Jacquemontia mosaic Yucatan virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_002867555.1 |
| Isolate |
Mexico: Yucatan, Merida |
| Release date |
2018/8/26 |
| Submitter |
Torres-Herrera,I., Cardenas-Conejo,Y., Ambriz-Granados,S., Moreno-Valenzuela,O., Arguello-Astorga,G.R. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
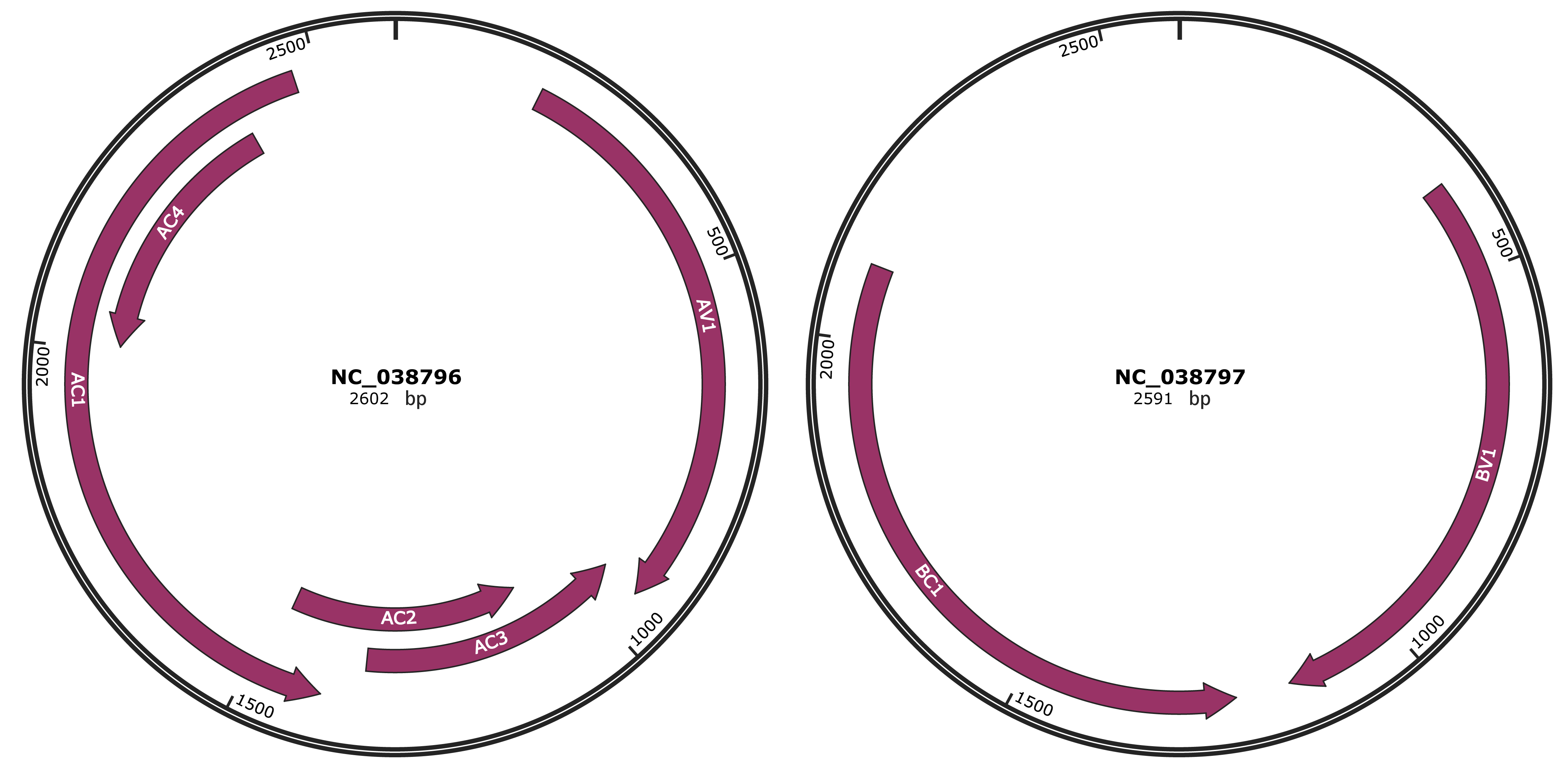
JBrowse
Genome
ACCGGATGGCCGCGCTGGCGTCCCCCGTCCGTACAGTGGTCCCCTGGAAAAAGCTAGGTCCTTAATGATGACAAACCGCGCCGTCCAATCAGAATGGGCGCTGGAAAGCTAATTAATTAAAACTTGGTGAGCAAGGACCACTTCCTTTAAATTTGGAGGGAACTCAGCAGTCCCGATGCACTTTATTTTGAAATGCCGAAGCGGGATGCCCCATGGCGCTCTCACCCGGGTACCGCCAAAGTCAGCCGCAATGCCAATTACTCGCCTCGTGGAGCTATGGGCCCAAAATATGATAAAACCTCGGCTTGGGTTTACCGGCCCATGTACAGGAAGCCCAGGGTATATCGTTTGTTGAGAGGCCCAGATGTCCCTAAGGGATGTGAAGGCCCATGTAAGGTCCAGTCTTATGAGCAGAAGCATGATATCTCCCATGTTGGTAAGGTCATCTGTATCTCCGATGTTACTCGTGGCAACGGTATCACCCACCGTGTTGGTAAGCGGTTCTGTGTTAAGTCCGTCTATATTCTGGGCAAGATATGGATGGATGAGAATATTAAGCTGAAGAACCACACGAATAGCGTTATGTTCTGGCTGGTGAGGGACAGGAGACCCTATGGCACCCCCATGGATTTTGGTCAGGTGTTCAACATGTACGACAACGAGCCCAGTACTGCCACTGTGAAGAACGATCTCCGGGATCGTTATCAGGTTATGCACCGGTTCTATGCTAAGGTCACCGGTGGTCAGTATGCCAGCAATGAGCAGGCTCTGGTGAGGAGGTTCTGGAAGGTGAATAACTACGTCGTCTACAACCACCAAGAGGCCGGGAAGTACGAGAATCATACGGAGAACGCCCTATTATTGTATATGGCCTGTACTCATGCCTCTAACCCTGTGTATGCGACGTTGAAAATTCGGATCTATTTTTATGATTCAATAATGAATTAATAAATATTGAATTTTATTGAATGACTTTCCAGTACATGATTTACATATGGTTTGTCAGTTGCAAATCTAACAGCTCTAATGACATTATTAATTGAAATAGCACCTAATCTGTCTAAGTACAACATCACTAAATGTCTAAACCACGCTAAATAAGTCGTCCCAGAAGCTGTCAGGGATGTCGTCCAGACCTGGAAGTTCACGTAAGCCCTGTGTAGATCCAGATGCCTCTTCAGGTTGTTGTTGAACCGGATCTGAACGTGGTAAATCCTCGTCGCTTTGTATGGTAGATCCTCCACGGGGTAGATCTTGAAATAGAGGGGAATTGGTACCTCCCAGATAAAAACGCCACTCTCTGCTTGAAGAGCAGTGATGGGTTCCCCTGTGCGTGAATCCATGATTGGCGCAATTGATGTGGACGTAAATGGAACAGCCGCAGTCCAGGTCTATTCGTTTACGACGTATTGCCCTGGATTTGGCAATCCTGTGTTTGGGTTTGATAGAGGGGGGAGTCGAGGAAGATGAAGGTTGCATTCTGAAGAGTCCAGCGTTTTAGAGGAGCGTTTTCCTCTTTGTCTAGGAAGTCTTTATAGCTGGTCCCCTCTCCTGGATTGCAAAGCACGATTGCTGGTAGTCCCCCTTTTATTTCACGTGGTTTACCGTACTTGCAATTGGATTGCCAGTCTGTTTGGGCCCCAATCAGCTCTTTCCAGTGCTTCATTTTCAAATAATTTGGAGCAACGTCATCAATTACGTTATACTCCACATCATCTGAATATGTCTTGGAATTGAAATCCAGATGTCCGCTGATGTAGTTATGGGACCCTAATGTTCTGGCCCACTGTGTTTTACCAGTTCTTGAATCACCTTCTATGATGATACTTCTGGGTCTCAATGGCCGCGCAGCGGAATCCCTTCCAAAATAATCGTCAGCCCACTCTTGCATTTCCTCTGGGACGTTATTAAATGATGACAATGGGAACTTTGGAGTCCATGGCTCTTTCTGTTTGGCAAAATCGAACTGTAAATTTGATCTAATATTGTGGCCTTGGGTTATCCATCTTACTGGATCCCCTGCCTTAATGATTGCAATAGCTGCCGCCATTGACTCTGCGTGAAGGGCGTTGTGGTATACGTCCTCCTTGTTTGTTCTTGTTGCCCCAGACACCTTGTATTGTCCGGATTCACAATAATCACCCTCTTTGGTGATGTAATTCTTGACGGCGTTGGTGTCTTTGGCTGCTTGGATATTAGGGTGGAAAGGGGTAGACCTTGATGGGTGAGATATGTCGAAAAATCGTTCATCCTTGATGTTTGATTTTCCAGAAAGTTGAATGAGGATGTGGAGATGGGGGTTTCCGTCAGAGTGTATCTCTCTGGCGACTCGGATGTATGTTGGACGGACGATTGTCCATGGCAGATTCTGAAGCAGTTCCAAGACATGGTTTTTGTCTAGACTGCACTGCGGATATGTTAGGAAGATATTTCTAGAGGCTAGGCGGAATTTATTAGGTTGTCGTGGCATTTTTGTAAATATGAGTGAGGACACCAGGCTCTCTCCGGATACTAGAACTCTATATGTTGGTGTCCTGGTGTCCCTTATATATGCAAGGAGTCCCAGGACACCAGGGGCAAAAGCGGCCATCCGTATAATATT
ACCGGATGGCCGCGCTGGGCGTCCCCTGTCCGTACAGTGGTCCCCTACAGCTGTTCCGCACTATTGGGTAGATTTTGTACTTGGAACACGTGGCGCTCTGTATGGCCTTGCTCAGAATTAGTGGCACGTCTTTCTATGTGTATGCTTTAATTTAAAATTCGAACAGTTTCCCGGGTTGTTTAACAGTGTCCCATTGAATAGGGAAAGACGTGGCATTTCTTTCCCCATCGCTCTGAGTCAAGTTAACATTTATGACTCCTCACTTTATGTATAAATTGCAGATGAAGTATTTGTGTTACGCAACTTGACTCATATAACCACCACGTTTATGTTATATACTTTAGAAATTGTGTAGTCATATATAGTTTTTTGTTTGACAATGTATGCTTATAGGTATAAACGTGGAGCTGCCACTACTCAACGTCCATATTATTCACGTAATAACGCGGTCAAGCGTTCATATCCCGCTAAACGTTTTAATGTGAAACGGTATCCTGTATCCTCTCGTAAGGCCCATGAAGAGCCCAAGATGGTGTCCCAACGTATCCAGGAGAATCAATATGGGCCTGAGTTCACAATGGCCCATAATTCCGCTATCTCTACGTATATTAGTTATCCAGGTATGGGCAAGACTCTTCCCAACCGAAGCCGGTCATATATTAAGCTGAGGCGTTTGCGTTTTAAGGGTACTGTTAAGATTGAGCGTGTAACTTCTGACATGAACATTGACGGCTCGGTTCCCAAAGTTGAAGGGGTGTTGTCCATTGTTATCGTTGTCGATCGTAAACCACACTTGAGTGCATCTGGTCGCCTGCATACATTTGATGAACTCTTCGGTGCTCTGATCCACAGCCATGGAACCCTGTCTATAACTCCGTCTTTGAAAGATAGGTTTTACATACGTCATGTGTGTAAACGTGTATTGTCCGTGGAGAAGGATTCAACCATTGTGGAGGTTGAAGGATCAACTAGTCTCTCTAATAGGCGTTATAACATGTGGTCTATGTTTAGGGATTTAGAACATGATACATGTAAGGGTGTTTACGACAATATTAGCAAAAACGCCCTATTAGTGTATTATTGTTGGATGTCAGATGTAATGTCTAAGGCATCGCCCTTTGTATCATTTGATCTCGATTATTTGGGATAGTTAATGAAAATAAATTGTGTTTAGCAATATTGAACAATCTCATTCTGATAAAACAAACATTTATAATTAATTTAATGTTTTGGTTGTGATGGAGTACAATTGGTGTTGATACATTCCTGGACTGTCTTCCTAACCAGCTCGTTTAATTGAGCTACGGACATAGTTATATTGGACTCTGCTCTTTGGGCTCCCACCATTGAAGCGGACTCTCCCGGGTCCAGTACGTTACCCTCTAGCCTGTTAAGATGCCTGTATGGATGTAATGCGCTCTCCACTTCTGATTGCGCATCTGAATTACTAACGCCCAGTGTGCTCCTTGAAGCCCATGTCTCACCGGGCCTTATCTGTATTGGGCCTCTAAGCCCAACTCCTGACATGGATGCGCATCTGATAAGCTTTCTCTCCCATCTCCCGTAATCAACATGGGAGAAGTCTACATCCTTGTCTGAGAATTGCTTGGATAGGATCTTAACAGTTGGTGGTTTGAACGGAATATCCACAGAGTGTTTCGCCGTGGAAAGTTTGAGCTTCCCTTTGAACTTGGCGAAATGCGTTCTCTGTTGCACATTAGTGTCGCAAACTCTGTAATAGAGCTTCCAAGGAATTTCATCTTTGAGGGAGAAGAATGACGCTGAGAAATAGTGGAGATCTATGTTGCATCTAATGGGAAAAGTCCATTTAGCCTGTAAGGATTCGTTTTGTGTCATCCTCATATCATGGATCTCCACAATCACGGTACCTGCTGCATTTATTGGTACCTGCTGCCTGTATTCTATGACACAGTGGTCTATCTTCATACAACTGCGACTCAGTCTAGCGCTAAATTGAGAAGCAGCAGAAGGAAATTGTAGTACAATCTCAGTTAGGTCATGCGAAAGCTGATATTCCTCACGATGAGATTCTATGTAGTTGAACGCGTTTGGTGGATTAGCTAACTGAGAATCCATATAGTGATACCTCGGCCGCGCTAGCGGCACCTCTTGAAGAAGATATGCGCTTGTGAAGAAGTGAAAGGGGTACTGATGAAGATGATAAGAACTTCAGCACTATGTTTTAATGATAGAAAAGTTACTCAACAACTAGTTTGTAGAATTCTTGCTGCTAATGAAGGGAATATCTGCGAAAGAATGAGATGATGTTGAAGGCTTAGTGTTTATATGGAAGATTATGACGATACTTCTGATAACGCTGGAAGACTCTTGAAGAACTAGGGTTTGTGAAAGAGTAAAGTGAGTGTTGAGAAGATGATAATGCTTCGGAGATAGATCTTGTGGTGTCTATTTATAATTGGAGTTGATTGTAGTGGCATTTTTGTAAATAAGAGTCAGGACACCAGGCTCTCTCCGCTCACTAGAACTCTATATGTTGGTGTCCTGGTGTCCCTTATATATGCAAGGAGTCCCAGGACACCAGGGGCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_009507992.1
|
|
Location
|
193-948 |
|
Gene Name
|
AV1 |
|
Protein Name
|
capsid protein |
|
Coding Region
|
ATGCCGAAGCGGGATGCCCCATGGCGCTCTCACCCGGGTACCGCCAAAGTCAGCCGCAATGCCAATTACTCGCCTCGTGGAGCTATGGGCCCAAAATATGATAAAACCTCGGCTTGGGTTTACCGGCCCATGTACAGGAAGCCCAGGGTATATCGTTTGTTGAGAGGCCCAGATGTCCCTAAGGGATGTGAAGGCCCATGTAAGGTCCAGTCTTATGAGCAGAAGCATGATATCTCCCATGTTGGTAAGGTCATCTGTATCTCCGATGTTACTCGTGGCAACGGTATCACCCACCGTGTTGGTAAGCGGTTCTGTGTTAAGTCCGTCTATATTCTGGGCAAGATATGGATGGATGAGAATATTAAGCTGAAGAACCACACGAATAGCGTTATGTTCTGGCTGGTGAGGGACAGGAGACCCTATGGCACCCCCATGGATTTTGGTCAGGTGTTCAACATGTACGACAACGAGCCCAGTACTGCCACTGTGAAGAACGATCTCCGGGATCGTTATCAGGTTATGCACCGGTTCTATGCTAAGGTCACCGGTGGTCAGTATGCCAGCAATGAGCAGGCTCTGGTGAGGAGGTTCTGGAAGGTGAATAACTACGTCGTCTACAACCACCAAGAGGCCGGGAAGTACGAGAATCATACGGAGAACGCCCTATTATTGTATATGGCCTGTACTCATGCCTCTAACCCTGTGTATGCGACGTTGAAAATTCGGATCTATTTTTATGATTCAATAATGAATTAA |
|
Protein Sequence
|
MPKRDAPWRSHPGTAKVSRNANYSPRGAMGPKYDKTSAWVYRPMYRKPRVYRLLRGPDVPKGCEGPCKVQSYEQKHDISHVGKVICISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMYDNEPSTATVKNDLRDRYQVMHRFYAKVTGGQYASNEQALVRRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSIMN |
|
NCBI Accession
|
YP_009507993.1
|
|
Location
|
945-1343 |
|
Gene Name
|
AC3 |
|
Protein Name
|
replication enhancer protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACCCATCACTGCTCTTCAAGCAGAGAGTGGCGTTTTTATCTGGGAGGTACCAATTCCCCTCTATTTCAAGATCTACCCCGTGGAGGATCTACCATACAAAGCGACGAGGATTTACCACGTTCAGATCCGGTTCAACAACAACCTGAAGAGGCATCTGGATCTACACAGGGCTTACGTGAACTTCCAGGTCTGGACGACATCCCTGACAGCTTCTGGGACGACTTATTTAGCGTGGTTTAGACATTTAGTGATGTTGTACTTAGACAGATTAGGTGCTATTTCAATTAATAATGTCATTAGAGCTGTTAGATTTGCAACTGACAAACCATATGTAAATCATGTACTGGAAAGTCATTCAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGEPITALQAESGVFIWEVPIPLYFKIYPVEDLPYKATRIYHVQIRFNNNLKRHLDLHRAYVNFQVWTTSLTASGTTYLAWFRHLVMLYLDRLGAISINNVIRAVRFATDKPYVNHVLESHSIKFNIY |
|
NCBI Accession
|
YP_009507994.1
|
|
Location
|
1084-1479 |
|
Gene Name
|
AC2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCAACCTTCATCTTCCTCGACTCCCCCCTCTATCAAACCCAAACACAGGATTGCCAAATCCAGGGCAATACGTCGTAAACGAATAGACCTGGACTGCGGCTGTTCCATTTACGTCCACATCAATTGCGCCAATCATGGATTCACGCACAGGGGAACCCATCACTGCTCTTCAAGCAGAGAGTGGCGTTTTTATCTGGGAGGTACCAATTCCCCTCTATTTCAAGATCTACCCCGTGGAGGATCTACCATACAAAGCGACGAGGATTTACCACGTTCAGATCCGGTTCAACAACAACCTGAAGAGGCATCTGGATCTACACAGGGCTTACGTGAACTTCCAGGTCTGGACGACATCCCTGACAGCTTCTGGGACGACTTATTTAGCGTGGTTTAG |
|
Protein Sequence
|
MQPSSSSTPPSIKPKHRIAKSRAIRRKRIDLDCGCSIYVHINCANHGFTHRGTHHCSSSREWRFYLGGTNSPLFQDLPRGGSTIQSDEDLPRSDPVQQQPEEASGSTQGLRELPGLDDIPDSFWDDLFSVV |
|
NCBI Accession
|
YP_009507995.1
|
|
Location
|
1400-2470 |
|
Gene Name
|
AC1 |
|
Protein Name
|
replication initiator protein |
|
Coding Region
|
ATGCCACGACAACCTAATAAATTCCGCCTAGCCTCTAGAAATATCTTCCTAACATATCCGCAGTGCAGTCTAGACAAAAACCATGTCTTGGAACTGCTTCAGAATCTGCCATGGACAATCGTCCGTCCAACATACATCCGAGTCGCCAGAGAGATACACTCTGACGGAAACCCCCATCTCCACATCCTCATTCAACTTTCTGGAAAATCAAACATCAAGGATGAACGATTTTTCGACATATCTCACCCATCAAGGTCTACCCCTTTCCACCCTAATATCCAAGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGACAATACAAGGTGTCTGGGGCAACAAGAACAAACAAGGAGGACGTATACCACAACGCCCTTCACGCAGAGTCAATGGCGGCAGCTATTGCAATCATTAAGGCAGGGGATCCAGTAAGATGGATAACCCAAGGCCACAATATTAGATCAAATTTACAGTTCGATTTTGCCAAACAGAAAGAGCCATGGACTCCAAAGTTCCCATTGTCATCATTTAATAACGTCCCAGAGGAAATGCAAGAGTGGGCTGACGATTATTTTGGAAGGGATTCCGCTGCGCGGCCATTGAGACCCAGAAGTATCATCATAGAAGGTGATTCAAGAACTGGTAAAACACAGTGGGCCAGAACATTAGGGTCCCATAACTACATCAGCGGACATCTGGATTTCAATTCCAAGACATATTCAGATGATGTGGAGTATAACGTAATTGATGACGTTGCTCCAAATTATTTGAAAATGAAGCACTGGAAAGAGCTGATTGGGGCCCAAACAGACTGGCAATCCAATTGCAAGTACGGTAAACCACGTGAAATAAAAGGGGGACTACCAGCAATCGTGCTTTGCAATCCAGGAGAGGGGACCAGCTATAAAGACTTCCTAGACAAAGAGGAAAACGCTCCTCTAAAACGCTGGACTCTTCAGAATGCAACCTTCATCTTCCTCGACTCCCCCCTCTATCAAACCCAAACACAGGATTGCCAAATCCAGGGCAATACGTCGTAA |
|
Protein Sequence
|
MPRQPNKFRLASRNIFLTYPQCSLDKNHVLELLQNLPWTIVRPTYIRVAREIHSDGNPHLHILIQLSGKSNIKDERFFDISHPSRSTPFHPNIQAAKDTNAVKNYITKEGDYCESGQYKVSGATRTNKEDVYHNALHAESMAAAIAIIKAGDPVRWITQGHNIRSNLQFDFAKQKEPWTPKFPLSSFNNVPEEMQEWADDYFGRDSAARPLRPRSIIIEGDSRTGKTQWARTLGSHNYISGHLDFNSKTYSDDVEYNVIDDVAPNYLKMKHWKELIGAQTDWQSNCKYGKPREIKGGLPAIVLCNPGEGTSYKDFLDKEENAPLKRWTLQNATFIFLDSPLYQTQTQDCQIQGNTS |
|
NCBI Accession
|
YP_009507996.1
|
|
Location
|
2008-2388 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGTCTTGGAACTGCTTCAGAATCTGCCATGGACAATCGTCCGTCCAACATACATCCGAGTCGCCAGAGAGATACACTCTGACGGAAACCCCCATCTCCACATCCTCATTCAACTTTCTGGAAAATCAAACATCAAGGATGAACGATTTTTCGACATATCTCACCCATCAAGGTCTACCCCTTTCCACCCTAATATCCAAGCAGCCAAAGACACCAACGCCGTCAAGAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGACAATACAAGGTGTCTGGGGCAACAAGAACAAACAAGGAGGACGTATACCACAACGCCCTTCACGCAGAGTCAATGGCGGCAGCTATTGCAATCATTAAGGCAGGGGATCCAGTAA |
|
Protein Sequence
|
MSWNCFRICHGQSSVQHTSESPERYTLTETPISTSSFNFLENQTSRMNDFSTYLTHQGLPLSTLISKQPKTPTPSRITSPKRVIIVNPDNTRCLGQQEQTRRTYTTTPFTQSQWRQLLQSLRQGIQ |
|
NCBI Accession
|
YP_009507997.1
|
|
Location
|
380-1150 |
|
Gene Name
|
BV1 |
|
Protein Name
|
nuclear shuttle protein |
|
Coding Region
|
ATGTATGCTTATAGGTATAAACGTGGAGCTGCCACTACTCAACGTCCATATTATTCACGTAATAACGCGGTCAAGCGTTCATATCCCGCTAAACGTTTTAATGTGAAACGGTATCCTGTATCCTCTCGTAAGGCCCATGAAGAGCCCAAGATGGTGTCCCAACGTATCCAGGAGAATCAATATGGGCCTGAGTTCACAATGGCCCATAATTCCGCTATCTCTACGTATATTAGTTATCCAGGTATGGGCAAGACTCTTCCCAACCGAAGCCGGTCATATATTAAGCTGAGGCGTTTGCGTTTTAAGGGTACTGTTAAGATTGAGCGTGTAACTTCTGACATGAACATTGACGGCTCGGTTCCCAAAGTTGAAGGGGTGTTGTCCATTGTTATCGTTGTCGATCGTAAACCACACTTGAGTGCATCTGGTCGCCTGCATACATTTGATGAACTCTTCGGTGCTCTGATCCACAGCCATGGAACCCTGTCTATAACTCCGTCTTTGAAAGATAGGTTTTACATACGTCATGTGTGTAAACGTGTATTGTCCGTGGAGAAGGATTCAACCATTGTGGAGGTTGAAGGATCAACTAGTCTCTCTAATAGGCGTTATAACATGTGGTCTATGTTTAGGGATTTAGAACATGATACATGTAAGGGTGTTTACGACAATATTAGCAAAAACGCCCTATTAGTGTATTATTGTTGGATGTCAGATGTAATGTCTAAGGCATCGCCCTTTGTATCATTTGATCTCGATTATTTGGGATAG |
|
Protein Sequence
|
MYAYRYKRGAATTQRPYYSRNNAVKRSYPAKRFNVKRYPVSSRKAHEEPKMVSQRIQENQYGPEFTMAHNSAISTYISYPGMGKTLPNRSRSYIKLRRLRFKGTVKIERVTSDMNIDGSVPKVEGVLSIVIVVDRKPHLSASGRLHTFDELFGALIHSHGTLSITPSLKDRFYIRHVCKRVLSVEKDSTIVEVEGSTSLSNRRYNMWSMFRDLEHDTCKGVYDNISKNALLVYYCWMSDVMSKASPFVSFDLDYLG |
|
NCBI Accession
|
YP_009507998.1
|
|
Location
|
1222-2097 |
|
Gene Name
|
BC1 |
|
Protein Name
|
movement protein |
|
Coding Region
|
ATGGATTCTCAGTTAGCTAATCCACCAAACGCGTTCAACTACATAGAATCTCATCGTGAGGAATATCAGCTTTCGCATGACCTAACTGAGATTGTACTACAATTTCCTTCTGCTGCTTCTCAATTTAGCGCTAGACTGAGTCGCAGTTGTATGAAGATAGACCACTGTGTCATAGAATACAGGCAGCAGGTACCAATAAATGCAGCAGGTACCGTGATTGTGGAGATCCATGATATGAGGATGACACAAAACGAATCCTTACAGGCTAAATGGACTTTTCCCATTAGATGCAACATAGATCTCCACTATTTCTCAGCGTCATTCTTCTCCCTCAAAGATGAAATTCCTTGGAAGCTCTATTACAGAGTTTGCGACACTAATGTGCAACAGAGAACGCATTTCGCCAAGTTCAAAGGGAAGCTCAAACTTTCCACGGCGAAACACTCTGTGGATATTCCGTTCAAACCACCAACTGTTAAGATCCTATCCAAGCAATTCTCAGACAAGGATGTAGACTTCTCCCATGTTGATTACGGGAGATGGGAGAGAAAGCTTATCAGATGCGCATCCATGTCAGGAGTTGGGCTTAGAGGCCCAATACAGATAAGGCCCGGTGAGACATGGGCTTCAAGGAGCACACTGGGCGTTAGTAATTCAGATGCGCAATCAGAAGTGGAGAGCGCATTACATCCATACAGGCATCTTAACAGGCTAGAGGGTAACGTACTGGACCCGGGAGAGTCCGCTTCAATGGTGGGAGCCCAAAGAGCAGAGTCCAATATAACTATGTCCGTAGCTCAATTAAACGAGCTGGTTAGGAAGACAGTCCAGGAATGTATCAACACCAATTGTACTCCATCACAACCAAAACATTAA |
|
Protein Sequence
|
MDSQLANPPNAFNYIESHREEYQLSHDLTEIVLQFPSAASQFSARLSRSCMKIDHCVIEYRQQVPINAAGTVIVEIHDMRMTQNESLQAKWTFPIRCNIDLHYFSASFFSLKDEIPWKLYYRVCDTNVQQRTHFAKFKGKLKLSTAKHSVDIPFKPPTVKILSKQFSDKDVDFSHVDYGRWERKLIRCASMSGVGLRGPIQIRPGETWASRSTLGVSNSDAQSEVESALHPYRHLNRLEGNVLDPGESASMVGAQRAESNITMSVAQLNELVRKTVQECINTNCTPSQPKH |