Ludwigia yellow vein Vietnam virus
Basic Information
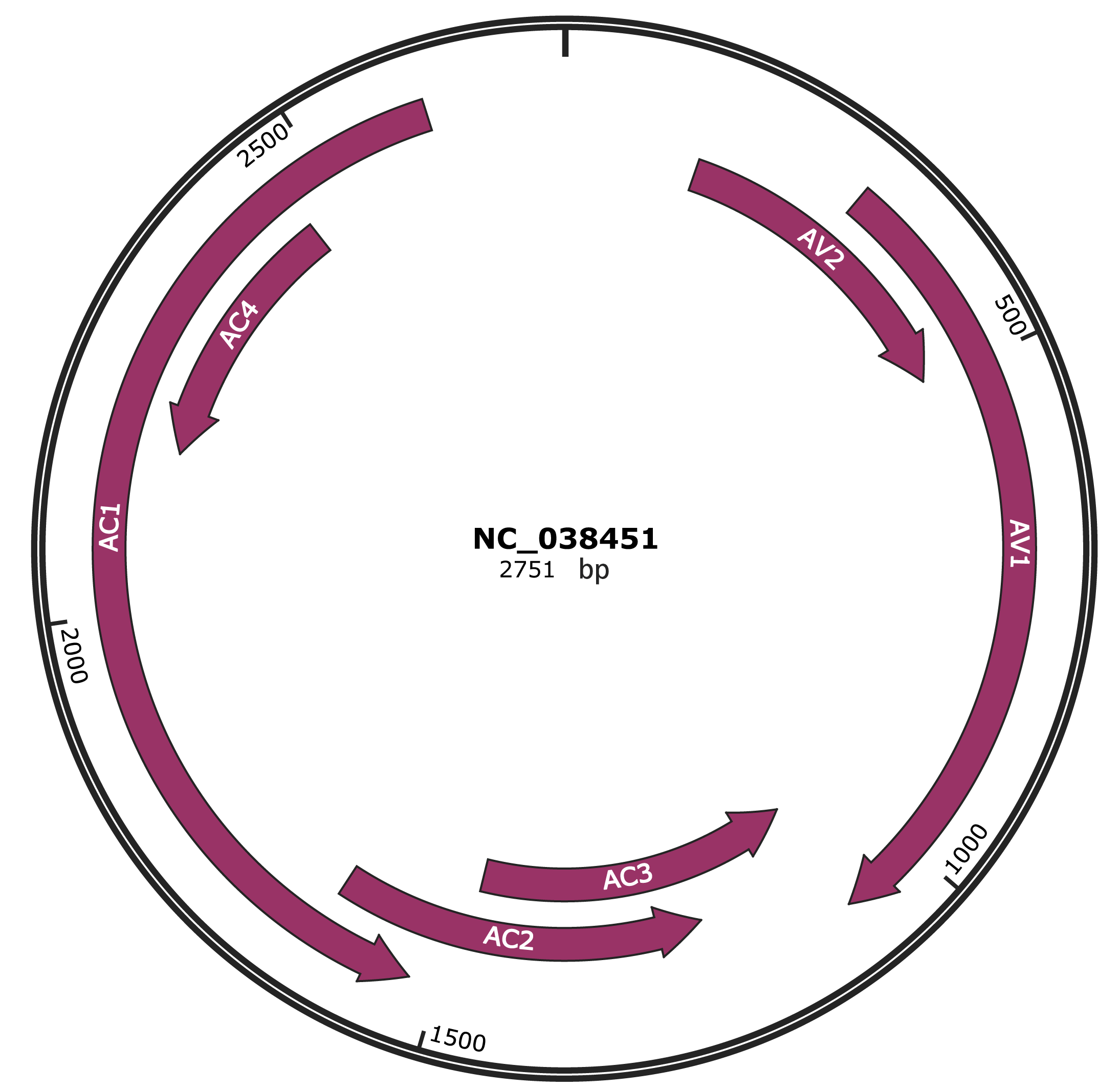
Genomic Organization
JBrowse
Genome
ACCGGATGGCCGCGCAAATTTTTCCCCCCTTTCACTTTAGTGGGTCCCCCGCACTATTTTTGGTCGGCCAATGAGAATACGCGCTCAAAGCTTAGATAACCGTGTGGTCCCGCCATAAATAACTTCCCCTCGAAGGTAAATTCAAAATGTGGGATCCGTTGGAGCACGAGTTTCCGGAAACTCTTCACGGTTTCCGTTGTATGCTCGCTATCAAATACCTGCAGACTGTAGCGGATACGTATGCTCCGGATACGGTAGGTTACGATCTTATTCGTGATTTAATTTCTATTGTACGAGCTGGCAACTATGTCGAAGCGACCCGCCGATATAGTCATTTCAACACCCGTCTCCAAAGTACGTCGCCGGTTGAACTTCGATTCCCCCGGAGTGAGCCGTGTTGCTGCCCGCACTGTCCTCGGCATAACCCGAAAGAATGCCTGGACGTACAGGCCCACGTATCGCAAGCCCAGACTGTACAGAATGTACAGAAGCCCTGATGTCCCTCGTGGTTGTGAGGGTCCATGTAAGGTTCAGTCGTTCGAGAAGAAACATGATGTTGGTCATACTGGTACATTATTATGTGTGTCCGATGTTACTCGTGGAAATGGGTTAACCCATCGCACTGGGAAGAGGTTCTGTATTAAGTCTATTTACATTCTGGGTAAGTTATGGATGGATGAGAACATCAAGACGAAGAATCACACGAACACAGTCATGTTCTGGTTAGTTAGGGATAGGCGTCCTGTCACAACGCCATATGGGTTCGGCGAGGCATTCAACATGTACGACAATGAGCCCAGTACAGCAACTATCAAGAACGATCTTCGTGACCGTCTGCAGGTGCTGCACAGGTTTCAAGCCACTCTCACAGGAGGTCAGTACGCGTGCAAGGAGCAGGTAATGGTGAAGAGGTTCTGGAAGATCAACAATCACGTCGTCTACAACCATCAGGAGAAGGCTGCTTACGAGAATCACACTGAGAACGCATTAATATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACACTGAAGATCCGCATCTACTTCTATGATTCAGTCCAGAATTAATAAAGATTATATTTTATTATGTGTGTCAATTGAGCATCAATTGTGCCCTCCAGTACATCGTACAATACATGAGTTATAGCCCTAATTACATTGTTGATACTAATAATGCCTAAGTTATCTAAATACTTCATACATTGAACATTAAATACTCTTAAGAAACGCCCAGTCTGAGGACGTAAACGAGTCCAGATCTGGCAGATCAGGAAACACTGGTGCATCCCCAGTGCTTTCCTCAGGTTGTAGTTGAACTGGACTTGGATTGTTATTACGTCGTGATCCCTCAGGAATGGCCTCACCAGGTGCTTGGTAATCTTGAAATAGAGGGGATTTCTGACCGTCCAGGTATAGACGCCACTCTCTGCCTGAGTTGCAGTGATGTATTCCCCGGTGCGAAAATCCATGGTTGGCACAGGTAATTGGAAAGAAGTATGAGCAGCCGCACGGTAGATCAACTCTCCTCCGGCGTATTGACTTCTTCTTGGCTATTCTGTGCTGGACTTTGATGGGTACCTGAGTACAGTGGCTCTGAGAGGAAGACGAATTCTGCATTCTTCAGTGCCCAGGACTTTAGAGCTGAATTCTTATCCTCGTCCAGATACTCCTTATATGATGATGTTGGGCCAGGATTGCATAGAAAGATTGTCGGAATTCCCCCTTTAATTTGAATGGGCTTCCCGTACTTGGTATTGCTTTGCCAATCCCTCTGGGCCCCCATGAATTCCTTAAAGTGCTTTAGATAATGGGGGTCCACATCATCGATGACGTTATACCATGCGTCATTAGAGTAGATCTTGGGGCTCAAGTCTAGATGCCCACAAAGGTAATTATGTGGGCCCAATGATCTGGCCCACATTGTCTTCCCAGTTCTACTCTCTCCTTCTACCACTATACTCACCGGTCGCCAAGGCCGCGCAGCGGCATCCCTGACGTTCTCCTCCGCCCAACATTCAAGTTCTTCCGGAACTCGATCGAATGAAGAAGCTAAAAAAGGAGAAACAAAAACCTCTACTGGAGGTGCAAAAATCCTATCTAAATTAGCATTTAAATTATGAAATTGTAAAACAAAATCTTTAGGAGCTAACTCCTTAATTACATTAAGAGCCTCTGACTTACTGCCGCTGTTAAGCGCCTGGGCGTAAGCGTCATTGGCTGTCTGTTGTCCCCCTCTTGCAGATCGTCCGTCGATCTGAAACTCTCCCCAATCGAGGGTGTCTCCGTCCTTCTCCAGGTAGGACTTGACATCTGAACTCGATTTAGCCCCCTGTAAGTTCGGATGGAAATGTGCGCTCCTACTTGGGGATACCAGGTCGAAGAATCGTGGATTCGTGCAGTTGTACTTCCCTTCGAACTGCACGAGCACATGGAGATGAGGGCTCCCATCTTCGTGAAGCTCTCTGCAGATCTTGATGTATTTCTTGTTGGTCGGAGTGTTTAGGGCTTGCAATTGGGAAAGTGCTTCTTCTTTGGAGAGAGAGCAGTGTGGATAAGTGAGGAAATAGTTCTTGGCTTTAATAGAAAATCTGCCGGCTCTTGGCATTTTGGAATCGGGGGGCACTCAAAGTCCTGTGCAATTGGGGGAACGGGGGGACAATTTATATGTGCCCCCCTAATGGCATTCTTGAAATTTCCTTTGCAATTTCAAATTCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009506431.1
|
|
Location
|
147-497 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCGTTGGAGCACGAGTTTCCGGAAACTCTTCACGGTTTCCGTTGTATGCTCGCTATCAAATACCTGCAGACTGTAGCGGATACGTATGCTCCGGATACGGTAGGTTACGATCTTATTCGTGATTTAATTTCTATTGTACGAGCTGGCAACTATGTCGAAGCGACCCGCCGATATAGTCATTTCAACACCCGTCTCCAAAGTACGTCGCCGGTTGAACTTCGATTCCCCCGGAGTGAGCCGTGTTGCTGCCCGCACTGTCCTCGGCATAACCCGAAAGAATGCCTGGACGTACAGGCCCACGTATCGCAAGCCCAGACTGTACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLEHEFPETLHGFRCMLAIKYLQTVADTYAPDTVGYDLIRDLISIVRAGNYVEATRRYSHFNTRLQSTSPVELRFPRSEPCCCPHCPRHNPKECLDVQAHVSQAQTVQNVQKP |
|
NCBI Accession
|
YP_009506432.1
|
|
Location
|
307-1080 |
|
Gene Name
|
AV1 |
|
Protein Name
|
CP protein |
|
Coding Region
|
ATGTCGAAGCGACCCGCCGATATAGTCATTTCAACACCCGTCTCCAAAGTACGTCGCCGGTTGAACTTCGATTCCCCCGGAGTGAGCCGTGTTGCTGCCCGCACTGTCCTCGGCATAACCCGAAAGAATGCCTGGACGTACAGGCCCACGTATCGCAAGCCCAGACTGTACAGAATGTACAGAAGCCCTGATGTCCCTCGTGGTTGTGAGGGTCCATGTAAGGTTCAGTCGTTCGAGAAGAAACATGATGTTGGTCATACTGGTACATTATTATGTGTGTCCGATGTTACTCGTGGAAATGGGTTAACCCATCGCACTGGGAAGAGGTTCTGTATTAAGTCTATTTACATTCTGGGTAAGTTATGGATGGATGAGAACATCAAGACGAAGAATCACACGAACACAGTCATGTTCTGGTTAGTTAGGGATAGGCGTCCTGTCACAACGCCATATGGGTTCGGCGAGGCATTCAACATGTACGACAATGAGCCCAGTACAGCAACTATCAAGAACGATCTTCGTGACCGTCTGCAGGTGCTGCACAGGTTTCAAGCCACTCTCACAGGAGGTCAGTACGCGTGCAAGGAGCAGGTAATGGTGAAGAGGTTCTGGAAGATCAACAATCACGTCGTCTACAACCATCAGGAGAAGGCTGCTTACGAGAATCACACTGAGAACGCATTAATATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCTACACTGAAGATCCGCATCTACTTCTATGATTCAGTCCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPVSKVRRRLNFDSPGVSRVAARTVLGITRKNAWTYRPTYRKPRLYRMYRSPDVPRGCEGPCKVQSFEKKHDVGHTGTLLCVSDVTRGNGLTHRTGKRFCIKSIYILGKLWMDENIKTKNHTNTVMFWLVRDRRPVTTPYGFGEAFNMYDNEPSTATIKNDLRDRLQVLHRFQATLTGGQYACKEQVMVKRFWKINNHVVYNHQEKAAYENHTENALILYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_009506433.1
|
|
Location
|
1077-1481 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn protein |
|
Coding Region
|
ATGGATTTTCGCACCGGGGAATACATCACTGCAACTCAGGCAGAGAGTGGCGTCTATACCTGGACGGTCAGAAATCCCCTCTATTTCAAGATTACCAAGCACCTGGTGAGGCCATTCCTGAGGGATCACGACGTAATAACAATCCAAGTCCAGTTCAACTACAACCTGAGGAAAGCACTGGGGATGCACCAGTGTTTCCTGATCTGCCAGATCTGGACTCGTTTACGTCCTCAGACTGGGCGTTTCTTAAGAGTATTTAATGTTCAATGTATGAAGTATTTAGATAACTTAGGCATTATTAGTATCAACAATGTAATTAGGGCTATAACTCATGTATTGTACGATGTACTGGAGGGCACAATTGATGCTCAATTGACACACATAATAAAATATAATCTTTATTAA |
|
Protein Sequence
|
MDFRTGEYITATQAESGVYTWTVRNPLYFKITKHLVRPFLRDHDVITIQVQFNYNLRKALGMHQCFLICQIWTRLRPQTGRFLRVFNVQCMKYLDNLGIISINNVIRAITHVLYDVLEGTIDAQLTHIIKYNLY |
|
NCBI Accession
|
YP_009506434.1
|
|
Location
|
1222-1629 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP protein |
|
Coding Region
|
ATGCAGAATTCGTCTTCCTCTCAGAGCCACTGTACTCAGGTACCCATCAAAGTCCAGCACAGAATAGCCAAGAAGAAGTCAATACGCCGGAGGAGAGTTGATCTACCGTGCGGCTGCTCATACTTCTTTCCAATTACCTGTGCCAACCATGGATTTTCGCACCGGGGAATACATCACTGCAACTCAGGCAGAGAGTGGCGTCTATACCTGGACGGTCAGAAATCCCCTCTATTTCAAGATTACCAAGCACCTGGTGAGGCCATTCCTGAGGGATCACGACGTAATAACAATCCAAGTCCAGTTCAACTACAACCTGAGGAAAGCACTGGGGATGCACCAGTGTTTCCTGATCTGCCAGATCTGGACTCGTTTACGTCCTCAGACTGGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQNSSSSQSHCTQVPIKVQHRIAKKKSIRRRRVDLPCGCSYFFPITCANHGFSHRGIHHCNSGREWRLYLDGQKSPLFQDYQAPGEAIPEGSRRNNNPSPVQLQPEESTGDAPVFPDLPDLDSFTSSDWAFLKSI |
|
NCBI Accession
|
YP_009506435.1
|
|
Location
|
1529-2617 |
|
Gene Name
|
AC1 |
|
Protein Name
|
rep protein |
|
Coding Region
|
ATGCCAAGAGCCGGCAGATTTTCTATTAAAGCCAAGAACTATTTCCTCACTTATCCACACTGCTCTCTCTCCAAAGAAGAAGCACTTTCCCAATTGCAAGCCCTAAACACTCCGACCAACAAGAAATACATCAAGATCTGCAGAGAGCTTCACGAAGATGGGAGCCCTCATCTCCATGTGCTCGTGCAGTTCGAAGGGAAGTACAACTGCACGAATCCACGATTCTTCGACCTGGTATCCCCAAGTAGGAGCGCACATTTCCATCCGAACTTACAGGGGGCTAAATCGAGTTCAGATGTCAAGTCCTACCTGGAGAAGGACGGAGACACCCTCGATTGGGGAGAGTTTCAGATCGACGGACGATCTGCAAGAGGGGGACAACAGACAGCCAATGACGCTTACGCCCAGGCGCTTAACAGCGGCAGTAAGTCAGAGGCTCTTAATGTAATTAAGGAGTTAGCTCCTAAAGATTTTGTTTTACAATTTCATAATTTAAATGCTAATTTAGATAGGATTTTTGCACCTCCAGTAGAGGTTTTTGTTTCTCCTTTTTTAGCTTCTTCATTCGATCGAGTTCCGGAAGAACTTGAATGTTGGGCGGAGGAGAACGTCAGGGATGCCGCTGCGCGGCCTTGGCGACCGGTGAGTATAGTGGTAGAAGGAGAGAGTAGAACTGGGAAGACAATGTGGGCCAGATCATTGGGCCCACATAATTACCTTTGTGGGCATCTAGACTTGAGCCCCAAGATCTACTCTAATGACGCATGGTATAACGTCATCGATGATGTGGACCCCCATTATCTAAAGCACTTTAAGGAATTCATGGGGGCCCAGAGGGATTGGCAAAGCAATACCAAGTACGGGAAGCCCATTCAAATTAAAGGGGGAATTCCGACAATCTTTCTATGCAATCCTGGCCCAACATCATCATATAAGGAGTATCTGGACGAGGATAAGAATTCAGCTCTAAAGTCCTGGGCACTGAAGAATGCAGAATTCGTCTTCCTCTCAGAGCCACTGTACTCAGGTACCCATCAAAGTCCAGCACAGAATAGCCAAGAAGAAGTCAATACGCCGGAGGAGAGTTGA |
|
Protein Sequence
|
MPRAGRFSIKAKNYFLTYPHCSLSKEEALSQLQALNTPTNKKYIKICRELHEDGSPHLHVLVQFEGKYNCTNPRFFDLVSPSRSAHFHPNLQGAKSSSDVKSYLEKDGDTLDWGEFQIDGRSARGGQQTANDAYAQALNSGSKSEALNVIKELAPKDFVLQFHNLNANLDRIFAPPVEVFVSPFLASSFDRVPEELECWAEENVRDAAARPWRPVSIVVEGESRTGKTMWARSLGPHNYLCGHLDLSPKIYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLDEDKNSALKSWALKNAEFVFLSEPLYSGTHQSPAQNSQEEVNTPEES |
|
NCBI Accession
|
YP_009506436.1
|
|
Location
|
2170-2460 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGGGAGCCCTCATCTCCATGTGCTCGTGCAGTTCGAAGGGAAGTACAACTGCACGAATCCACGATTCTTCGACCTGGTATCCCCAAGTAGGAGCGCACATTTCCATCCGAACTTACAGGGGGCTAAATCGAGTTCAGATGTCAAGTCCTACCTGGAGAAGGACGGAGACACCCTCGATTGGGGAGAGTTTCAGATCGACGGACGATCTGCAAGAGGGGGACAACAGACAGCCAATGACGCTTACGCCCAGGCGCTTAACAGCGGCAGTAAGTCAGAGGCTCTTAATGTAA |
|
Protein Sequence
|
MGALISMCSCSSKGSTTARIHDSSTWYPQVGAHISIRTYRGLNRVQMSSPTWRRTETPSIGESFRSTDDLQEGDNRQPMTLTPRRLTAAVSQRLLM |