Indian cassava mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000846665.1 |
| Release date | 2015/2/12 |
| Submitter | Hong,Y.G., Robinson,D.J., Harrison,B.D., Hong,Y. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
JBrowse
Genome
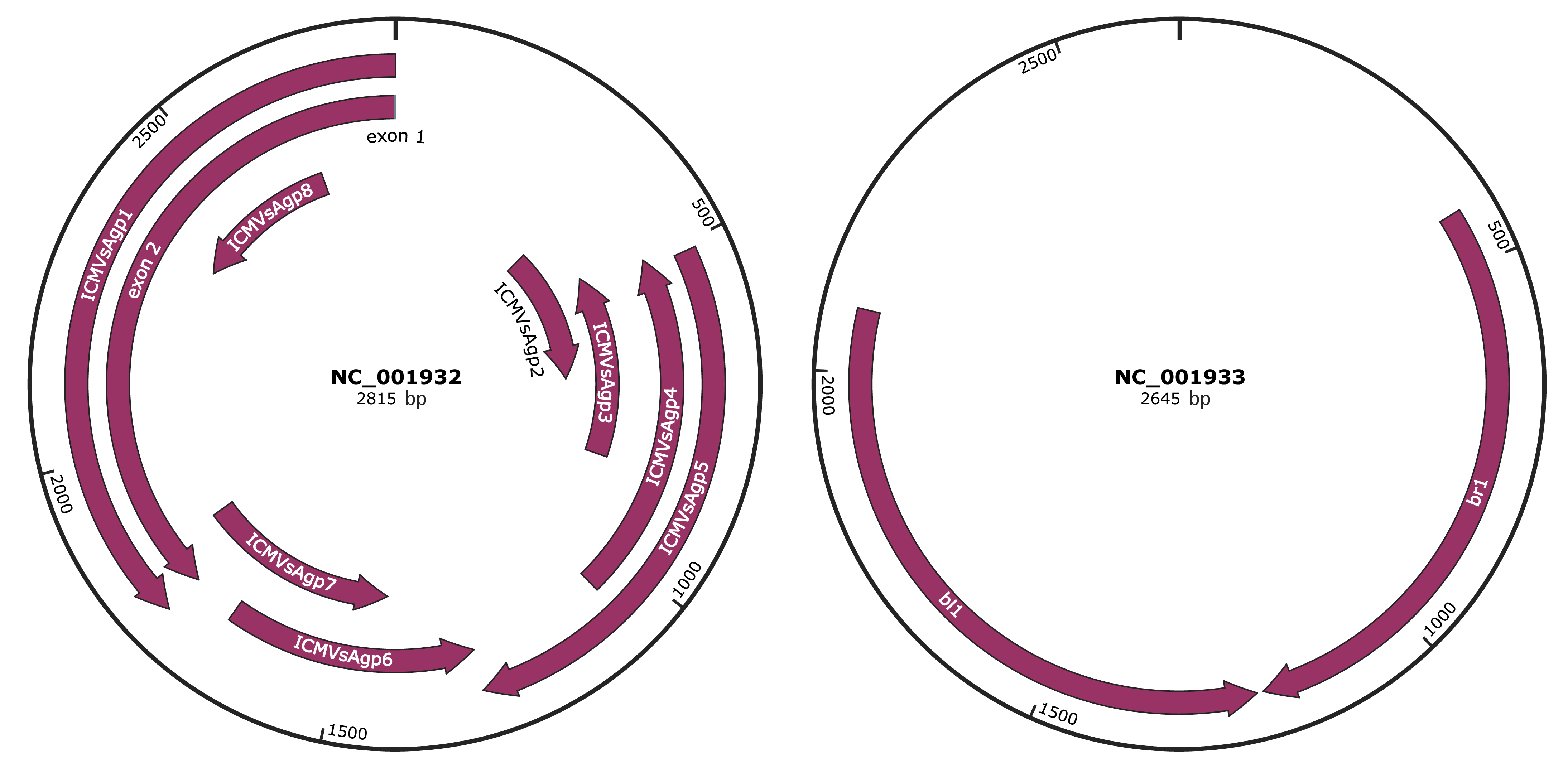
NC_001932
NC_001933
Gene Information
| NCBI Accession | NP_047233.1 |
|---|---|
| Location | 1761-2815,1 |
| Protein Name | AL1 |
| Coding Region | ATGTCACCACCTAAGCGCTTTCAAATAAACGCTAAAAACTATTTCCTCACTTACCCTCGATGCTCCTTAACTAAAGAAGAGGCTCTCTCTCAAATTAGGAACTTTCAAACACCTACAAACCCTAAATTCATCAAAATATGCAGGGAGCTACATGAGAATGGGGAGCCTCATCTGCACGTGCTCATCCAGTTCGAAGGCAAATACAAATGCCAGAATCAGCGATTCTTCGACCTGGTATCACCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGTGATACTTGGAGATGGGGAACATTTCAGATCGATGGACGATCAGCCAGAGGGGGTCAACAATCTGCAAACGACGCTTACGCCGCGGCACTTAACAGCGGCAGTAAATCAGAGGCTCTTAAGATCCTTAGAGAATTAGCACCTAGGGATTATCTTAGGGACTTCCATCACATCAGTTCAAACCTGGATCGGATTTTTACAAAACCACCACCTCCATATGAGAACCCTTTCCCTCTCTCTTCGTTTGACCGAGTTCCAGAAGAACTCGACGAGTGGTTCCACGAAAACGTGATGGGTCGTGCGCGGCCTTTGAGACCAAAATCAATCGTAATCGAAGGCGATAGTCGGACGGGCAAGACCATGTGGTCCCGTGCATTGGGTCCACATAATTACCTATGTGGACACCTGGATTTAAGTCCTAAGGTCTACAACAATGATGCATGGTACAACGTCATTGATGACGTCGATCCCCACTACCTAAAGCACTTCAAAAGAATTCATGGGGGCCCAGAGGACTGGCAATCAAACACCAAGTACGGTAAGCCAGTTCAAATTAAAGGAGGTATTCCCACTATCTTCCTCTGCAATCCAGGCCCCAATTCCAGCTATAAAGAATTCCTGGACGAGGAAAAGAATAGCGCATTAAAAGCCTGGGCTCTGAAAAATGCGACCTTCATCTCCCTCGAAGGACCACTATACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAA |
| Protein Sequence | MSPPKRFQINAKNYFLTYPRCSLTKEEALSQIRNFQTPTNPKFIKICRELHENGEPHLHVLIQFEGKYKCQNQRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIDKDGDTWRWGTFQIDGRSARGGQQSANDAYAAALNSGSKSEALKILRELAPRDYLRDFHHISSNLDRIFTKPPPPYENPFPLSSFDRVPEELDEWFHENVMGRARPLRPKSIVIEGDSRTGKTMWSRALGPHNYLCGHLDLSPKVYNNDAWYNVIDDVDPHYLKHFKRIHGGPEDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNSALKAWALKNATFISLEGPLYSGTNQGPTQSC |
| NCBI Accession | NP_047227.1 |
|---|---|
| Location | 352-690 |
| Protein Name | AR0 |
| Coding Region | ATGTGGGACCCTTTACTAAACGAGTTCCCTGAGTCTGTCCACGGTTTCCGGTGTATGCTCGCCGTGAAATACCTTCAGCTGGTTGAATGTACTTATTCTCCTGATACACTCGGTTACGATTTAATTAGAGATTTGTTCTCTGTTATTAGGGCGAAGAATTATGTCGAAGCGACCAGCAGATATCATAATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCGGCTGTCCCTACTGTCCGCGTCACAAAAAGACAATCCTGGACAAACAGACCCATCAATCGGAAGCCCAGGTGGTATCGGATGTATAG |
| Protein Sequence | MWDPLLNEFPESVHGFRCMLAVKYLQLVECTYSPDTLGYDLIRDLFSVIRAKNYVEATSRYHNFYSRLEGSSPSELRQPIQQPCGCPYCPRHKKTILDKQTHQSEAQVVSDV |
| NCBI Accession | NP_047228.1 |
|---|---|
| Location | 472-852 |
| Protein Name | AL5 |
| Coding Region | ATGGACTTAACGCAAAACCTCTTACCCACCCGATGTGTAAGCCCAATTCCACGAGTGACATCAGAGATGCACATGACCTTACCTATATGGACCACATCGTGTCTCGACTCGAACGACTGGACCTTACATGGGCCTTCACAGCCCTTAGGAACATCTGGGCTTCTATACATCCGATACCACCTGGGCTTCCGATTGATGGGTCTGTTTGTCCAGGATTGTCTTTTTGTGACGCGGACAGTAGGGACAGCCGCACGGCTGCTGTATGGGCTGTCGAAGTTCAGACGGCGACGAACCTTCGAGCCTGGAGTAGAAATTATGATATCTGCTGGTCGCTTCGACATAATTCTTCGCCCTAATAACAGAGAACAAATCTCTAATTAA |
| Protein Sequence | MDLTQNLLPTRCVSPIPRVTSEMHMTLPIWTTSCLDSNDWTLHGPSQPLGTSGLLYIRYHLGFRLMGLFVQDCLFVTRTVGTAARLLYGLSKFRRRRTFEPGVEIMISAGRFDIILRPNNREQISN |
| NCBI Accession | NP_047229.1 |
|---|---|
| Location | 497-1060 |
| Protein Name | AL4 |
| Coding Region | ATGCCACTTCCTGAGAACTTGATAGCGATCACGATGCATGTTCTTCACGGTAGCTGTACTGGGCTCATTATCAAACATATTAAATACTTCACCAAAATCCTGAGGCTTATCAACAGGCCTACGATCCCTTACAAGGAAGAACATTACGCTATTCGTGTGATTCTTGGTCTTAATGTTTTCATCCATCCATATCTTGCCCAGGATGTAAATGGACTTAACGCAAAACCTCTTACCCACCCGATGTGTAAGCCCAATTCCACGAGTGACATCAGAGATGCACATGACCTTACCTATATGGACCACATCGTGTCTCGACTCGAACGACTGGACCTTACATGGGCCTTCACAGCCCTTAGGAACATCTGGGCTTCTATACATCCGATACCACCTGGGCTTCCGATTGATGGGTCTGTTTGTCCAGGATTGTCTTTTTGTGACGCGGACAGTAGGGACAGCCGCACGGCTGCTGTATGGGCTGTCGAAGTTCAGACGGCGACGAACCTTCGAGCCTGGAGTAGAAATTATGATATCTGCTGGTCGCTTCGACATAATTCTTCGCCCTAA |
| Protein Sequence | MPLPENLIAITMHVLHGSCTGLIIKHIKYFTKILRLINRPTIPYKEEHYAIRVILGLNVFIHPYLAQDVNGLNAKPLTHPMCKPNSTSDIRDAHDLTYMDHIVSRLERLDLTWAFTALRNIWASIHPIPPGLPIDGSVCPGLSFCDADSRDSRTAAVWAVEVQTATNLRAWSRNYDICWSLRHNSSP |
| NCBI Accession | NP_047230.1 |
|---|---|
| Location | 512-1282 |
| Protein Name | AR1 |
| Coding Region | ATGTCGAAGCGACCAGCAGATATCATAATTTCTACTCCAGGCTCGAAGGTTCGTCGCCGTCTGAACTTCGACAGCCCATACAGCAGCCGTGCGGCTGTCCCTACTGTCCGCGTCACAAAAAGACAATCCTGGACAAACAGACCCATCAATCGGAAGCCCAGGTGGTATCGGATGTATAGAAGCCCAGATGTTCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCGTTCGAGTCGAGACACGATGTGGTCCATATAGGTAAGGTCATGTGCATCTCTGATGTCACTCGTGGAATTGGGCTTACACATCGGGTGGGTAAGAGGTTTTGCGTTAAGTCCATTTACATCCTGGGCAAGATATGGATGGATGAAAACATTAAGACCAAGAATCACACGAATAGCGTAATGTTCTTCCTTGTAAGGGATCGTAGGCCTGTTGATAAGCCTCAGGATTTTGGTGAAGTATTTAATATGTTTGATAATGAGCCCAGTACAGCTACCGTGAAGAACATGCATCGTGATCGCTATCAAGTTCTCAGGAAGTGGCATGCCACGGTCACTGGTGGTCAGTATGCGAGCAAGGAGCAGGCTTTAGTTAGGCGTTTTTTTAGGGTTAATAATTATGTTGTGTATAACCAGCAAGAGGCTGGGAAATATGAGAACCATACTGAGAATGCATTAATGTTGTACATGGCGTGTACTCATGCCTCTAATCCTGTATACGCTACGTTGAAGATTAGAATTTATTTCTATGATTCAGTGAGCAATTAA |
| Protein Sequence | MSKRPADIIISTPGSKVRRRLNFDSPYSSRAAVPTVRVTKRQSWTNRPINRKPRWYRMYRSPDVPKGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGIGLTHRVGKRFCVKSIYILGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNMHRDRYQVLRKWHATVTGGQYASKEQALVRRFFRVNNYVVYNQQEAGKYENHTENALMLYMACTHASNPVYATLKIRIYFYDSVSN |
| NCBI Accession | NP_047231.1 |
|---|---|
| Location | 1279-1683 |
| Protein Name | AL3 |
| Coding Region | ATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTTTATCTGGGAGGTACCAAATCCCCTCTATTTCAAGATCATTCAACACGACAACAGACCGTTCGTAATGAACCAGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGGGACTACATCAATGCTGGATGGATTTCAAGGTCTGGACGACCTTACAGCCTCAGACCTGGCGTTTCTTGAGGGTATTTAAGACCCAAGTATTGAAATACTTAGATAGCTTAGGAGTTATAAGTATTAATACTATTGTAAAAGCCGTAGAGCATGTATTGTACAATGTAATCCATGGGACTGACCGTGTTGAGCAGTCTAATTTAATAAAATTAAATATTTATTAA |
| Protein Sequence | MDSRTGELITAAQAMNGVFIWEVPNPLYFKIIQHDNRPFVMNQDIITVQIRFNHNLRKALGLHQCWMDFKVWTTLQPQTWRFLRVFKTQVLKYLDSLGVISINTIVKAVEHVLYNVIHGTDRVEQSNLIKLNIY |
| NCBI Accession | NP_047232.1 |
|---|---|
| Location | 1424-1831 |
| Protein Name | AL2 |
| Coding Region | ATGCGACCTTCATCTCCCTCGAAGGACCACTATACTCAGGTACCAATCAAGGTCCAACACAGAGCTGCTAAGCGTAAACGCATCCGGCGTAAAAGGGTAGATCTCAACTGCGGGTGCTCGTACTACGTCCACATTAACTGCCACAACCATGGATTCACGCACAGGGGAACTCATCACTGCAGCTCAGGCGATGAATGGCGTCTTTATCTGGGAGGTACCAAATCCCCTCTATTTCAAGATCATTCAACACGACAACAGACCGTTCGTAATGAACCAGGACATAATAACCGTCCAGATACGGTTCAACCACAACCTGAGGAAAGCGTTGGGACTACATCAATGCTGGATGGATTTCAAGGTCTGGACGACCTTACAGCCTCAGACCTGGCGTTTCTTGAGGGTATTTAA |
| Protein Sequence | MRPSSPSKDHYTQVPIKVQHRAAKRKRIRRKRVDLNCGCSYYVHINCHNHGFTHRGTHHCSSGDEWRLYLGGTKSPLFQDHSTRQQTVRNEPGHNNRPDTVQPQPEESVGTTSMLDGFQGLDDLTASDLAFLEGI |
| NCBI Accession | NP_047234.1 |
|---|---|
| Location | 2357-2665 |
| Protein Name | AL0 |
| Coding Region | ATGAGAATGGGGAGCCTCATCTGCACGTGCTCATCCAGTTCGAAGGCAAATACAAATGCCAGAATCAGCGATTCTTCGACCTGGTATCACCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGACAAGGACGGTGATACTTGGAGATGGGGAACATTTCAGATCGATGGACGATCAGCCAGAGGGGGTCAACAATCTGCAAACGACGCTTACGCCGCGGCACTTAACAGCGGCAGTAAATCAGAGGCTCTTAAGATCCTTAGAGAATTAG |
| Protein Sequence | MRMGSLICTCSSSSKANTNARISDSSTWYHQPGQHISIQTFRELNPAPTSSPTSTRTVILGDGEHFRSMDDQPEGVNNLQTTLTPRHLTAAVNQRLLRSLEN |
| NCBI Accession | NP_047235.1 |
|---|---|
| Location | 428-1210 |
| Gene Name | br1 |
| Protein Name | BR1 protein |
| Coding Region | ATGAGAAGAGGTGCCTATACCCCCCGTTCTACTCCATTCCCTCGTGACCGGAGATCGTATAATGCCGGTAAGGGTAGATCATTTCGTTCGTACCGTCGTCGTGGACCTGTTCGTCCATTAGCTCGTCGGAATCTGTTTGGTGATGACCATGCACGTGCATTCACGTATAAGACCTTATCGGAGGATCAATTTGGACCGGACTTTACCATACATAATAATAATTATAAGTCATCGTATATATCTATGCCTGTTAAAACACGTGCCCTTAGCGATAACAGGGTAGGTGATTATATCAAACTTGTAAATATATCATTTACAGGTACAGTGTGTATAAAAAACAGCCAGATGGAGTCTGACGGAAGCCCAATGTTGGGCCTGCATGGGCTGTTTACTTGTGTATTGGTCCGGGATAAGACCCCCCGTATATATTCTGCCACTGAGCCTTTGATACCTTTCCCACAGTTGTTTGGGTCCATAAACGCGAGCTATGCGGATTTGTCTATACAAGACCCATATAAGGATCGGTTCACAGTTATCCGTCAGGTGTCATACCCAGTTAATACGGAGAAGGGTGATCATATGTGTCGTTTCAAAGGCACTCGTCGTTTTGGTGGTAGATACCCTATCTGGACTAGTTTTAAAGATGATGGTGGCAGTGGAGATTCATCGGGATTATATAGTAATACGTATAAAAATGCCATACTTGTATATTATGTATGGCTCAGCGACGTATCGTCACAATTGGAAATGTATTGTAAATATGTAACTCGATATATTGGTTAA |
| Protein Sequence | MRRGAYTPRSTPFPRDRRSYNAGKGRSFRSYRRRGPVRPLARRNLFGDDHARAFTYKTLSEDQFGPDFTIHNNNYKSSYISMPVKTRALSDNRVGDYIKLVNISFTGTVCIKNSQMESDGSPMLGLHGLFTCVLVRDKTPRIYSATEPLIPFPQLFGSINASYADLSIQDPYKDRFTVIRQVSYPVNTEKGDHMCRFKGTRRFGGRYPIWTSFKDDGGSGDSSGLYSNTYKNAILVYYVWLSDVSSQLEMYCKYVTRYIG |
| NCBI Accession | NP_047236.1 |
|---|---|
| Location | 1219-2082 |
| Gene Name | bl1 |
| Protein Name | BL1 protein |
| Coding Region | ATGGAGAATAATAGTAGCAATGCAGCGTATCTTCGTTCCGAAAGAGTTGAATATGAGTTAACCAATGACTCAACAGACGTCAAGTTGAGCTTTCCATCTCTTCTGGATAACAAAATATCGCTCCTCAAGGGTCACTGCTGCAAAATAGACCACATCGTCCTAGAATATAGAAACCAGGTACCCATTAACGCCACTGGACATGTCATCATTGAAATTCACGACCAAAGACTGCATGACGGAGACTCAAAACAGGCTGAATTTACTATTCCCGTCCAATGCAACTGCAACCTTCACTACTATTCTTCATCGTTCTCTACCATGAAGGACATAAACCCATGGAGGGTTATGTACAGGGTCGTAGACACAAACGTCATCAACGGGGTCCACTTCTGCCGTATACAAGGAAAACTCAAGCTGGTCAACTGCAAACGCAGTCCTAATGACATACAGTTCCGATCTCCCAAAATCGAGATACTGAGCAAGGCCTTCACTGAGAGGGACATTGATTTCTGGTCAGTGGGTCGGAAAGCCCAGCAGAGGAAACTGGTCCAAGGCCCAAGTCTAATAGGATCCAGATCCATGAGATATGCTCCATGTTCAATAGGCCCAAATGAATCCTGGGCCGTTAGAAGCGAGCTTGGGCTTCACGAGCCATGGGCCGTTAAAGAGCGAGGCTGGGCATCCATTGAAAGGCCTTACAACCAACTAAACCGGCTCAACCCAGACGCATTGGACCCAGGAAAGTCAGTATCACAAGTAGGATCGGACCAATTCACACGAGAGGACTTAAACGACATCATCAGCAAGACAGTAAATATATGTTTAAATACGAGTATGCAGAGCCATGTATCAAAAAATGTATAA |
| Protein Sequence | MENNSSNAAYLRSERVEYELTNDSTDVKLSFPSLLDNKISLLKGHCCKIDHIVLEYRNQVPINATGHVIIEIHDQRLHDGDSKQAEFTIPVQCNCNLHYYSSSFSTMKDINPWRVMYRVVDTNVINGVHFCRIQGKLKLVNCKRSPNDIQFRSPKIEILSKAFTERDIDFWSVGRKAQQRKLVQGPSLIGSRSMRYAPCSIGPNESWAVRSELGLHEPWAVKERGWASIERPYNQLNRLNPDALDPGKSVSQVGSDQFTREDLNDIISKTVNICLNTSMQSHVSKNV |
References More References in PubMed
| 1 |
Patil BL, et al. Virus Genes. 2022 Aug;58(4):308-318. doi: 10.1007/s11262-022-01909-5. Epub 2022 May 14. PMID: 35567667 |
|---|---|
| 2 |
Biolistic infection of cassava using cloned components of Indian cassava mosaic virus. Rothenstein D, et al. Arch Virol. 2005 Aug;150(8):1669-75. doi: 10.1007/s00705-005-0520-2. Epub 2005 Apr 14. PMID: 15824887 |
| 3 |
Gao S, et al. Arch Virol. 2010 Apr;155(4):607-12. doi: 10.1007/s00705-010-0625-0. Epub 2010 Mar 12. PMID: 20224893 |
| 4 |
Karthikeyan C, et al. Viruses. 2016 Sep 28;8(10):264. doi: 10.3390/v8100264. PMID: 27690084 |
| 5 |
Saunders K, et al. Virology. 2002 Feb 1;293(1):63-74. doi: 10.1006/viro.2001.1251. PMID: 11853400 |
| 6 |
Tissue and cell tropism of Indian cassava mosaic virus (ICMV) and its AV2 (precoat) gene product. Rothenstein D, et al. Virology. 2007 Mar 1;359(1):137-45. doi: 10.1016/j.virol.2006.09.014. Epub 2006 Oct 16. PMID: 17049959 |
| 7 |
Indian cassava mosaic virus: ultrastructure of infected cells. Roberts IM. J Gen Virol. 1989 Oct;70 ( Pt 10):2729-39. doi: 10.1099/0022-1317-70-10-2729. PMID: 2794977 |
| 8 |
Patil BL, et al. Arch Virol. 2005 Feb;150(2):389-97. doi: 10.1007/s00705-004-0399-3. Epub 2004 Oct 20. PMID: 15503225 |
| 9 |
Duraisamy R, et al. Mol Biotechnol. 2012 Feb 3. doi: 10.1007/s12033-012-9503-1. Online ahead of print. PMID: 22302313 |
| 10 |
First Report of the Presence of East African Cassava Mosaic Virus in Cameroon. Fondong VN, et al. Plant Dis. 1998 Oct;82(10):1172. doi: 10.1094/PDIS.1998.82.10.1172B. PMID: 30856787 |