Jatropha mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000919175.1 |
| Isolate | Jamaica: Spanish Town |
| Release date | 2015/2/22 |
| Submitter | Simmonds-Gordon,R., Collins-Fairclough,A., Stewart,C., Roye,M. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
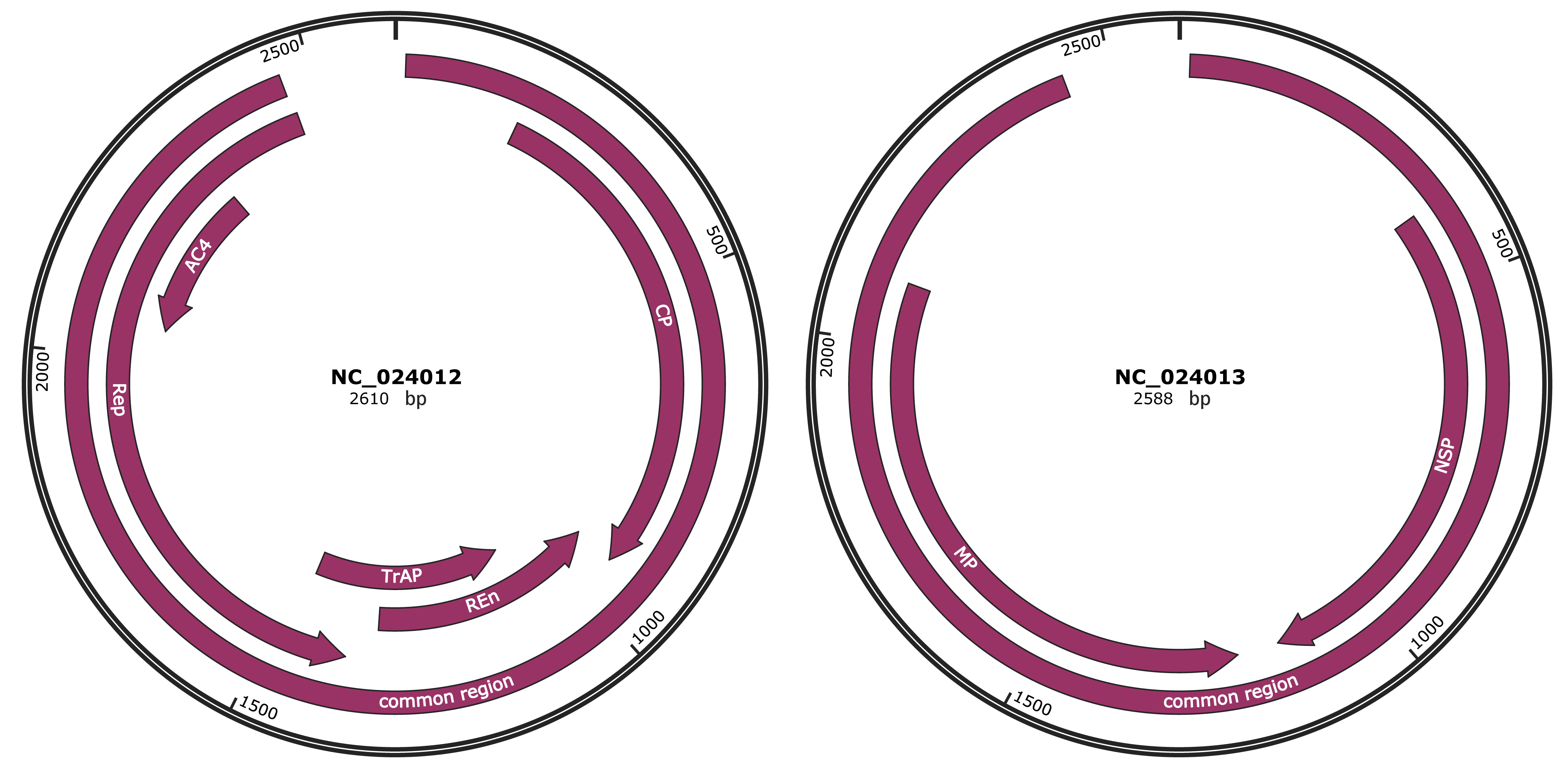
JBrowse
Genome
NC_024012
NC_024013
Gene Information
| NCBI Accession | YP_009026400.1 |
|---|---|
| Location | 183-938 |
| Gene Name | CP |
| Protein Name | coat protein |
| Coding Region | ATGCCTAAGCGGGATGCCCCATGGCGTTCAATGGCGGGAACGTCCAAGGTTAGTCGCAATGCCAATTATTCTCCTCGATCAGGCATTACCCAGAAGTCCAGCAAGGCCCAGGAATGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATCTACCGGACGCTGAGGACGCCCGATGTGCCCAGAGGCTGTGAAGGGCCTTGCAAGGTCCAGTCTTATGAACAGCGCCACGACATCTCACATGTGGGCAAGGTCATGTGCATATCTGACGTGACACGTGGTAGTGGCATTACCCATCGTGTGGGTAAGCGTTTCTGTGTTAAGTCTGTGTATATATTAGGGAAGATATGGATGGACGAGAATATCAAGCTCAAGAACCACACGAACTGCGTCATGTTCTGGTTGGTCAGAGACCGTAGACCCTATGGCACGCCCATGGATTTTGGCCAGGTGTTCAACATGTTCGACAACGAGCCCAGTACTGCCACGGTTAAGAACGATCTGCGTGATCGTTACCAGGTCATGCACCGGTTCTACGCCAAGGTCACGGGTGGACAGTATGCCAGCAACGAGCAGGCGATTGTTAAGCGGTTCTGGAAGGTCAACAATCATGTGGTCTACAACCACCAGGAGGCTGGCAAGTACGAGAACCACACCGAGAACGCCCTGTTATTGTATATGGCATGTACTCATGCCTCTAACCCCGTGTATGCAACTCTGAAGATTCGAATCTATTTTTATGATTCGGTCACCAATTAA |
| Protein Sequence | MPKRDAPWRSMAGTSKVSRNANYSPRSGITQKSSKAQEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGSGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNCVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRYQVMHRFYAKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | YP_009026401.1 |
|---|---|
| Location | 935-1333 |
| Gene Name | REn |
| Protein Name | REn |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCACATCAGGCAGAGAATGGCGCGTATACCTGGGAGATAGAAAATCCCCTGTATTTCAGAATATACAGAGTAGAGGACATGCTATACACCAGGACACGAGTATACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCTTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGAACGACTTATTTGCTTAGGTTTAGGCACTTAGTCAATATGTACTTAGATCAATTAGGCGTGATTTCCATTAACAATGTAATTAGAGCTGTTCGTTTCGCGACAGACAGACCATATGTAAATCATGTACTGGAAAATCACTCAATAAAATTCAATATTTATTAA |
| Protein Sequence | MDSRTGEPITAHQAENGAYTWEIENPLYFRIYRVEDMLYTRTRVYHIQIRFNHNLRRALDLHKAYLNFQVWTTSTTASGTTYLLRFRHLVNMYLDQLGVISINNVIRAVRFATDRPYVNHVLENHSIKFNIY |
| NCBI Accession | YP_009026402.1 |
|---|---|
| Location | 1080-1469 |
| Gene Name | TrAP |
| Protein Name | TrAP |
| Coding Region | ATGCGATCTTCGTCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGAGACGCATTGATATAGAGTGCGGGTGCTCCATATACGTTCATCTCGACTGCAGGGGACATGGATTCACGCACAGGGGAACCCATCACTGCACATCAGGCAGAGAATGGCGCGTATACCTGGGAGATAGAAAATCCCCTGTATTTCAGAATATACAGAGTAGAGGACATGCTATACACCAGGACACGAGTATACCACATCCAGATACGGTTCAACCACAACCTGAGGAGAGCGTTGGATCTCCACAAGGCTTACCTGAACTTCCAAGTCTGGACGACATCGACGACAGCTTCTGGAACGACTTATTTGCTTAG |
| Protein Sequence | MRSSSPSQPPSIKKAHRQAKRRAIRRRRIDIECGCSIYVHLDCRGHGFTHRGTHHCTSGREWRVYLGDRKSPVFQNIQSRGHAIHQDTSIPHPDTVQPQPEESVGSPQGLPELPSLDDIDDSFWNDLFA |
| NCBI Accession | YP_009026403.1 |
|---|---|
| Location | 1381-2466 |
| Gene Name | Rep |
| Protein Name | Rep |
| Coding Region | ATGCCACGAAAGGGTTCTTTCTCAATTAAAGCCAAAAACTATTTCCTCACTTATCCCCAGTGCTCTCTTACCAAAGAAGAAGCACTTTCACAATTACAAAACCTAAATACTCCGATAAACAAAAAGTTCATCAAAATCTGCAGAGAGCTTCATGAGAATGGGCAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGGAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACACGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGACGAAGTGCTAGGGGAGGCTGCCAATCTGCTAATGATTCATATGCCAAGGCGTTAAATGCAGATTCTGTTCAATCTGCCATGGCGATTTTAAAAGAAGAACAGCCAAAAGATTTCGTCTTGCAGAATCATAACATCCGCTCCAATCTCGAAAGAATATTCGCAAAGGCTCCGGAACCGTGGGTCCCTCCGTTTCCACTCTCCTCTTTCACTAACGTTCCGGACGAGATGCAAGAATGGGCGGATGATTATTTTGGAAGGGGTTCCGCTGCGCGGCCGGAGAGACCTATAAGTGTCATAGTCGAAGGTGATTCACGGACAGGGAAGACGATGTGGGCTCGTGCGTTAGGCCCACATAACTATCTCAGTGGACACTTAGACTTCAATCACCGGGTCTACTCAAACGACGTGGAGTATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAAGAATTGCTGGGGGCCCAAAAAAACTGGCAGTCAAATTGCAAATACGGAAAGCCAGTTCAAATTAAAGGCGGCATCCCAGCAATCGTGCTCTGCAATCCTGGTGAGGGTGCCAGCTATAAAGATTTCCTAGACAAAGAGGAAAATTCATCACTCAGGAACTGGACTATCAAGAATGCGATCTTCGTCACCCTCACAGCCCCCCTCTATCAAGAAGGCACACAGGCAAGCCAAGAGGAGGGCCATCAGGAGGAGACGCATTGA |
| Protein Sequence | MPRKGSFSIKAKNYFLTYPQCSLTKEEALSQLQNLNTPINKKFIKICRELHENGQPHLHVLIQFEGKYNCTNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTLEWGEFQIDGRSARGGCQSANDSYAKALNADSVQSAMAILKEEQPKDFVLQNHNIRSNLERIFAKAPEPWVPPFPLSSFTNVPDEMQEWADDYFGRGSAARPERPISVIVEGDSRTGKTMWARALGPHNYLSGHLDFNHRVYSNDVEYNVIDDVAPHYLKLKHWKELLGAQKNWQSNCKYGKPVQIKGGIPAIVLCNPGEGASYKDFLDKEENSSLRNWTIKNAIFVTLTAPLYQEGTQASQEEGHQEETH |
| NCBI Accession | YP_009026404.1 |
|---|---|
| Location | 2052-2315 |
| Gene Name | AC4 |
| Protein Name | AC4 |
| Coding Region | ATGAGAATGGGCAGCCTCATCTCCATGTGCTCATACAGTTCGAAGGGAAGTACAACTGCACGAATAACAGATTCTTCGATCTGGTCTCCCCAACACGGTCAGCACATTTCCATCCGAACATACAGGGAGCTAAATCGAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGAGATACACTGGAATGGGGAGAATTCCAGATCGACGGACGAAGTGCTAGGGGAGGCTGCCAATCTGCTAATGATTCATATGCCAAGGCGTTAA |
| Protein Sequence | MRMGSLISMCSYSSKGSTTARITDSSIWSPQHGQHISIRTYRELNRAPTSSPTSTRTEIHWNGENSRSTDEVLGEAANLLMIHMPRR |
| NCBI Accession | YP_009026405.1 |
|---|---|
| Location | 392-1144 |
| Gene Name | NSP |
| Protein Name | NSP |
| Coding Region | ATGTATCCTATGAGGAATAAACGTGGTTTCTATTTTAGTCCACGTCGGTATTATCCACGTAATGCTGTGTTTAAGCGATCAACAACTTCGAAGAGATATGAGGGGAAACGACGACGTGTAGATGCTGGGAAGCCCAGTGATGAGCCGAAGATGCATGTTCAGTATGGGCCAGAGTTTGCCATGGCCCATAATTCAGCTATCTCGACCTATATCACCTACCCCAGCCTGGGTAAGACCGAGCCCAGTCGAAGCCGGTCCTATATTAAGTTGAGAGGGCTTCGTTTCAAAGGGACCGTGAAGATTGAACGTGTCCAAGCGGATGTGAACATGGACGGTTCGACGCCCAAGGTCGAAGGAGTGTTTTCTCTTGTCGTTGTCGTGGATCGCAAGCCTCACTTGGGTCCTTCTGGTTGCTTGCATACATTTGACGAGCTCTTCGGTGCTAGGATACACAGTCATGGTAACCTCAGCGTGACTCCCTCTTTGAAGGAGCGTTACTATATACGCCACGTGTGCAAACGTGTATTGTCCGTGGAGAAGGACACGCTGATGGTAGACGTGGAAGGATCCATTTCTCTCTCTAACAGGCGTTTCAACTGTTGGTCTACGTTTAAGGACGTGGATCGTGAATCATGCAACGGTGTTTATGATAATATCAGCAAGAACGCTCTGTTAGTCTATTATTGTTGGATGTCTGATACTGTGTCTAAGGCGTCAACTTTTGTATCTTATGACCTTGATTATGTCGGATGA |
| Protein Sequence | MYPMRNKRGFYFSPRRYYPRNAVFKRSTTSKRYEGKRRRVDAGKPSDEPKMHVQYGPEFAMAHNSAISTYITYPSLGKTEPSRSRSYIKLRGLRFKGTVKIERVQADVNMDGSTPKVEGVFSLVVVVDRKPHLGPSGCLHTFDELFGARIHSHGNLSVTPSLKERYYIRHVCKRVLSVEKDTLMVDVEGSISLSNRRFNCWSTFKDVDRESCNGVYDNISKNALLVYYCWMSDTVSKASTFVSYDLDYVG |
| NCBI Accession | YP_009026406.1 |
|---|---|
| Location | 1207-2088 |
| Gene Name | MP |
| Protein Name | MP |
| Coding Region | ATGGATTCTCAGTTAGCAAATCCTCCGAACGCCTTCAATTACATAGAGTCCCATCGGGACGAATACCAGCTTTCGCATGATCTAACTGAGATAGTACTGCAATTCCCTTCCACGGCGGCGCAATTAACAGCTAGACTCAGTCGTAGCTGCATGAAAATCGACCATTGCGTCATAGAATACAGACAACAAGTTCCGATCAACGCCGCCGGAACGGTGATAGTGGAGATCCACGACAAGCGAATGACGGACAACGAATCATTGCAGGCATCATGGACATTTCCGATCAGATGCAACATAGATCTCCACTATTTCTCGGCTTCGTTCTTCTCGCTAAAGGACCCAATTCCATGGAAGCTATACTACCGAGTATGCGACACCAATGTCCATCAGAGGACCCACTTCGCCAAATTCAAAGGGAAGCTGAAGTTGTCCACGGCAAAACACTCGGTCGACATCCCTTTCCGGGCACCAACAGTGAAGATCCTATCCAAACAGTTCACAGACAAGGACGTGGACTTCTCCCATGTCGACTATGGGAAATGGGAAAGGAAGCTCATCAGGTGCGCGTCCATGTCCAGAGTTGGGCTAAGAGGCCCAATCGAGATAAGGCCTGGAGAGTCATGGGCTTCCAGGAGCACAATAGGAGCTGGTCATTCGGACGCTGATTCAGAGATGGAAAACGAACTCCATCCATACAGGCACCTGAGCAGGCTTGGGACCAGCGTCCTAGATCCGGGAGAGTCTGCTTCGATAGTGGGGGCCCAAAGAGCCGAGTCCAATATCACAATGTCAATGGGCCAGTTGAATGAGCTAGTTAGGACTGCGGTCCAAGAATGTATTAATAATAATTGTCAGCCTTCTCAGGCCAAGTCGTTAAAATAA |
| Protein Sequence | MDSQLANPPNAFNYIESHRDEYQLSHDLTEIVLQFPSTAAQLTARLSRSCMKIDHCVIEYRQQVPINAAGTVIVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSASFFSLKDPIPWKLYYRVCDTNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDVDFSHVDYGKWERKLIRCASMSRVGLRGPIEIRPGESWASRSTIGAGHSDADSEMENELHPYRHLSRLGTSVLDPGESASIVGAQRAESNITMSMGQLNELVRTAVQECINNNCQPSQAKSLK |
References More References in PubMed
| 1 |
First Report of Cucumber mosaic virus on Jatropha curcas in India. Raj SK, et al. Plant Dis. 2008 Jan;92(1):171. doi: 10.1094/PDIS-92-1-0171C. PMID: 30786384 |
|---|---|
| 2 |
Gao S, et al. Arch Virol. 2010 Apr;155(4):607-12. doi: 10.1007/s00705-010-0625-0. Epub 2010 Mar 12. PMID: 20224893 |
| 3 |
The complete genome sequence of New World jatropha mosaic virus. Polston JE, et al. Arch Virol. 2014 Nov;159(11):3131-6. doi: 10.1007/s00705-014-2132-1. Epub 2014 Aug 5. PMID: 25091738 |
| 4 |
Gireeshbai S, et al. Lett Appl Microbiol. 2022 Oct;75(4):1000-1009. doi: 10.1111/lam.13774. Epub 2022 Jul 2. PMID: 35723883 |
| 5 |
Snehi SK, et al. Virus Genes. 2011 Aug;43(1):93-101. doi: 10.1007/s11262-011-0605-9. Epub 2011 Apr 9. PMID: 21479677 |
| 6 |
Melgarejo TA, et al. Phytopathology. 2015 Jan;105(1):141-53. doi: 10.1094/PHYTO-05-14-0135-R. PMID: 25163012 |
| 7 |
Wang G, et al. Virus Genes. 2014 Apr;48(2):402-5. doi: 10.1007/s11262-014-1034-3. Epub 2014 Jan 21. PMID: 24445901 |
| 8 |
Charoenvilaisiri S, et al. Virol J. 2021 May 18;18(1):100. doi: 10.1186/s12985-021-01572-6. PMID: 34006310 |
| 9 |
Mgbechi-Ezeri JU, et al. Plant Dis. 2008 Dec;92(12):1709. doi: 10.1094/PDIS-92-12-1709B. PMID: 30764308 |
| 10 |
Srivastava A, et al. Arch Virol. 2015 May;160(5):1359-62. doi: 10.1007/s00705-015-2375-5. Epub 2015 Feb 27. PMID: 25716923 |