protein Name | replication-associated protein |
| Coding Region | ATGCCACCCCCAAAGCGTTTTAAAATAAACGCCAAGAATTACTTCCTCACATACCCCAAATGCTCAGTTACAAAAGAGAGTGCAATTGAACAACTACAAAACCTAGAAACACCAGTCAACAAGAAATACATCAGAATCTGCAGAGAATTTCACGAAAATGGGGAACCGCATTTGCATGCTCTCATTCAATTCCAAGGAAAGTTCCAGTGCACGAATTGCAGATTCTTCGACCTCATACATCCAAACACCTCTTCCGTCTCCCATGCCAATATACAGAGTGCAAAGTCATCCTCTGATGTCAAGTCCTACATCGAGAAAGACGGTGATTACGTCGAATGGGGTCATTTTCAAATCGACGGAAGATCTGCTAGAGGAGGTCAACAGACAACTAATGATGCAGCATCGGAGGCACTGAATGCTTCTTCAAAGGAAGAAGCCATGACAATAATAAAAGAGAAACTACCAGAAAAGTTTCTCTTCCAATATCACAACCTCTCTAGCAATTTGGACAGAATTTTTGCAAAGGCTCCGGAGCCATGGACTCCTCCGTTTCACCTCTCCTCTTTCACTAACGTGCCGAGAGAGATGCAAGACTGGGCAGATGATTATTTCGGGAGAGGTGCCGCTGCGCGGCCGGAAAGACCTATCAGTATCATCGTCGAAGGTGATTCTAGAACGGGGAAGACGATGTGGGCACGTGCATTGGGGGTCCACAATTATTTGAGCGGCCACCTAGATTTCAATTCACGGGTCTATTCAAACCATGTGCAATACAACGTCATTGACGACATAGCACCCCACTATCTAAAGTTAAAGCATTGGAAAGAATTGATTGGCGCTCAAAAAGACTGGCAATCAAATTGCAAATACGGCAAGCCAGTTCAAATTAAAGGAGGTATCCCATGCATCGTGCTTTGCAATCCTGGTGAGGGATCTAGTTATAAATGTTTCCTCGACAAAGAGGAAAACGCATCACTTAGACAGTGGACGATACACAATGCAAAATTCGTCTTCCTCAACGCCCCCCTCTATCAAGATTCAACACAGAGCGGCCAAGAAGCGTCAACGTGCGATCAGGAGACGTCGCATTGA |
| Protein Sequence | MPPPKRFKINAKNYFLTYPKCSVTKESAIEQLQNLETPVNKKYIRICREFHENGEPHLHALIQFQGKFQCTNCRFFDLIHPNTSSVSHANIQSAKSSSDVKSYIEKDGDYVEWGHFQIDGRSARGGQQTTNDAASEALNASSKEEAMTIIKEKLPEKFLFQYHNLSSNLDRIFAKAPEPWTPPFHLSSFTNVPREMQDWADDYFGRGAAARPERPISIIVEGDSRTGKTMWARALGVHNYLSGHLDFNSRVYSNHVQYNVIDDIAPHYLKLKHWKELIGAQKDWQSNCKYGKPVQIKGGIPCIVLCNPGEGSSYKCFLDKEENASLRQWTIHNAKFVFLNAPLYQDSTQSGQEASTCDQETSH |
| NCBI Accession | YP_009310072.1 |
|---|---|
| Location | 2083-2340 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGGGGAACCGCATTTGCATGCTCTCATTCAATTCCAAGGAAAGTTCCAGTGCACGAATTGCAGATTCTTCGACCTCATACATCCAAACACCTCTTCCGTCTCCCATGCCAATATACAGAGTGCAAAGTCATCCTCTGATGTCAAGTCCTACATCGAGAAAGACGGTGATTACGTCGAATGGGGTCATTTTCAAATCGACGGAAGATCTGCTAGAGGAGGTCAACAGACAACTAATGATGCAGCATCGGAGGCACTGA |
| Protein Sequence | MGNRICMLSFNSKESSSARIADSSTSYIQTPLPSPMPIYRVQSHPLMSSPTSRKTVITSNGVIFKSTEDLLEEVNRQLMMQHRRH |
| NCBI Accession | YP_009310073.1 |
|---|---|
| Location | 418-1188 |
| Gene Name | NSP |
| Protein Name | nuclear shuttle protein |
| Coding Region | ATGTATTTTAATAGGAATAGACGTGGTTTTGCATCTACTTGGAGGCGAAGTAATTCGCGGTATCCTCTGGTCAAACGTTCTTATGGTGTGAAAAGAATCATTGGCAAACGTGGATCGAATATTTCTAATAAGGCCCAAGAAGATAGTAAGATGACTGTCCAACGTCTACATGAAAATCAATTTGGGCCTGAGTTTGTTATGGCCCATAATTCAGCTATATCTACGATTATTAATTACCCTCATCTTGGTAAGTCGAAGCCCAATCGATCAAGGGCGTATATTAAGTTAAAACGTTTATTATTTAAGGGTACTGTTAAAATTGAACGTGTTTACCCTGATATGAATATGGTTGGTACGACTCCTAAGATTGAAGGCGTATTTTCTATGGTTGTTGTTGTTGATCGTAAACCCCATTTGGCTTCGACTGGATGTCTCCATACATTTGACGAATTGTTTGGTGCAAGAATTCACAGTCATGGTAATTTAGCCATCGTTGATTCATTGAAGGACCGATTTTATATTCGTCATGTGTTTAAGCGTGTGATATCTGTGGAGAAGGATAGCACGATGGTCGACGTTGATGGAAGTGCATTCTTGTCAAATAGGCGATTTAATTGTTGGTCTACATTTAAAGATATTGATCGTGACTCTTGTAATGGTGTTTATGCTAACATAAGCAAGAATGCCCTTCTAGTTTATTACTGTTGGATGTCTGATTCTATGTCCAAGGCATCCACGTTTGTATCATTCGACCTTGAATATGTGGGATGA |
| Protein Sequence | MYFNRNRRGFASTWRRSNSRYPLVKRSYGVKRIIGKRGSNISNKAQEDSKMTVQRLHENQFGPEFVMAHNSAISTIINYPHLGKSKPNRSRAYIKLKRLLFKGTVKIERVYPDMNMVGTTPKIEGVFSMVVVVDRKPHLASTGCLHTFDELFGARIHSHGNLAIVDSLKDRFYIRHVFKRVISVEKDSTMVDVDGSAFLSNRRFNCWSTFKDIDRDSCNGVYANISKNALLVYYCWMSDSMSKASTFVSFDLEYVG |
| NCBI Accession | YP_009310074.1 |
|---|---|
| Location | 1283-2164 |
| Gene Name | MP |
| Protein Name | movement protein |
| Coding Region | ATGGAGTCTCAATTAGTTCATCCACCAACGGCGTTCAATTATGTAGAATCGCATCGTGATGAATATCAGTTGTCTCATGATTTGAATGAGATAGTATTGCAATTTCCTTCTACAGCAGCTCAATTGAGTGCCAGAATCAGTCGAAGCTGTATGAAAATCGATCATTGCGTCATTGAATACAGACAACAAGTTCCAATCAACGCAACAGGAGCGGTAATTGTAGAGATTCATGACAAAAGAATGACAGACAATGAATCATTACAAGCGTCCTGGACATTTCCAATAAGATGTAACATAGATCTTCATTTTTTTTCCTCGTCGTTCTTTTCCCTTAAAGACCCAATTCCTTGGAAATTATATTACAGGGTTAGCGACACAAATGTTCATCAAAGAACTCACTTCGCTAAGTTTAAGGGTAAATTGAAGATCTCTACAGCAAAACATTCAGTGGATATTCCTTTCAAACCACCCACAGTAAAAATATTATCAACCCAGTTCACAGAAAAAGATGTTGATTTTTCACATGTCGGTTACGGCAAATATGAAAGGAAATTGATCAAATCCGCTTCAACATCAAGGTATGGGCTTCACAGCCCAATAACATTAAAACCAGGTGAAACATGGGCAACACGAAGCACAATAGGAGCAAGTTCAATAGAAGCGGATTCGGAGATAGACAACGCAATACATCCATATAGACATCTACACAGATTGGACACCAGCATACTAGACCCAGGTGATTCGGCTTCAATAATAGGAGCAAGACGGACTGAGTCCAATATAACCATTTCCATGGCCCAATTAAACGAATTAGTTAAAACAGCGGCACAAGAATGTATTAACACCAATTGTACTCCTGCACAACCAAAGTCCTTGAAATAA |
| Protein Sequence | MESQLVHPPTAFNYVESHRDEYQLSHDLNEIVLQFPSTAAQLSARISRSCMKIDHCVIEYRQQVPINATGAVIVEIHDKRMTDNESLQASWTFPIRCNIDLHFFSSSFFSLKDPIPWKLYYRVSDTNVHQRTHFAKFKGKLKISTAKHSVDIPFKPPTVKILSTQFTEKDVDFSHVGYGKYERKLIKSASTSRYGLHSPITLKPGETWATRSTIGASSIEADSEIDNAIHPYRHLHRLDTSILDPGDSASIIGARRTESNITISMAQLNELVKTAAQECINTNCTPAQPKSLK |
References More References in PubMed
| 1 |
Macroptilium yellow mosaic virus, a New Begomovirus Infecting Macroptilium lathyroides in Cuba. Ramos PL, et al. Plant Dis. 2002 Sep;86(9):1049. doi: 10.1094/PDIS.2002.86.9.1049B. PMID: 30818538 |
|---|---|
| 2 |
First Report of Bean common mosaic virus in Cudrania tricuspidata in Korea. Seo JK, et al. Plant Dis. 2015 Feb;99(2):292. doi: 10.1094/PDIS-07-14-0678-PDN. PMID: 30699581 |
| 3 |
First Report of Passiflora virus Y Infecting Macroptilium atropurpureum in Taiwan. Chiang CH, et al. Plant Dis. 2012 Jun;96(6):918. doi: 10.1094/PDIS-11-11-0952-PDN. PMID: 30727392 |
| 4 |
Idris AM, et al. Plant Dis. 1999 Nov;83(11):1071. doi: 10.1094/PDIS.1999.83.11.1071C. PMID: 30841284 |
| 5 |
Two Newly Described Begomoviruses of Macroptilium lathyroides and Common Bean. Idris AM, et al. Phytopathology. 2003 Jul;93(7):774-83. doi: 10.1094/PHYTO.2003.93.7.774. PMID: 18943157 |
| 6 |
Roye ME, et al. Plant Dis. 1997 Nov;81(11):1251-1258. doi: 10.1094/PDIS.1997.81.11.1251. PMID: 30861729 |
| 7 |
Passos LS, et al. Arch Virol. 2017 Nov;162(11):3551-3554. doi: 10.1007/s00705-017-3522-y. Epub 2017 Aug 4. PMID: 28779234 |
| 8 |
Idris AM, et al. Plant Dis. 2002 May;86(5):558. doi: 10.1094/PDIS.2002.86.5.558C. PMID: 30818684 |
| 9 |
Nanopore sequencing of a novel bipartite New World begomovirus infecting cowpea. Naito FYB, et al. Arch Virol. 2019 Jul;164(7):1907-1910. doi: 10.1007/s00705-019-04254-5. Epub 2019 Apr 10. PMID: 30972591 |
| 10 |
A New Tomato-Infecting Begomovirus in Barbados. Roye ME, et al. Plant Dis. 2000 Dec;84(12):1342. doi: 10.1094/PDIS.2000.84.12.1342A. PMID: 30831878 |