Kudzu mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000870965.1 |
| Isolate | Viet Nam: Hoabinh |
| Release date | 2015/2/13 |
| Submitter | Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
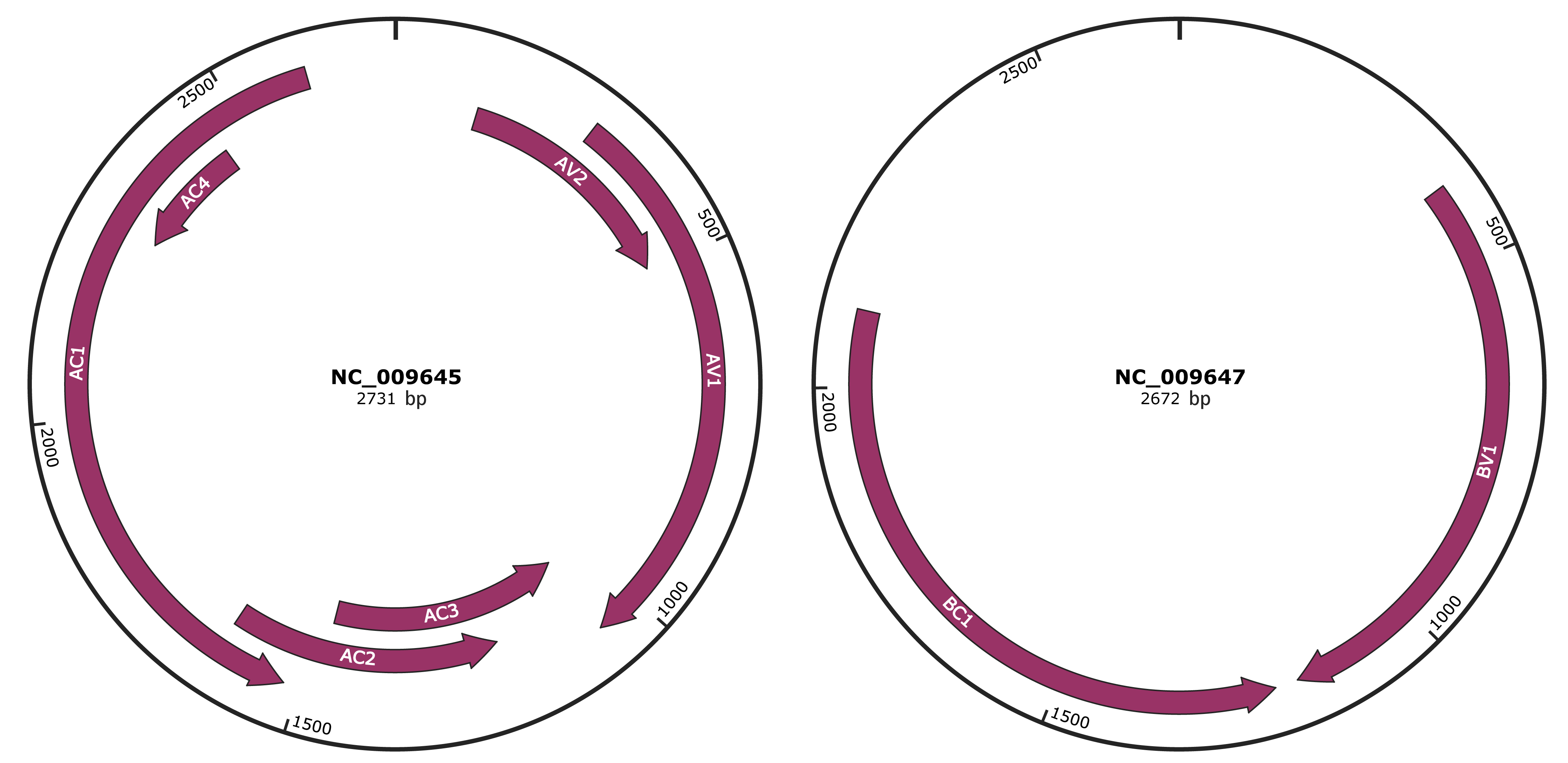
JBrowse
Genome
NC_009645
NC_009647
Gene Information
| NCBI Accession | YP_001333676.1 |
|---|---|
| Location | 128-496 |
| Gene Name | AV2 |
| Protein Name | AV2 protein |
| Coding Region | ATGTGGGATCCTTTGTTGAACGCCTTTCCGGACAGGTTGCATGGATTCCGCTGCATGTTAGCAGTGAAGTACTTGCACTTAGTGCTGCCAACATATCCCGAGAATACCGTAGGGTATTGGTTTTTGCGTGATTTGATACAGGTATTACGCTCCAAGGATCATGACAAAGCGGAATTTCGAGACGGCGTTCTCAAGTCCGATATCCTCGGCACGGCGGAGACTGAGCTACGGAACCCCGTTAGCGTTGCCTGCACCTGCTGCCAGTGCCCAAGGCACCCGAAGACGACGATCATGGACAAACCGTCCGATGTACAGGAAGCCTCGTCTGTATCGTATGTATCGAAGCCCAGACGTCCCCCGCGGTTGTGA |
| Protein Sequence | MWDPLLNAFPDRLHGFRCMLAVKYLHLVLPTYPENTVGYWFLRDLIQVLRSKDHDKAEFRDGVLKSDILGTAETELRNPVSVACTCCQCPRHPKTTIMDKPSDVQEASSVSYVSKPRRPPRL |
| NCBI Accession | YP_001333677.1 |
|---|---|
| Location | 288-1061 |
| Gene Name | AV1 |
| Protein Name | CP protein |
| Coding Region | ATGACAAAGCGGAATTTCGAGACGGCGTTCTCAAGTCCGATATCCTCGGCACGGCGGAGACTGAGCTACGGAACCCCGTTAGCGTTGCCTGCACCTGCTGCCAGTGCCCAAGGCACCCGAAGACGACGATCATGGACAAACCGTCCGATGTACAGGAAGCCTCGTCTGTATCGTATGTATCGAAGCCCAGACGTCCCCCGCGGTTGTGAGGGCCCTTGTAAGGTTCAATCTTTTGAACAAAGGCATGATATTTCTCATGTGGGGAAAGTACTTTGTGTTTCTGACGTCACTCGTGGTGGTGGTATCACTCACCGAGTTGGCAAGCGTTTTTGCATTAAGTCTATCTATGTTTCAGGTAAAGTTTGGGTGGATGAAAACATCAAGCTCAAGAATCACACCAACAGTGTGCTATTCTGGTTGACTCGTGATAGGCGACCTTTTGGTACGCCAATGGATTTTGGTCAAGTTTTTAACATGTATGACAATGAGCCTAGTACTGCCACCGTGAAGAACGACCTACGTGATCGTTACCAGGTCCTGCATCGATGGAATGCCACCGTTACTGGTGGCCAATATGCCTGTAAGGAACAGGCGTTAATTAGGCGTTTTTATAAAGTTTATAATCATGTTGTGTATAATCATCAGGAAGCTGCAAAGTATGAAAACCATACTGAGAATGCTCTGTTGTTGTATATGGCATGTACTCATGCATCAAACCCAGTGTACGCAACATTGAAGATACGGATCTATTTTTACGATTCGATATCAAATTAA |
| Protein Sequence | MTKRNFETAFSSPISSARRRLSYGTPLALPAPAASAQGTRRRRSWTNRPMYRKPRLYRMYRSPDVPRGCEGPCKVQSFEQRHDISHVGKVLCVSDVTRGGGITHRVGKRFCIKSIYVSGKVWVDENIKLKNHTNSVLFWLTRDRRPFGTPMDFGQVFNMYDNEPSTATVKNDLRDRYQVLHRWNATVTGGQYACKEQALIRRFYKVYNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
| NCBI Accession | YP_001333678.1 |
|---|---|
| Location | 1058-1474 |
| Gene Name | AC3 |
| Protein Name | REn protein |
| Coding Region | ATGGATTTACGCACAGGGGTGAGCATCACTGCAGCTCAGCTAGAGAATGGCGTCTTTACTTGGGAGGTAGCAAATCCCCTGAGTTTCAAGATCATGGACCACGACAGAGTATGGTACCACAACCTCATCCAGTGGCCAAAGTTCCGGACAACAATCCGCATAATGTTCAACCACTCTCTGAAGAAAGCGTTGGGGATACACAAGGCCTTCCTGGACTTGACGATTTACCATCGTTTCATACAGCCGAGTGGGCGGATTTGCTCGACTTTTAAGAACCAATTATTACGTTATATTAATAATTTAGGAGTTATTAGTCTATCGACTGTATTAAAAGCGTGTTCGCATGTATTGTTTACTGTATTTGAACATGTTGATGATGTAACGCTCAAGCATAATGTGCAATACAAGCTTTATTAA |
| Protein Sequence | MDLRTGVSITAAQLENGVFTWEVANPLSFKIMDHDRVWYHNLIQWPKFRTTIRIMFNHSLKKALGIHKAFLDLTIYHRFIQPSGRICSTFKNQLLRYINNLGVISLSTVLKACSHVLFTVFEHVDDVTLKHNVQYKLY |
| NCBI Accession | YP_001333679.1 |
|---|---|
| Location | 1203-1622 |
| Gene Name | AC2 |
| Protein Name | TrAP protein |
| Coding Region | ATGCTATCTTCTACACGCTCACAGAACCCCTGTTCTCCACCACCAATCAAGGCGCAACACAGGTTGGCCAAGAAACGTGCAATTCGACGCAGACGAATTGACCTGAAGTGTGGGTGTAGTTACTACCTACACATCAACTGCTACAACCATGGATTTACGCACAGGGGTGAGCATCACTGCAGCTCAGCTAGAGAATGGCGTCTTTACTTGGGAGGTAGCAAATCCCCTGAGTTTCAAGATCATGGACCACGACAGAGTATGGTACCACAACCTCATCCAGTGGCCAAAGTTCCGGACAACAATCCGCATAATGTTCAACCACTCTCTGAAGAAAGCGTTGGGGATACACAAGGCCTTCCTGGACTTGACGATTTACCATCGTTTCATACAGCCGAGTGGGCGGATTTGCTCGACTTTTAA |
| Protein Sequence | MLSSTRSQNPCSPPPIKAQHRLAKKRAIRRRRIDLKCGCSYYLHINCYNHGFTHRGEHHCSSAREWRLYLGGSKSPEFQDHGPRQSMVPQPHPVAKVPDNNPHNVQPLSEESVGDTQGLPGLDDLPSFHTAEWADLLDF |
| NCBI Accession | YP_001333680.1 |
|---|---|
| Location | 1522-2610 |
| Gene Name | AC1 |
| Protein Name | rep protein |
| Coding Region | ATGTCTAGACCAAAGGGTTTTCGGGTTAATGCCAAAAACTTCTTCCTCACATACCCAAGGTGTTCTCTCTCTAAAGAAGCAGCACTAGAGCAGCTACAGAATATTCAGACTAACGTCAACAAGAAATTCATCAGAGTTTGTCGTGAGTTCCATGAAAATGGGGAACCTCACCTCCATGTTCTGCTTCAATTTGAAGGAAAATTCCAGTGCCGCAACGAAAGGTTCTTCGACCTCGTATCCGAAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCAGCTCAGATGTTAAAAAGTACATGGAGAAAGACGGAGACGTCATAGATTTTGGAATTTTCCAGATCGACGGGAGATCAAATAGAGGAGGTTCTCAATGTGCAAATGACGCATATGCCGAAGCAATCAATTCAGGCGATACAACATCGGCCCTCAATATATTGAAGGAGAAAGCGTCGAGAGACTTCATAATCCATTTGCACAATATCAGAGCCAATCTGAACTTTCTTTTTGCACCACCGCCAACAGTGTATGAAACACCATTCAGTATTGAATCATTCAATAATGTCCCTGAGACATTGACGTCATGGGCAGCTGAAAACGTGGTGTGCCCCGCTGCGCGGCCATTCAGACCTATTAGTATAGTGGTTGAGGGTGAGTCACGTACGGGTAAAACCATGTGGGCGAGGTCGCTCGGTCGGCACAATTATTTGTGCGGCCATTTGGATCTAAGCGCCAAAGTTTATTCAAATGATGCGTGGTACAACGTAATCGATGACGTCGATCCGCATTATCTGAAACATTTCAAAGAATTCATGGGCGCGCAAAAGGACTGGCAAAGCAACGTGAAATACGGAAAGCCCACTCAAATTAAAGGTGGCATCCCCACCATCTTTCTCTGTAATGCGGGACCCAGATCCTCTTATAAAATGTTCCTCGACGAAGAGAATAATGCGAGTCTCAAAGAGTGGGCTTTAAAAAATGCTATCTTCTACACGCTCACAGAACCCCTGTTCTCCACCACCAATCAAGGCGCAACACAGGTTGGCCAAGAAACGTGCAATTCGACGCAGACGAATTGA |
| Protein Sequence | MSRPKGFRVNAKNFFLTYPRCSLSKEAALEQLQNIQTNVNKKFIRVCREFHENGEPHLHVLLQFEGKFQCRNERFFDLVSETRSAHFHPNIQGAKSSSDVKKYMEKDGDVIDFGIFQIDGRSNRGGSQCANDAYAEAINSGDTTSALNILKEKASRDFIIHLHNIRANLNFLFAPPPTVYETPFSIESFNNVPETLTSWAAENVVCPAARPFRPISIVVEGESRTGKTMWARSLGRHNYLCGHLDLSAKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQKDWQSNVKYGKPTQIKGGIPTIFLCNAGPRSSYKMFLDEENNASLKEWALKNAIFYTLTEPLFSTTNQGATQVGQETCNSTQTN |
| NCBI Accession | YP_001333681.1 |
|---|---|
| Location | 2277-2459 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAAATGGGGAACCTCACCTCCATGTTCTGCTTCAATTTGAAGGAAAATTCCAGTGCCGCAACGAAAGGTTCTTCGACCTCGTATCCGAAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCAGCTCAGATGTTAAAAAGTACATGGAGAAAGACGGAGACGTCATAG |
| Protein Sequence | MKMGNLTSMFCFNLKENSSAATKGSSTSYPKPGQHISIRTFRELRAAQMLKSTWRKTETS |
| NCBI Accession | YP_001333682.1 |
|---|---|
| Location | 395-1174 |
| Gene Name | BV1 |
| Protein Name | NSP protein |
| Coding Region | ATGTTAGCCATGTTTACCCCTCGAGCAACCCCCCGTAATTATCCCCGTCGTGTCAGTGGGCAATTTAAGCGTAAATTACGCCCATACAATGGGGGTCTTAACACGTATCGTAAACTGCGTGTTGCTCGCAAGTTATCCTACGATCCATCTGTCCGTCCGTTCTCTATAAATACACTAGTTGAACGGCAACATGGTTCACATATGACCCTTGGAAGTAATTCGGATATTACTTCATTTGTTGAATATCCAGTTCGTGGTATTAATGGCGATGGTCGTTCAAGGGATTACATCAAATTGCTTCATTTATCAGCCTCAGGCGTTATTAACGTTAAGGTTGCCTCTTCGGATCAAGTAATGGATGGTGGTTCTCGTCACAACGGCGTATTTGTTATGTGTTTACTTCAGGACATGAAGCCGTTTTTACCTGACGGCGTCAATAGCTTGCCAACGTATGCCGAGTTATTCGGGCCTTATTCGTCTGCTTATGTTAATATGCATTTGTTGGATAGCCATAAACAGCGTTTTAGGATTTTAGGTAGCGTAAAAAAATTTGTAAGTTGTGGTTTGGATGCGGTAGACATCCCTTTCAAGTTAGACCTTAAGCTATCCAACGGGAGGTATCCATTGTGGGCGTCATTTAAAGACGCTGAAGAGGGTAATTGTGGGGGCAATTATAGAAATATTGCCAAAAATGCAATAATTGTAAGCTATGCATTTGTTTCATTGCATAGCCTTAAGTGTGAACCATTTGTACAATTTGAACTCCGTTACATGGGATAA |
| Protein Sequence | MLAMFTPRATPRNYPRRVSGQFKRKLRPYNGGLNTYRKLRVARKLSYDPSVRPFSINTLVERQHGSHMTLGSNSDITSFVEYPVRGINGDGRSRDYIKLLHLSASGVINVKVASSDQVMDGGSRHNGVFVMCLLQDMKPFLPDGVNSLPTYAELFGPYSSAYVNMHLLDSHKQRFRILGSVKKFVSCGLDAVDIPFKLDLKLSNGRYPLWASFKDAEEGNCGGNYRNIAKNAIIVSYAFVSLHSLKCEPFVQFELRYMG |
| NCBI Accession | YP_001333683.1 |
|---|---|
| Location | 1206-2102 |
| Gene Name | BC1 |
| Protein Name | MP protein |
| Coding Region | ATGGAGACATACTCTGGAGCACTGGTCACAAACAAGTATATTCAATCAAAGCGATGCGAATACCGTCTGACAAACAACGAAACTCCAATTACTCTTCAATTTCCGTCGTCAATAGAACAAGCAGCAGTTAAAATGCTGGGAAAATGCATGAAGGTTGACCATATAGTAATTGAGTATCGTAACCAAGTACCTTACAATGCAACTGGAAGTGTCATCGTCACTATACGTGACACAAGATTAAGCGATGATCAGGCTGCACAGGCAGCTTTCACATTCCCCATTGGATGTAACGTAGATCTGCATTACTTTTCATCCTCATTTTTCTCCATCAAAGATGAGACGCCATGGGAGCTTCTATACAAAGTAGAAGACTCAAACGTCAACGACGGCACAGCATTTGCCCAAATAAAGGGCAAGTTGAAGTTATCGGCGGCAAAACATTCGACAGACATTAAATACAAACCGCCAACAATAAAAATATTGTCCAAAGACTACACAGCGGATTGCGTGGACTTTTGGTCTGTCGAGAGGCCCAAACCCATCAGAAGACTATTAACACCAACGCCAGGATGTGGTCCTGATGGGCTACAGCGCCAAAGGCCCATGTTATTACAGCCTGGGGAGACATGGGCCACACGGTCCACAATTGGACGCAGCACGTCAATGCGGTATCCAGACAACAATATAATGGGCCTTGAGCACAGGACAATCTCGTCCGACGCAGAATTTCCTCTAAAACACATGCACAAATTACCTGAGTCGTCATTAGACCCGGGAGACTCAGTCTCACAGGCGCAAACCAATCCGGTTACAAGAGCGGACATCGAGAGCATTATCGAAACAACCATTAACAGGTGTTTGGTTACGCAGAGATCAAATGTATCCAAACCATTGTAA |
| Protein Sequence | METYSGALVTNKYIQSKRCEYRLTNNETPITLQFPSSIEQAAVKMLGKCMKVDHIVIEYRNQVPYNATGSVIVTIRDTRLSDDQAAQAAFTFPIGCNVDLHYFSSSFFSIKDETPWELLYKVEDSNVNDGTAFAQIKGKLKLSAAKHSTDIKYKPPTIKILSKDYTADCVDFWSVERPKPIRRLLTPTPGCGPDGLQRQRPMLLQPGETWATRSTIGRSTSMRYPDNNIMGLEHRTISSDAEFPLKHMHKLPESSLDPGDSVSQAQTNPVTRADIESIIETTINRCLVTQRSNVSKPL |
References More References in PubMed
| 1 |
First Report of Kudzu mosaic virus on Pueraria montana (Kudzu) in China. Zhang J, et al. Plant Dis. 2013 Jan;97(1):148. doi: 10.1094/PDIS-07-12-0671-PDN. PMID: 30722297 |
|---|---|
| 2 |
Three new isoflavones from the Pueraria montana var. lobata (Willd.) and their bioactivities. Cui T, et al. Nat Prod Res. 2018 Dec;32(23):2817-2824. doi: 10.1080/14786419.2017.1385008. Epub 2017 Oct 12. PMID: 29022354 |
| 3 |
First Report of Tobacco ringspot virus Infecting Kudzu (Pueraria montana) in Louisiana. Khankhum S, et al. Plant Dis. 2013 Apr;97(4):561. doi: 10.1094/PDIS-10-12-0933-PDN. PMID: 30722248 |
| 4 |
Aboughanem-Sabanadzovic N, et al. Viruses. 2023 Oct 25;15(11):2145. doi: 10.3390/v15112145. PMID: 38005823 |
| 5 |
Mixed infection of an emaravirus, a crinivirus, and a begomovirus in Pueraria lobata (Willd) Ohwi. Liang X, et al. Front Microbiol. 2022 Sep 29;13:926724. doi: 10.3389/fmicb.2022.926724. eCollection 2022. PMID: 36246248 |
| 6 |
Two new 'legumoviruses' (genus Begomovirus) naturally infecting soybean in Nigeria. Alabi OJ, et al. Arch Virol. 2010 May;155(5):643-56. doi: 10.1007/s00705-010-0630-3. Epub 2010 Mar 13. PMID: 20229118 |
| 7 |
Complete genome sequence of pueraria virus A, a new member of the genus Caulimovirus. Gudeta WF, et al. Arch Virol. 2022 Jun;167(6):1481-1485. doi: 10.1007/s00705-022-05431-9. Epub 2022 Apr 22. PMID: 35451686 |
| 8 |
Monde G, et al. Arch Virol. 2010 Nov;155(11):1865-9. doi: 10.1007/s00705-010-0772-3. Epub 2010 Aug 1. PMID: 20680361 |