Ageratum yellow vein Hualian virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000880075.1 |
| Isolate |
Taiwan: Hsinchu |
| Release date |
2015/2/22 |
| Submitter |
Tsai,W.S., Green,S.K., Shih,S.L. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
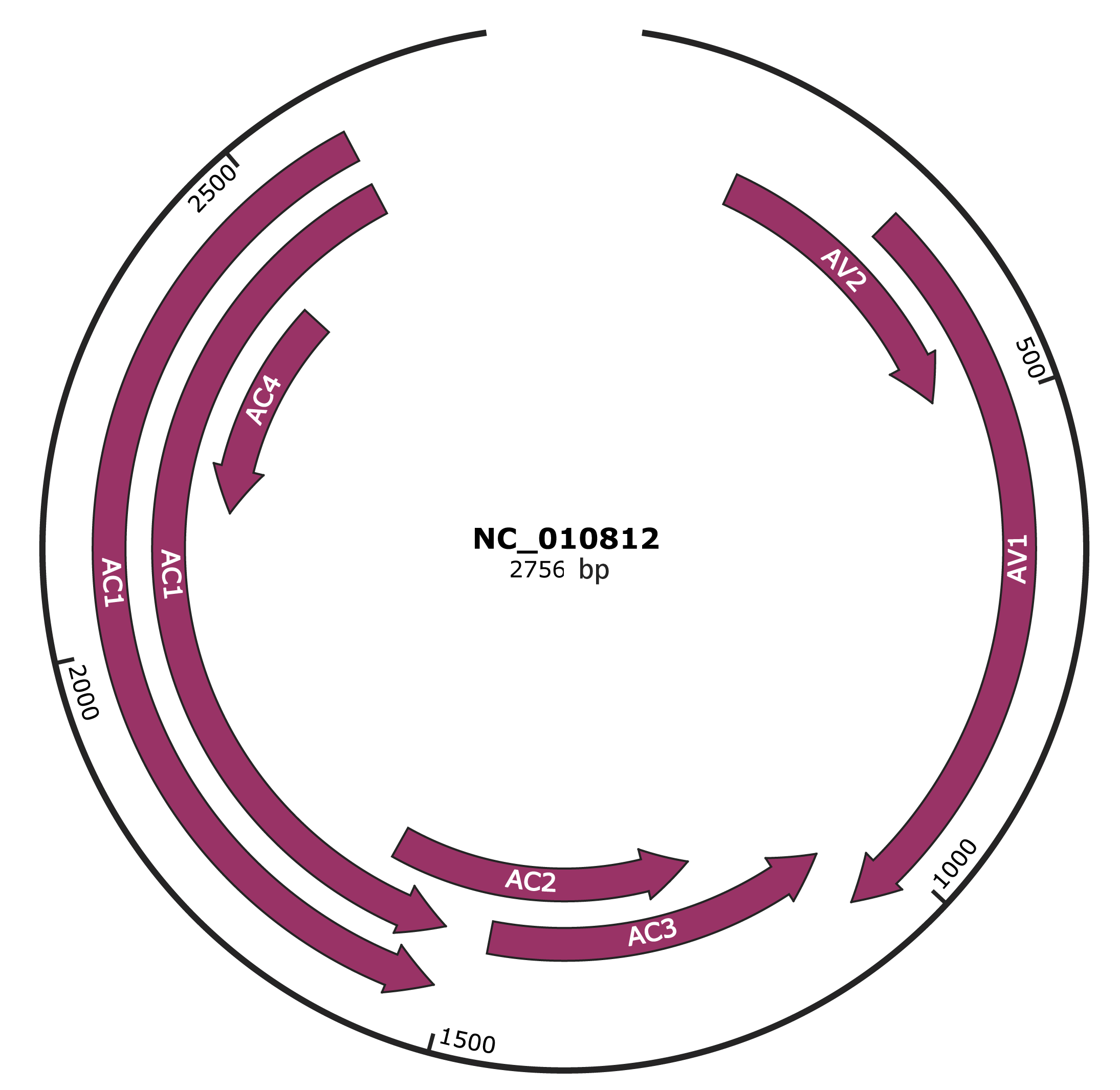
JBrowse
Genome
ACCGGATGGCCGCGATTTTTTTGGTGGTCCCTGTCCACTAACTTCTGTCTGCCAATAGAAACGCTCCCTCAAAGCTTATTTATTAAGTGGTCCACTATTTAACCCTTGGCCACCAAGTAAATCTTTAATAATGTGGGATCCACTTTTGAACGAATTCCCTGATAGTGTTCACGGTTTCAGGTGTATGCTCGCCATAAAATACTTGCAGCTCGTCGAATCTACGTATTCACCGGATACACTCGGGTACGATCTTGTAAGAGATTTGATTTCAGTTGTTCGTGCGAGGAATTATGTCGAAGCGACCAACAGATATTGTGATTTCCACGCCCGTTTCGAAGGTACGACGCCGTCTCAACTTCGACAGCCCTTACATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAGAGAAGGACATGGACCAACAGGCCCATGTATCGCAAGCCGAGACTATACAGAATGTACAGAACCCCTGATGTGCCCAAAGGTTGTGAAGGCCCATGTAAGGTACAATCGTATGAACAGAGGCACGACATATCCCATGTTGGTAAGGTATTATGTGTTAGTGATGTCACCCGTGGTAATGGGCTTACCCATCGTGTTGGTAAGAGATTCTGTGTGAAGTCTGTTTATGTATTAGGTAAAATATGGATGGATGAAAATATTAAAACTAAGAACCATACGAACACTGTGATGTTTTTTCTTGTTCGTGACAGAAGGCCCTATGGTACTGCTATGGATTTTGGTCAGGTGTTTAACATGTATGATAATGAGCCCAGTACTGCTACTATCAAGAATGATCTTCGAGATCGTTATCAAGTTTTAAGGAAATTCAGTTCAACAGTCACAGGGGGTCAATATGCTTCTAAGGAACAGGCGTTGGTGAAGAAATTTATGAAGATTAATAATTATGTAGTGTATAATCATCAAGAAGCTGCTAAGTATGACAATCATACTGAAAATGCCTTGTTATTGTATATGGCTTGTACTCATGCCAGTAATCCAGTGTATGCTACTTTGAAAATCAGAATCTATTTTTATGATTCTGTTCAGAATTAATAAAGATTGTATTTTATTATATTTGAATGTGTTACATATTCTGTTTTTTCCAATACATCCCATAAAACATGATTACACGCTCTAATTACATTGTTAATACTAATTACACCCAAATTATCCAAATATTTCATACATTGAATTTTAAATACTCTTAAGAAACGCCAAGTCTGAGGTTGTAAGCGAGTCCAGATCTGGAAGTCCAGATAACACTGGTGTATCCCCAATGCTTTCCTCAAATTGTGGTTGAATCGGATTTGTATGTGGATTATGTCCCATGGTCTGTTGAATGGTCTCTCGTGGTGCTTGGTTATTTTGAAATAGAGGGGATTTTTGATTGTCCAAGTATAAACGCCACTCTCGCATTGAATTGCAGTGAGTAATTCCCCTGTGCGTGAATCCATGATTTGCGCAGTCTATGCCGAAGTAGTATGAACACCCACATGTTAGATCAACTCTACGCCTGCGAACTGGCCTCCTCTTGGCTAATCTGTGTTGCACTTTGATTGGTACCTGAGTACAATGGGCTGTTGAGTGTGACGAATTCTGCATTCTTGAGAGCCCACTCTTTTAATGCTGAATTTTTATCCTCATTCAAGTACTCTTTATATGATGATGTTGGGCCTGGATTGCAAAGGAAGATAGTTGGGATTCCACCTTTAATTTGAATTGGTTTCCCGTACTTGGTGTTGCTTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGGTAGTGGGGGTCGACGTCATCAATGACGTTATACCAAGCATCATTGCTGTACACCTTTGGACTCAGATCTAGATGACCGCACAGATAATTATGTGGTCCCAGTGATCTGGCCCACATTGTTTTACCCGTACGACTATCACCTTCTATCACAATACTGATGGGTCTCCATGGCCGCGCAGCGGCATCCCTCACGTTCTCGGAGACCCATTCTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGAAGAAAGAAAAGGACAAACAAAAACCTCCAACGGAGTTGCAAAAATCCTATCTAAATTAGAATTTAAATTATGAAACTGTAATACAAAATCTTTGGGAGCTTTCTCCCTTAATATATTGATGGCCGCAGCTTTGGACCCTGAGTTGATTGCCTCGGCATATGCGTCGTTGGCAGATTGGCAACCTCCTCTAGCTGATCTTCCATCGACTTGGAAAACTCCATGATCAAGCACGTCTCCGTCTTTCTCCATGTAGGTTTTGACATCTGTCGAGCTCTTAGCTCCCTGAATGTTCGGATGGAAATGTGCTGACCTGCTTGGGGATGTGAGGTCGAAGAATCTGTTGTTTTGGCATTTGAATTTTCCTTCGAATTGGATGAGAATGTGCAGGTGAGGAGTCCCATCCTCGTGCAGTTCTCTGCAAACCCTAATGAATAATTTATTTGTTGGGGTTGCTAGGGCTTTTATTTGGGAAAGTGCTTCTTCTTTGTTTAGGGTGCAGTGTGGGTATGTGAGGAAGTAGTTCTTTGCATTTATTAAGAAACGCTTTGGGGGAGGCATGTTGACTTGCTCAATCGGGTCCTCTCAAACTTGGCTATGCAATCGGGGAATGGGTCTCAATATATAGGTGAGGACCTAAATGGCATTAATGTAATTATTGTAAGAAATTCAAAATTCGAATTTCGAATTGGTAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_001950233.1
|
|
Location
|
131-481 |
|
Gene Name
|
AV2 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGTGGGATCCACTTTTGAACGAATTCCCTGATAGTGTTCACGGTTTCAGGTGTATGCTCGCCATAAAATACTTGCAGCTCGTCGAATCTACGTATTCACCGGATACACTCGGGTACGATCTTGTAAGAGATTTGATTTCAGTTGTTCGTGCGAGGAATTATGTCGAAGCGACCAACAGATATTGTGATTTCCACGCCCGTTTCGAAGGTACGACGCCGTCTCAACTTCGACAGCCCTTACATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAGAGAAGGACATGGACCAACAGGCCCATGTATCGCAAGCCGAGACTATACAGAATGTACAGAACCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPDSVHGFRCMLAIKYLQLVESTYSPDTLGYDLVRDLISVVRARNYVEATNRYCDFHARFEGTTPSQLRQPLHEPCCCPHCPRHKQEKDMDQQAHVSQAETIQNVQNP |
|
NCBI Accession
|
YP_001950234.1
|
|
Location
|
291-1064 |
|
Gene Name
|
AV1 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGTCGAAGCGACCAACAGATATTGTGATTTCCACGCCCGTTTCGAAGGTACGACGCCGTCTCAACTTCGACAGCCCTTACATGAGCCGTGCTGCTGCCCCCACTGTCCTCGTCACAAACAAGAGAAGGACATGGACCAACAGGCCCATGTATCGCAAGCCGAGACTATACAGAATGTACAGAACCCCTGATGTGCCCAAAGGTTGTGAAGGCCCATGTAAGGTACAATCGTATGAACAGAGGCACGACATATCCCATGTTGGTAAGGTATTATGTGTTAGTGATGTCACCCGTGGTAATGGGCTTACCCATCGTGTTGGTAAGAGATTCTGTGTGAAGTCTGTTTATGTATTAGGTAAAATATGGATGGATGAAAATATTAAAACTAAGAACCATACGAACACTGTGATGTTTTTTCTTGTTCGTGACAGAAGGCCCTATGGTACTGCTATGGATTTTGGTCAGGTGTTTAACATGTATGATAATGAGCCCAGTACTGCTACTATCAAGAATGATCTTCGAGATCGTTATCAAGTTTTAAGGAAATTCAGTTCAACAGTCACAGGGGGTCAATATGCTTCTAAGGAACAGGCGTTGGTGAAGAAATTTATGAAGATTAATAATTATGTAGTGTATAATCATCAAGAAGCTGCTAAGTATGACAATCATACTGAAAATGCCTTGTTATTGTATATGGCTTGTACTCATGCCAGTAATCCAGTGTATGCTACTTTGAAAATCAGAATCTATTTTTATGATTCTGTTCAGAATTAA |
|
Protein Sequence
|
MSKRPTDIVISTPVSKVRRRLNFDSPYMSRAAAPTVLVTNKRRTWTNRPMYRKPRLYRMYRTPDVPKGCEGPCKVQSYEQRHDISHVGKVLCVSDVTRGNGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNTVMFFLVRDRRPYGTAMDFGQVFNMYDNEPSTATIKNDLRDRYQVLRKFSSTVTGGQYASKEQALVKKFMKINNYVVYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_001950235.1
|
|
Location
|
1061-1465 |
|
Gene Name
|
AC3 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTCACGCACAGGGGAATTACTCACTGCAATTCAATGCGAGAGTGGCGTTTATACTTGGACAATCAAAAATCCCCTCTATTTCAAAATAACCAAGCACCACGAGAGACCATTCAACAGACCATGGGACATAATCCACATACAAATCCGATTCAACCACAATTTGAGGAAAGCATTGGGGATACACCAGTGTTATCTGGACTTCCAGATCTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTATTTAAAATTCAATGTATGAAATATTTGGATAATTTGGGTGTAATTAGTATTAACAATGTAATTAGAGCGTGTAATCATGTTTTATGGGATGTATTGGAAAAAACAGAATATGTAACACATTCAAATATAATAAAATACAATCTTTATTAA |
|
Protein Sequence
|
MDSRTGELLTAIQCESGVYTWTIKNPLYFKITKHHERPFNRPWDIIHIQIRFNHNLRKALGIHQCYLDFQIWTRLQPQTWRFLRVFKIQCMKYLDNLGVISINNVIRACNHVLWDVLEKTEYVTHSNIIKYNLY |
|
NCBI Accession
|
YP_001950236.1
|
|
Location
|
1206-1613 |
|
Gene Name
|
AC2 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCAGAATTCGTCACACTCAACAGCCCATTGTACTCAGGTACCAATCAAAGTGCAACACAGATTAGCCAAGAGGAGGCCAGTTCGCAGGCGTAGAGTTGATCTAACATGTGGGTGTTCATACTACTTCGGCATAGACTGCGCAAATCATGGATTCACGCACAGGGGAATTACTCACTGCAATTCAATGCGAGAGTGGCGTTTATACTTGGACAATCAAAAATCCCCTCTATTTCAAAATAACCAAGCACCACGAGAGACCATTCAACAGACCATGGGACATAATCCACATACAAATCCGATTCAACCACAATTTGAGGAAAGCATTGGGGATACACCAGTGTTATCTGGACTTCCAGATCTGGACTCGCTTACAACCTCAGACTTGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQNSSHSTAHCTQVPIKVQHRLAKRRPVRRRRVDLTCGCSYYFGIDCANHGFTHRGITHCNSMREWRLYLDNQKSPLFQNNQAPRETIQQTMGHNPHTNPIQPQFEESIGDTPVLSGLPDLDSLTTSDLAFLKSI |
|
NCBI Accession
|
YP_001950237.1
|
|
Location
|
1519-2601 |
|
Gene Name
|
AC1 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGCCTCCCCCAAAGCGTTTCTTAATAAATGCAAAGAACTACTTCCTCACATACCCACACTGCACCCTAAACAAAGAAGAAGCACTTTCCCAAATAAAAGCCCTAGCAACCCCAACAAATAAATTATTCATTAGGGTTTGCAGAGAACTGCACGAGGATGGGACTCCTCACCTGCACATTCTCATCCAATTCGAAGGAAAATTCAAATGCCAAAACAACAGATTCTTCGACCTCACATCCCCAAGCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCGACAGATGTCAAAACCTACATGGAGAAAGACGGAGACGTGCTTGATCATGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAACTCAGGGTCCAAAGCTGCGGCCATCAATATATTAAGGGAGAAAGCTCCCAAAGATTTTGTATTACAGTTTCATAATTTAAATTCTAATTTAGATAGGATTTTTGCAACTCCGTTGGAGGTTTTTGTTTGTCCTTTTCTTTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAATGGGTCTCCGAGAACGTGAGGGATGCCGCTGCGCGGCCATGGAGACCCATCAGTATTGTGATAGAAGGTGATAGTCGTACGGGTAAAACAATGTGGGCCAGATCACTGGGACCACATAATTATCTGTGCGGTCATCTAGATCTGAGTCCAAAGGTGTACAGCAATGATGCTTGGTATAACGTCATTGATGACGTCGACCCCCACTACCTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAGTACGGGAAACCAATTCAAATTAAAGGTGGAATCCCAACTATCTTCCTTTGCAATCCAGGCCCAACATCATCATATAAAGAGTACTTGAATGAGGATAAAAATTCAGCATTAAAAGAGTGGGCTCTCAAGAATGCAGAATTCGTCACACTCAACAGCCCATTGTACTCAGGTACCAATCAAAGTGCAACACAGATTAGCCAAGAGGAGGCCAGTTCGCAGGCGTAG |
|
Protein Sequence
|
MPPPKRFLINAKNYFLTYPHCTLNKEEALSQIKALATPTNKLFIRVCRELHEDGTPHLHILIQFEGKFKCQNNRFFDLTSPSRSAHFHPNIQGAKSSTDVKTYMEKDGDVLDHGVFQVDGRSARGGCQSANDAYAEAINSGSKAAAINILREKAPKDFVLQFHNLNSNLDRIFATPLEVFVCPFLSSSFDQVPEELEEWVSENVRDAAARPWRPISIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEYLNEDKNSALKEWALKNAEFVTLNSPLYSGTNQSATQISQEEASSQA |
|
NCBI Accession
|
YP_001950238.1
|
|
Location
|
2151-2444 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGACTCCTCACCTGCACATTCTCATCCAATTCGAAGGAAAATTCAAATGCCAAAACAACAGATTCTTCGACCTCACATCCCCAAGCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAGAGCTCGACAGATGTCAAAACCTACATGGAGAAAGACGGAGACGTGCTTGATCATGGAGTTTTCCAAGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCAATCAACTCAGGGTCCAAAGCTGCGGCCATCAATATATTAA |
|
Protein Sequence
|
MGLLTCTFSSNSKENSNAKTTDSSTSHPQAGQHISIRTFRELRARQMSKPTWRKTETCLIMEFSKSMEDQLEEVANLPTTHMPRQSTQGPKLRPSIY |