Jatropha mosaic Nigeria virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000900435.1 |
| Isolate | Nigeria |
| Release date | 2015/2/22 |
| Submitter | Kashina,B.D., Alegbejo,M.D., Banwo,O.O., Nielsen,S.L., Nicolaisen,M. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
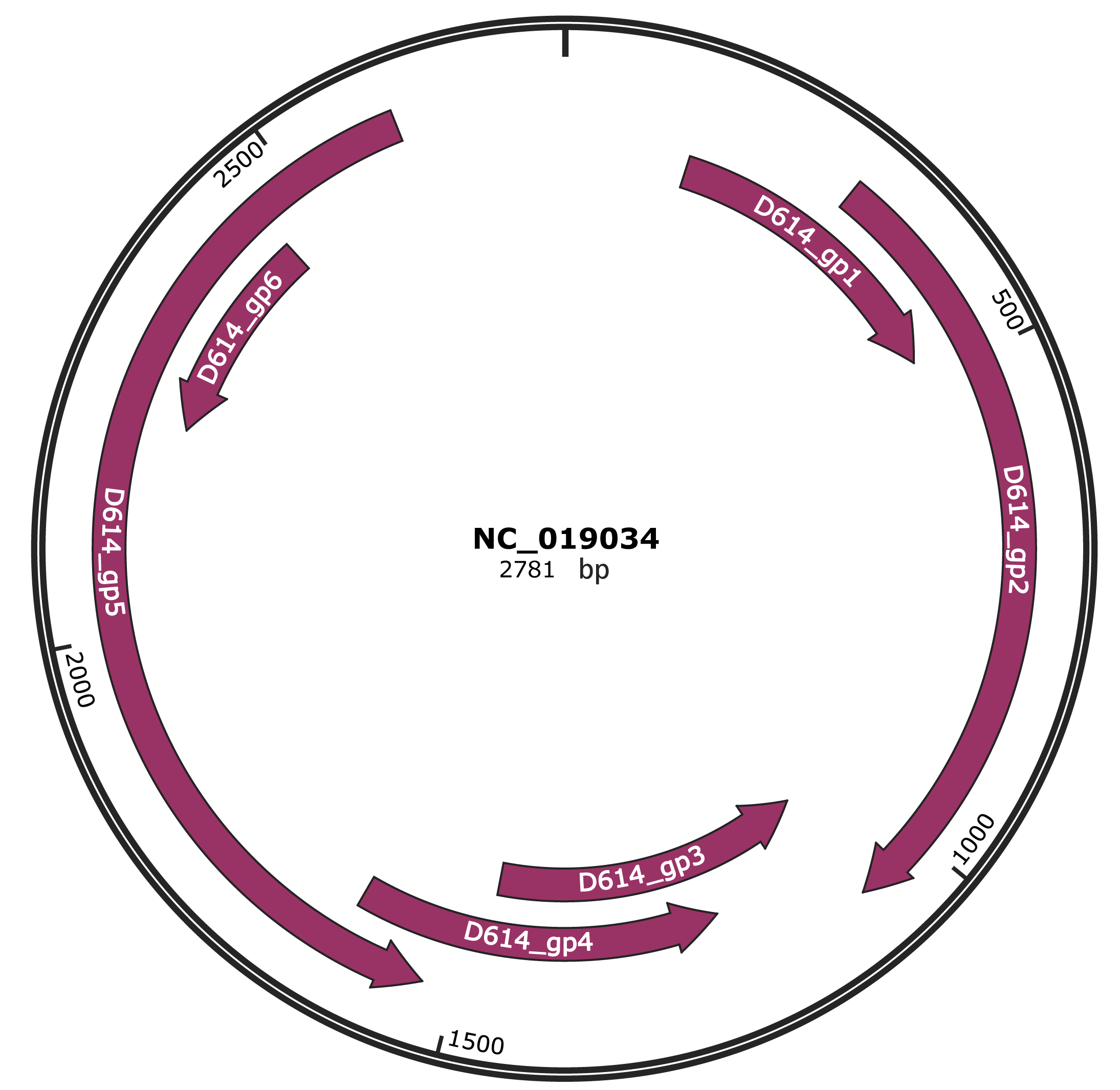
JBrowse
Genome
NC_019034
ACCGGATGGCCGCGCGATACCCGCTCAACGTGGTCCCCACGTGACAAGACATGTCGGCCACTCATGATGCGTCTGTTGAGGTTAGATATGTGTGGTCCCAGGATAAAAACTTCGTCACGAAGTTGGTGAGTCACACAATGTGGGACCCTTTAAGAAATGAATTTCCAGAAACCCTTCATGGGTTTCGTTGTATGTTGGCTGTGAAGTTTTTGCAGGCTCTTGTGGATAGTTACAGTCCGGATACGAAGGGATACGAATACATACGGGATCTTATATGTATTCTACGCTCGCGACATTATAATGAAGCGAACATACGATATGGCCTTCTCGTCTCCCGTATCCAATGTACGCCGGCGTCTCAACTTCGGGAGTCCTCTGGCGTTACCTGCTCCTGCGAGCACTGCCCCCGGCACTTCAAGAAGACGGGCCTGGAGAAACAGGCCCATGAACAGGAAGCCCAGGTTCTACCGGACGTTTAGGAGCCCAGACGTCCCTCGTGGATGTGAAGGCCCATGTAAGGTCCAGTCCTATGAGCAACGCGATGATGTGAAACACACCGGTGTTGTGCGGTGTGTTAGTGATGTTACCCGTGGTTCTGGTATTACCCATCGGGTAGGTAAGCGTTTTTGCATCAAGTCCATCTATATTCTCGGGAAGATTTGGATGGATGAGAATATCAAGAAGCAGAACCACACGAACCAGGTTATGTTTTATTTGGTGCGTGATCGTAGACCCTATGGGACGAGTCCAATGGACTTTGGACAAGTGTTTAACATGTTTGACAACGAGCCGTCAACGGCCACTGTGAAGAACGATCTGCGAGATCGCTTCCAGGTGCTACGGAAGTTCTATGCTACTGTCACTGGTGGTCCTTCGGGAATGAAGGAACAGGCTTTAGTTAAGAGGTTCTTTAGGATTAACAATCATGTTGTTTACAACCATCAGGAACAGGCGAAGTATGAGAATCATACTGAGAACGCGTTATTATTGTATTTGGCATGTACGCATGCTTCGAATCCTGTGTATGCAACGCTGAAGATACGCATCTATTTTTACGATGCCGTCACGAATTAATAAAATTTAAATTTTATTTCATGAAATTCCTGAACTTCGATACAAGTCCTAATTACATTATGTAATACATGATCGACAGATCTAATAACATTATTAATGGAAATTACACCTAACATGTCTAAGTACTTAAGGACTTGGTATTTAAATACTCTCAAGAAAGTCCCAGACCGAGTCTGTGAAGTCGTCCAGATTCGGAAGTTCAGATAACACTTGTGAAGACCCAGTTCCTTCCGGAGGTTGTGGTTGAACCGGATCTGGATGGTGATGATGTCGTGGTTGGTGTTGAATGGCCGCACGCTCTGCTCCGTGGTCGTGAAATATAGGGGATTGTTTATCTCCCAGATAAACACGCCATTCCCTGCTTGAGGAGCAGTGATGTACTCCCCGGTGCGTGAATCCATGGTTAGCACAGTTGAGATGTAGATAGTATGAGCAGCCGCACTCGAGATCGATGCGTCTACGACGTATTCTCTTGGTCTTCGCGATTCTGTGCTTGACTTTGATTGGTACCGGAGTAGAGTGGCTCACTGATGGTGATGAATGTTGCATTTTGAAGTGTCCACCGCTTCAAAGCTGAGTTCTTCTCTTCCTCCAAGAACTCTTTATAGGACGATGTCGGGCCAGGATTGCAGAGGAAGATTGTCGGGATTCCGCCTTTAATTTGAATTGGCTTGCCGTATTTCGTGTTGCTTTGCCAATCACGCTGGGCCCCCATGAACTCTTTGAAATGTTTTAGATAGTGCGGATCCACGTCGTCGATGATGTTGTACCAGGCGTCATTTGAATAGACCTTGGGACTAATGTCCAAATGACCACATAAGTAATTATGTGGACCCAGGCTTCGTGCCCACATTGTTTTGCCCGTACGACTATCGCCCTCGATAACAATACTTTTAGGTCTCCATGGCCGCGCAGCGGCTGCCTTCACATTGTCGGCTACCCACTGCTCAAGTTCGTCCGGAACTTGATCAAATGAAGAGGACATAAAAGGAGATCTATAAATCTCTACGGGAGGAGTGAATATCCTCTCTAAATTGGAATTAAGATTATGAAATTGTAATACATAATCCTTTGGGGCTAATTCTTTAATTAGTCGTAGGGCTTCAGACTTACTGCCTGCGTTCAGCGCCTGTGCGTAAGCATCGTTTATTGATTGTTTGCCTCCTCTCGCTGATCGTCTATCGATCTGGAATTGGCCCCAGTCGAGGACGTCTCCGTCCTTCTCAAGATATGCCTTGACATCGGAGCTAGACTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGGTTGGGGATACCAAGTCGAACAATCTGCAATTCGTGAGTCGGACTTTGCCCTCGAATTGGACGAGCACATGCAGATGAGGTTCCCCATTTTGATGCAGTTCTCTGCAGATTCTTATGAATTTGGGGTTTGAAGGGAGTGACAGATTGGTTAATTGCGAAAGAGTTTCTTCTTTCGATAACGAGCACTGCGGATATGTAAGAAATAAGTTCTTACAATTAATTTGGAATTTTTTTGGAGCGTTAGGCATGTTGACTTTGTATGGGTACCCTTGACCGCTCTCGTCTAATCCTCGGGTGCAATTATATTGGTACCCATATATAGGGGGGGTACCAAATGGCACGCTGGTAATTTTTACAACTTCATGTTTGAAATTCAAAGTTTGAAAGTTCCACTAGCGGCCATCCGTATAATATT
Gene Information
| NCBI Accession | YP_006905835.1 |
|---|---|
| Location | 138-479 |
| Protein Name | V2 |
| Coding Region | ATGTGGGACCCTTTAAGAAATGAATTTCCAGAAACCCTTCATGGGTTTCGTTGTATGTTGGCTGTGAAGTTTTTGCAGGCTCTTGTGGATAGTTACAGTCCGGATACGAAGGGATACGAATACATACGGGATCTTATATGTATTCTACGCTCGCGACATTATAATGAAGCGAACATACGATATGGCCTTCTCGTCTCCCGTATCCAATGTACGCCGGCGTCTCAACTTCGGGAGTCCTCTGGCGTTACCTGCTCCTGCGAGCACTGCCCCCGGCACTTCAAGAAGACGGGCCTGGAGAAACAGGCCCATGAACAGGAAGCCCAGGTTCTACCGGACGTTTAG |
| Protein Sequence | MWDPLRNEFPETLHGFRCMLAVKFLQALVDSYSPDTKGYEYIRDLICILRSRHYNEANIRYGLLVSRIQCTPASQLRESSGVTCSCEHCPRHFKKTGLEKQAHEQEAQVLPDV |
| NCBI Accession | YP_006905836.1 |
|---|---|
| Location | 301-1074 |
| Protein Name | V1 |
| Coding Region | ATGAAGCGAACATACGATATGGCCTTCTCGTCTCCCGTATCCAATGTACGCCGGCGTCTCAACTTCGGGAGTCCTCTGGCGTTACCTGCTCCTGCGAGCACTGCCCCCGGCACTTCAAGAAGACGGGCCTGGAGAAACAGGCCCATGAACAGGAAGCCCAGGTTCTACCGGACGTTTAGGAGCCCAGACGTCCCTCGTGGATGTGAAGGCCCATGTAAGGTCCAGTCCTATGAGCAACGCGATGATGTGAAACACACCGGTGTTGTGCGGTGTGTTAGTGATGTTACCCGTGGTTCTGGTATTACCCATCGGGTAGGTAAGCGTTTTTGCATCAAGTCCATCTATATTCTCGGGAAGATTTGGATGGATGAGAATATCAAGAAGCAGAACCACACGAACCAGGTTATGTTTTATTTGGTGCGTGATCGTAGACCCTATGGGACGAGTCCAATGGACTTTGGACAAGTGTTTAACATGTTTGACAACGAGCCGTCAACGGCCACTGTGAAGAACGATCTGCGAGATCGCTTCCAGGTGCTACGGAAGTTCTATGCTACTGTCACTGGTGGTCCTTCGGGAATGAAGGAACAGGCTTTAGTTAAGAGGTTCTTTAGGATTAACAATCATGTTGTTTACAACCATCAGGAACAGGCGAAGTATGAGAATCATACTGAGAACGCGTTATTATTGTATTTGGCATGTACGCATGCTTCGAATCCTGTGTATGCAACGCTGAAGATACGCATCTATTTTTACGATGCCGTCACGAATTAA |
| Protein Sequence | MKRTYDMAFSSPVSNVRRRLNFGSPLALPAPASTAPGTSRRRAWRNRPMNRKPRFYRTFRSPDVPRGCEGPCKVQSYEQRDDVKHTGVVRCVSDVTRGSGITHRVGKRFCIKSIYILGKIWMDENIKKQNHTNQVMFYLVRDRRPYGTSPMDFGQVFNMFDNEPSTATVKNDLRDRFQVLRKFYATVTGGPSGMKEQALVKRFFRINNHVVYNHQEQAKYENHTENALLLYLACTHASNPVYATLKIRIYFYDAVTN |
| NCBI Accession | YP_006905837.1 |
|---|---|
| Location | 1071-1475 |
| Protein Name | C3 |
| Coding Region | ATGGATTCACGCACCGGGGAGTACATCACTGCTCCTCAAGCAGGGAATGGCGTGTTTATCTGGGAGATAAACAATCCCCTATATTTCACGACCACGGAGCAGAGCGTGCGGCCATTCAACACCAACCACGACATCATCACCATCCAGATCCGGTTCAACCACAACCTCCGGAAGGAACTGGGTCTTCACAAGTGTTATCTGAACTTCCGAATCTGGACGACTTCACAGACTCGGTCTGGGACTTTCTTGAGAGTATTTAAATACCAAGTCCTTAAGTACTTAGACATGTTAGGTGTAATTTCCATTAATAATGTTATTAGATCTGTCGATCATGTATTACATAATGTAATTAGGACTTGTATCGAAGTTCAGGAATTTCATGAAATAAAATTTAAATTTTATTAA |
| Protein Sequence | MDSRTGEYITAPQAGNGVFIWEINNPLYFTTTEQSVRPFNTNHDIITIQIRFNHNLRKELGLHKCYLNFRIWTTSQTRSGTFLRVFKYQVLKYLDMLGVISINNVIRSVDHVLHNVIRTCIEVQEFHEIKFKFY |
| NCBI Accession | YP_006905838.1 |
|---|---|
| Location | 1216-1623 |
| Protein Name | C2 |
| Coding Region | ATGCAACATTCATCACCATCAGTGAGCCACTCTACTCCGGTACCAATCAAAGTCAAGCACAGAATCGCGAAGACCAAGAGAATACGTCGTAGACGCATCGATCTCGAGTGCGGCTGCTCATACTATCTACATCTCAACTGTGCTAACCATGGATTCACGCACCGGGGAGTACATCACTGCTCCTCAAGCAGGGAATGGCGTGTTTATCTGGGAGATAAACAATCCCCTATATTTCACGACCACGGAGCAGAGCGTGCGGCCATTCAACACCAACCACGACATCATCACCATCCAGATCCGGTTCAACCACAACCTCCGGAAGGAACTGGGTCTTCACAAGTGTTATCTGAACTTCCGAATCTGGACGACTTCACAGACTCGGTCTGGGACTTTCTTGAGAGTATTTAA |
| Protein Sequence | MQHSSPSVSHSTPVPIKVKHRIAKTKRIRRRRIDLECGCSYYLHLNCANHGFTHRGVHHCSSSREWRVYLGDKQSPIFHDHGAERAAIQHQPRHHHHPDPVQPQPPEGTGSSQVLSELPNLDDFTDSVWDFLESI |
| NCBI Accession | YP_006905839.1 |
|---|---|
| Location | 1532-2614 |
| Protein Name | C1 |
| Coding Region | ATGCCTAACGCTCCAAAAAAATTCCAAATTAATTGTAAGAACTTATTTCTTACATATCCGCAGTGCTCGTTATCGAAAGAAGAAACTCTTTCGCAATTAACCAATCTGTCACTCCCTTCAAACCCCAAATTCATAAGAATCTGCAGAGAACTGCATCAAAATGGGGAACCTCATCTGCATGTGCTCGTCCAATTCGAGGGCAAAGTCCGACTCACGAATTGCAGATTGTTCGACTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGTCTAGCTCCGATGTCAAGGCATATCTTGAGAAGGACGGAGACGTCCTCGACTGGGGCCAATTCCAGATCGATAGACGATCAGCGAGAGGAGGCAAACAATCAATAAACGATGCTTACGCACAGGCGCTGAACGCAGGCAGTAAGTCTGAAGCCCTACGACTAATTAAAGAATTAGCCCCAAAGGATTATGTATTACAATTTCATAATCTTAATTCCAATTTAGAGAGGATATTCACTCCTCCCGTAGAGATTTATAGATCTCCTTTTATGTCCTCTTCATTTGATCAAGTTCCGGACGAACTTGAGCAGTGGGTAGCCGACAATGTGAAGGCAGCCGCTGCGCGGCCATGGAGACCTAAAAGTATTGTTATCGAGGGCGATAGTCGTACGGGCAAAACAATGTGGGCACGAAGCCTGGGTCCACATAATTACTTATGTGGTCATTTGGACATTAGTCCCAAGGTCTATTCAAATGACGCCTGGTACAACATCATCGACGACGTGGATCCGCACTATCTAAAACATTTCAAAGAGTTCATGGGGGCCCAGCGTGATTGGCAAAGCAACACGAAATACGGCAAGCCAATTCAAATTAAAGGCGGAATCCCGACAATCTTCCTCTGCAATCCTGGCCCGACATCGTCCTATAAAGAGTTCTTGGAGGAAGAGAAGAACTCAGCTTTGAAGCGGTGGACACTTCAAAATGCAACATTCATCACCATCAGTGAGCCACTCTACTCCGGTACCAATCAAAGTCAAGCACAGAATCGCGAAGACCAAGAGAATACGTCGTAG |
| Protein Sequence | MPNAPKKFQINCKNLFLTYPQCSLSKEETLSQLTNLSLPSNPKFIRICRELHQNGEPHLHVLVQFEGKVRLTNCRLFDLVSPTRSAHFHPNIQGAKSSSDVKAYLEKDGDVLDWGQFQIDRRSARGGKQSINDAYAQALNAGSKSEALRLIKELAPKDYVLQFHNLNSNLERIFTPPVEIYRSPFMSSSFDQVPDELEQWVADNVKAAAARPWRPKSIVIEGDSRTGKTMWARSLGPHNYLCGHLDISPKVYSNDAWYNIIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLEEEKNSALKRWTLQNATFITISEPLYSGTNQSQAQNREDQENTS |
| NCBI Accession | YP_006905840.1 |
|---|---|
| Location | 2221-2454 |
| Protein Name | C4 |
| Coding Region | ATGGGGAACCTCATCTGCATGTGCTCGTCCAATTCGAGGGCAAAGTCCGACTCACGAATTGCAGATTGTTCGACTTGGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGTCTAGCTCCGATGTCAAGGCATATCTTGAGAAGGACGGAGACGTCCTCGACTGGGGCCAATTCCAGATCGATAGACGATCAGCGAGAGGAGGCAAACAATCAATAA |
| Protein Sequence | MGNLICMCSSNSRAKSDSRIADCSTWYPQPGQHISIRTFRELSLAPMSRHILRRTETSSTGANSRSIDDQREEANNQ |
References More References in PubMed
| 1 |
Mgbechi-Ezeri JU, et al. Plant Dis. 2008 Dec;92(12):1709. doi: 10.1094/PDIS-92-12-1709B. PMID: 30764308 |
|---|---|
| 2 |
Kumar S, et al. Virusdisease. 2025 Jun;36(2):343-352. doi: 10.1007/s13337-025-00919-9. Epub 2025 May 8. PMID: 41018216 |
| 3 |
Simmonds-Gordon RN, et al. Arch Virol. 2014 Oct;159(10):2815-8. doi: 10.1007/s00705-014-2112-5. Epub 2014 May 29. PMID: 24872185 |
| 4 |
Kashina BD, et al. Arch Virol. 2013 Feb;158(2):511-4. doi: 10.1007/s00705-012-1512-7. Epub 2012 Oct 17. PMID: 23074041 |