Ageratum yellow vein Sri Lanka virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000838085.1 |
| Isolate | Sri Lanka |
| Release date | 2015/2/12 |
| Submitter | Tsai,W.S., Ariyaratne,I., Green,S.K. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
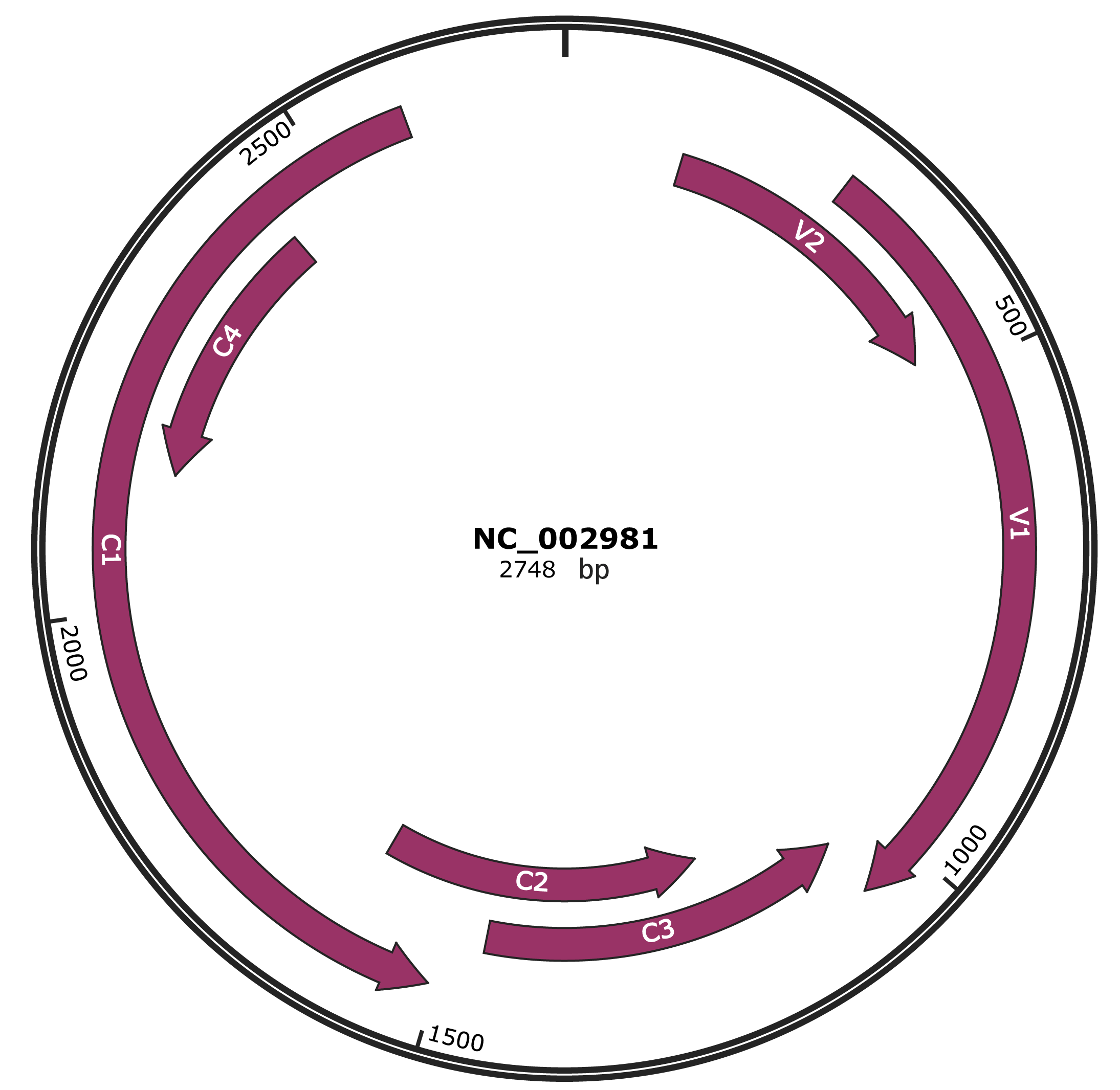
JBrowse
Genome
NC_002981
ACCGGATGGCCGCGATTTTTTTTAAAGTGGTCCCCAGAGCACGTGGTCCAATAATAGACGCTCCTTAAAGCTTAATTAATGGCTTGTGGGCCTATATACTTGCCCACCAAGTAGTGGGATTTGTCATCATGTGGGATCCTCTTTTAAACGAGTTCCCCGATACGGTTCACGGATTCCGGTGTATGCTTGCTGTAAAATACTTACAGCTCGTAGAAAATACGTATTCACCTGATTCGTTGGGTTACGATCTAATTCGTGATTTAATCTCAGTTATTAGGGCTAAGAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCATCGAAGGTGCGTCGCCGTCTCAACTTCGAGACCCCGTACACGAGCCGTGTAGCTGTCCCCACTGTCCGCGTCACAAAGTCACGAGCATGGGCCAACAGGCCCATGAATCGGAAACCCAGAATATACAGAATGTACAGAAGTCCTGATGTTCCCAGAGGATGCGAAGGCCCATGTAAGGTTCAGTCGTTCGAGTCTAGACATGACATATCCCATATTGGGAAGGTAATGTGTATTAGTGATGTCACCCGTGGAATTGGGCTAACTCATAGGGTCGGTAAGAGGTTTTGTGTTAAGTCCGTATATGTATTGGGCAAGGTGTGGATGGATGAGAGTATCAAAACTAAGAATCACACGAATAGTGTGATGTTTTTTTTGTGTCGTGACAGGAGGCCTGTTGACAAACCCCAGGATTTTGGTGAGGTGTTTAATATGTTTGATAATGAGCCCAGTACTGCAACTGTGAAGAATGTTTTTCGTGATCGCTACCAAGTATTGAGGAAATGGCACGCAACTGTCACTGGTGGAACCTATGCGTCCAAGGAGCAGGCTTTGGTTAAGAAGTTTGTTAGGGTTAATAATTATGTTGTTTATAACCAGCAAGAGGCTGGGAAGTATGAGAATCATAGTGAGAATGCTTTGATGTTGTATATGGCGTCTACGCACGCCTCTAATCCTGTGTATGCTACATTGAAGATACGGATCTATTTTTATGATTCTGTATCTAATTAATAAATATTGAATTTTATTGAATGTGATTGTTCAACGTACAAAATGTGATGCAATACATCCCATAAAACATGATCTACTGCTCTAATTACATTGTTTAAACTAATAACCCCTAAACTATCTAAATATTTAAGTGCTTGGTTCTTAAAGACCCTTAAGAAACGACCAGTCTGAGGTTGTGAAGTCATCCAGATTCGGAAGATTAGAAAACACTTGTGAATCCCCAATGCCTTCCTCAGGTTGTGATTGAATTGGATCTGCATTGTGATTATGTCGTGATTCTGAAGGAATGCGCGGTTGTGGTGCTCCGTTATCTTGAAATAAAGGGGATTTTGTATCTCCCAGATATACACGCCATTCTCTGCTTGAGCTGCATTGATGTACTCCCCTGTGCGAGAATCCATGGTTATGACAGGCTAGGGCTATGAAGTATGAGCATCCACAGGGTAGATCAACCCTCCGACGTCTGTTGCTCTTCTTCGCTAACCTGTGTTGGACTTTGATGGGTACCTGAGTAGAGTGGCTCTTCGAGGGTGACGAAGGTCGCATTCTTCAGAGCCCAGTTTTTAAGCGCACTGTTTTTCTCTTCATCCAGATACTCTTTATAGCTTGAATTGGGTCCTGGATTGCAGAGGAAGATAGTGGGAATTCCGCCTTTAATTTGAACAGGTTTCCCGTACTTGGTGTTGCTTTGCCAGTCTCTTTGGGCCCCCATGAACTCTTTAAAGTGCTTTAGATAGTGCGGATCGACGTCATCAATGACGTTATACCAGGCATCATTACTGTACACTTTTGGACTCAGGTCGAGATGACCGCACAAATAATTGTGTGGTCCTAGTGACCTGGCCCACATTGTTTTTCCGGTACGACTATCACCCTCAATTACAATACTAATGGGCCTGATAGGCCGCGCAGCGGCACTGACAACGTTTTCACATGCCCACTCTTCAAGTTCTTCTGGAACTTGGTCGAAAGAAGAAGATAAAAAAGGGGAAACATAAACCTCCATTGGAGGTGTAAAAATCCTATCTAAATTTGAATTTAAGTTATGAAATTGTAAAACAAAATCTTTGGGAGCTTTCTCTTTTAATATATTGAGGGCCTGTGCTTTTGACCCTGAATTGATTGCCTCGGCATATGCGTCGTTGGCAGATTGGCAACCTCCTCTAGCTGATCTTCCATCGACTTGGAAAACTCCATGATCAAGGATGTCTCCGTCTTTCTCCATGTAGGTTTTAACATCACTTGAGCTTTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGAGGTAAGGTCGAAGAATCTATTGTTCCTGCACTGGAATTTTCCTTCGAACTGGATGAGAACATGCAAGTGAGGAGTCCCATCTTCGTGAAGCTCTCTGCAGATTCTAATGAATTTTTTAGAAGTTGGGGTTTCGAGATTTAATAATTGGGAAAGTGCTTCTTCTTTAGTTAGAGAGCACTTGGGATAAGTGAGAAAATAATTTTTGGCATTTATTTTAAACCGATTGGTGGCTGCCATGTTGACTAAGTCAATCGGTGTCTCTCAATCTTTTCTATGTATCGGTGTATCGGAGTCCTATATATATGGAGACTCTAATGGCATAATTGTAATTTGGTAAAGTGTGCTTTAATTCAAAATCCTCACGCTCCAAAAGCGGCCATCCGTATAATATT
Gene Information
| NCBI Accession | NP_148951.1 |
|---|---|
| Location | 129-476 |
| Gene Name | V2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCTCTTTTAAACGAGTTCCCCGATACGGTTCACGGATTCCGGTGTATGCTTGCTGTAAAATACTTACAGCTCGTAGAAAATACGTATTCACCTGATTCGTTGGGTTACGATCTAATTCGTGATTTAATCTCAGTTATTAGGGCTAAGAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCATCGAAGGTGCGTCGCCGTCTCAACTTCGAGACCCCGTACACGAGCCGTGTAGCTGTCCCCACTGTCCGCGTCACAAAGTCACGAGCATGGGCCAACAGGCCCATGAATCGGAAACCCAGAATATACAGAATGTACAGAAGTCCTGA |
| Protein Sequence | MWDPLLNEFPDTVHGFRCMLAVKYLQLVENTYSPDSLGYDLIRDLISVIRAKNYVEATSRYNHFHSRIEGASPSQLRDPVHEPCSCPHCPRHKVTSMGQQAHESETQNIQNVQKS |
| NCBI Accession | NP_148952.1 |
|---|---|
| Location | 289-1059 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGCAGATATAATCATTTCCACTCCCGCATCGAAGGTGCGTCGCCGTCTCAACTTCGAGACCCCGTACACGAGCCGTGTAGCTGTCCCCACTGTCCGCGTCACAAAGTCACGAGCATGGGCCAACAGGCCCATGAATCGGAAACCCAGAATATACAGAATGTACAGAAGTCCTGATGTTCCCAGAGGATGCGAAGGCCCATGTAAGGTTCAGTCGTTCGAGTCTAGACATGACATATCCCATATTGGGAAGGTAATGTGTATTAGTGATGTCACCCGTGGAATTGGGCTAACTCATAGGGTCGGTAAGAGGTTTTGTGTTAAGTCCGTATATGTATTGGGCAAGGTGTGGATGGATGAGAGTATCAAAACTAAGAATCACACGAATAGTGTGATGTTTTTTTTGTGTCGTGACAGGAGGCCTGTTGACAAACCCCAGGATTTTGGTGAGGTGTTTAATATGTTTGATAATGAGCCCAGTACTGCAACTGTGAAGAATGTTTTTCGTGATCGCTACCAAGTATTGAGGAAATGGCACGCAACTGTCACTGGTGGAACCTATGCGTCCAAGGAGCAGGCTTTGGTTAAGAAGTTTGTTAGGGTTAATAATTATGTTGTTTATAACCAGCAAGAGGCTGGGAAGTATGAGAATCATAGTGAGAATGCTTTGATGTTGTATATGGCGTCTACGCACGCCTCTAATCCTGTGTATGCTACATTGAAGATACGGATCTATTTTTATGATTCTGTATCTAATTAA |
| Protein Sequence | MSKRPADIIISTPASKVRRRLNFETPYTSRVAVPTVRVTKSRAWANRPMNRKPRIYRMYRSPDVPRGCEGPCKVQSFESRHDISHIGKVMCISDVTRGIGLTHRVGKRFCVKSVYVLGKVWMDESIKTKNHTNSVMFFLCRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVFRDRYQVLRKWHATVTGGTYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMASTHASNPVYATLKIRIYFYDSVSN |
| NCBI Accession | NP_148953.1 |
|---|---|
| Location | 1056-1460 |
| Gene Name | C3 |
| Protein Name | C3 |
| Coding Region | ATGGATTCTCGCACAGGGGAGTACATCAATGCAGCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATACAAAATCCCCTTTATTTCAAGATAACGGAGCACCACAACCGCGCATTCCTTCAGAATCACGACATAATCACAATGCAGATCCAATTCAATCACAACCTGAGGAAGGCATTGGGGATTCACAAGTGTTTTCTAATCTTCCGAATCTGGATGACTTCACAACCTCAGACTGGTCGTTTCTTAAGGGTCTTTAAGAACCAAGCACTTAAATATTTAGATAGTTTAGGGGTTATTAGTTTAAACAATGTAATTAGAGCAGTAGATCATGTTTTATGGGATGTATTGCATCACATTTTGTACGTTGAACAATCACATTCAATAAAATTCAATATTTATTAA |
| Protein Sequence | MDSRTGEYINAAQAENGVYIWEIQNPLYFKITEHHNRAFLQNHDIITMQIQFNHNLRKALGIHKCFLIFRIWMTSQPQTGRFLRVFKNQALKYLDSLGVISLNNVIRAVDHVLWDVLHHILYVEQSHSIKFNIY |
| NCBI Accession | NP_148954.1 |
|---|---|
| Location | 1201-1605 |
| Gene Name | C2 |
| Protein Name | C2 |
| Coding Region | ATGCGACCTTCGTCACCCTCGAAGAGCCACTCTACTCAGGTACCCATCAAAGTCCAACACAGGTTAGCGAAGAAGAGCAACAGACGTCGGAGGGTTGATCTACCCTGTGGATGCTCATACTTCATAGCCCTAGCCTGTCATAACCATGGATTCTCGCACAGGGGAGTACATCAATGCAGCTCAAGCAGAGAATGGCGTGTATATCTGGGAGATACAAAATCCCCTTTATTTCAAGATAACGGAGCACCACAACCGCGCATTCCTTCAGAATCACGACATAATCACAATGCAGATCCAATTCAATCACAACCTGAGGAAGGCATTGGGGATTCACAAGTGTTTTCTAATCTTCCGAATCTGGATGACTTCACAACCTCAGACTGGTCGTTTCTTAAGGGTCTTTAA |
| Protein Sequence | MRPSSPSKSHSTQVPIKVQHRLAKKSNRRRRVDLPCGCSYFIALACHNHGFSHRGVHQCSSSREWRVYLGDTKSPLFQDNGAPQPRIPSESRHNHNADPIQSQPEEGIGDSQVFSNLPNLDDFTTSDWSFLKGL |
| NCBI Accession | NP_148955.1 |
|---|---|
| Location | 1508-2593 |
| Gene Name | C1 |
| Protein Name | replication-associated protein |
| Coding Region | ATGGCAGCCACCAATCGGTTTAAAATAAATGCCAAAAATTATTTTCTCACTTATCCCAAGTGCTCTCTAACTAAAGAAGAAGCACTTTCCCAATTATTAAATCTCGAAACCCCAACTTCTAAAAAATTCATTAGAATCTGCAGAGAGCTTCACGAAGATGGGACTCCTCACTTGCATGTTCTCATCCAGTTCGAAGGAAAATTCCAGTGCAGGAACAATAGATTCTTCGACCTTACCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAAGTGATGTTAAAACCTACATGGAGAAAGACGGAGACATCCTTGATCATGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCAAAAGCACAGGCCCTCAATATATTAAAAGAGAAAGCTCCCAAAGATTTTGTTTTACAATTTCATAACTTAAATTCAAATTTAGATAGGATTTTTACACCTCCAATGGAGGTTTATGTTTCCCCTTTTTTATCTTCTTCTTTCGACCAAGTTCCAGAAGAACTTGAAGAGTGGGCATGTGAAAACGTTGTCAGTGCCGCTGCGCGGCCTATCAGGCCCATTAGTATTGTAATTGAGGGTGATAGTCGTACCGGAAAAACAATGTGGGCCAGGTCACTAGGACCACACAATTATTTGTGCGGTCATCTCGACCTGAGTCCAAAAGTGTACAGTAATGATGCCTGGTATAACGTCATTGATGACGTCGATCCGCACTATCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGAGACTGGCAAAGCAACACCAAGTACGGGAAACCTGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCCAATTCAAGCTATAAAGAGTATCTGGATGAAGAGAAAAACAGTGCGCTTAAAAACTGGGCTCTGAAGAATGCGACCTTCGTCACCCTCGAAGAGCCACTCTACTCAGGTACCCATCAAAGTCCAACACAGGTTAGCGAAGAAGAGCAACAGACGTCGGAGGGTTGA |
| Protein Sequence | MAATNRFKINAKNYFLTYPKCSLTKEEALSQLLNLETPTSKKFIRICRELHEDGTPHLHVLIQFEGKFQCRNNRFFDLTSPTRSAHFHPNIQGAKSSSDVKTYMEKDGDILDHGVFQVDGRSARGGCQSANDAYAEAINSGSKAQALNILKEKAPKDFVLQFHNLNSNLDRIFTPPMEVYVSPFLSSSFDQVPEELEEWACENVVSAAARPIRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEYLDEEKNSALKNWALKNATFVTLEEPLYSGTHQSPTQVSEEEQQTSEG |
| NCBI Accession | NP_148956.1 |
|---|---|
| Location | 2143-2436 |
| Gene Name | C4 |
| Protein Name | C4 |
| Coding Region | ATGGGACTCCTCACTTGCATGTTCTCATCCAGTTCGAAGGAAAATTCCAGTGCAGGAACAATAGATTCTTCGACCTTACCTCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAAAGCTCAAGTGATGTTAAAACCTACATGGAGAAAGACGGAGACATCCTTGATCATGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAATTCAGGGTCAAAAGCACAGGCCCTCAATATATTAA |
| Protein Sequence | MGLLTCMFSSSSKENSSAGTIDSSTLPPQPGQHISIRTFRELKAQVMLKPTWRKTETSLIMEFSKSMEDQLEEVANLPTTHMPRQSIQGQKHRPSIY |
References More References in PubMed
| 1 |
Saunders K, et al. Virology. 2002 Feb 1;293(1):63-74. doi: 10.1006/viro.2001.1251. PMID: 11853400 |
|---|---|
| 2 |
Venkataravanappa V, et al. Microb Pathog. 2023 Jul;180:106127. doi: 10.1016/j.micpath.2023.106127. Epub 2023 Apr 28. PMID: 37119939 |
| 3 |
Molecular characterization of a new begomovirus infecting Synedrella nodiflora in South India. Das S, et al. Arch Virol. 2018 Sep;163(9):2551-2554. doi: 10.1007/s00705-018-3861-3. Epub 2018 May 9. PMID: 29744588 |