Hybanthus yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_018580615.1 |
| Isolate |
Colombia |
| Release date |
2021/6/1 |
| Submitter |
Lopez-Lopez,K., Jara-Tejada,F., Vaca-Vaca,J.C. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
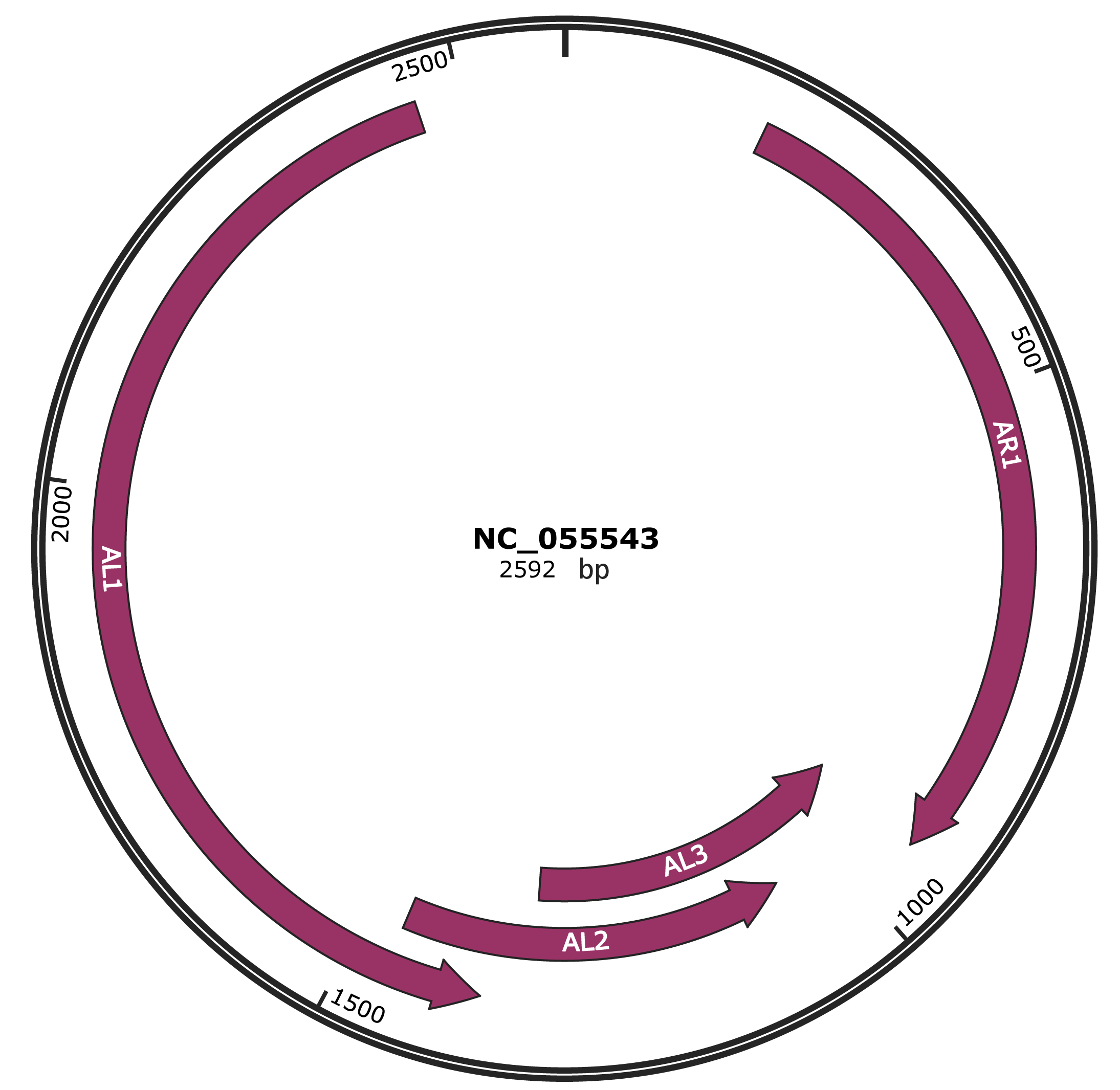
JBrowse
Genome
ACCGGATGGCCGCGCATCGGTGTACGCTCTCTCTCTCCCTTTAATTTAAATTAAAGCGTACCGCTTTCGTCCGAACCAATCATGTAGCGCCTGACGAGCTTAGATATTTTAAACAACTTGGGCGCTAAGTTGTTGTGTGTGTTTTATAAATTAAAGAGCCTCGGCCCACTGCCTTTAACTCAAAATGCCTAAGCGCGATGCCCCGTGGCGCTCGATGGCGGGAACATCAAAGGTTAGTCGCAATGTGAATTATTCTCCTCGTGGAGGCAGTGGCCCAAAATTAAACAGGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGAACACTGAGGACTCCTGATGTTCCAAGGGGATGTGAAGGCCCGTGTAAGGTACAGTCTTACGAACAGCGTCATGACATATCCCATGTCGGTAAGGTAATGTGTATATCTGACGTCACACGTGGAAATGGTATCACCCACCGTGTTGGCAAGCGTTTCTGTGTTAAGTCTGTGTATATTCTAGGCAAGATATGGATGGATGAGAATATCAAGCTGAAGAACCACACGAACAGCGTCATGTTCTGGCTGGTCAGGGACCGTAGACCGTATGGAACTCCCATGGACTTTGGCCAGGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCCACAGTGAAGAACGATCTCCGTGATCGTTTCCAGGTCATGCATAAGTTTTATGGCAAGGTGACAGGTGGACAATATGCCAGCAATGAACAGGCAATCGTCAAGCGTTTCTGGAGGGTCAACAATCATGTGGTCTACAACCACCAGGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTTTGTTATTGTACATGGCATGTACACATGCCTCTAATCCCGTGTATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATTTTAAATTAATAAAGCTTGAATTTTATTACATGTGGAAGCTCATTACATTCGATGTCCATCGTATCGACGGAGTATGTCACAGCCCTAATTACATTATTAATACAAATGACACCTAATCTATCTAAGTAACGATTAATCCTCGAACAGAATATCTTGTAGAAACTGGTACTGTTCCAGTGAGATGGTGTCCAGATCATCAGGTTCAGCCAACACTTGAGAAGACCCAGCTTCTTCCTGAGGTTGTGGTTGAATCGTATTTGGAACCGGTACCTCTTCGCTCTGTTGAGCTCCACAACCGACGTGATCTCGAAATATAGGGGATTTTCTATCTCCCAGATATACACGCCACTCTCTGCCTGACGTGCAGTGATGAGTTCCCCTGTGCGTGAATCCATGTCCCGTACAGCCTATGTGGAAATATATGGAGCAACCGCACTCCAGATCAATGCGGCGTCGTCTGACCGCCCTTTTCTTGGCCTCCCTGTGTTTCTTCTTGATAGAGGGGGGAGTGCAAGGTGATGAAGACCGCATTCTTTAAAGTCCAGTTCCTGAGAGCTGTGTTTTCCTCTTTGTTCAGGTAATCTTTATAGCTGGCACCCTCGCCAGGATTGCACAGCACGATTGATGGGATCCCTCCTTTAATCAGGACTGGCTTTCCGTACTTGCAATTTGACTGCCAATCTTTTTGGGCGCCTATCAAATCCTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCAATGACGTTATATTCCACTTCGTCTGAGAAAACTCTGGAATTGAAGTCTAGGTGTCCACTTAAATAATTATGTGGGCCTAATGCCCGAGCCCACATCGTCTTCCCTGTCCTTGAATCACCTTCTACTATGAGACTCACTGGTCTTTCTGGCCGCGCAGCGGCATCTCTTCCAAAATAATCGTCTGCCCATTCTTGCATTTCTTCTGGAACGTTAGTGAACGAGGAAAGGGGAAACGGAGGAACCCATGGTTCCGGAGGCTTTTTAAATATGCTTGTAGCGTTAGCGACGAGATTGTGATGCTGAAGGAAGAAATGTTGCGGTTGTTCTTCCTTTATTATGCGCAGAGCTTGTTCTGCGGATCCTGCATTTAACGCCTTGGCATATGTGTCGTTAGCAGACTGCTTGCCTCCTCGAGCAGATCTGCCGTCGATTTGGAACTCTCCCCATTCAATGGTGTCTCCGTCCTTGTCGATGTAAGACTTGACGTCGGAGCTGGATTTAGCTCCCTGAATGTTCGGATGGAAATGTACTGACCTGGTTGGGGACACCAGATCGAAGAATCTGTTACTCGTGCACTGGTATTTCCCCTCGAACTGGATAAGGACGTGCAGATGAGGTTCCCCATCTTCGTGTAATTCCCTGCAGATCTTGATAAATTTCTTGTTCACTGGCGTTTTTAGGTTTTTGATTTGGGAAAGTGCTTCTTCTTTAGTAAGAGAGCACTGGGGATATGTGAGGAAATAGTTCTTCGAGTGAACTCTAAACTTCTTAGGCGGTGGCATTTTTGTAATAAGAAGGGGTACACCAATTGAGCTCTCTCAAAACTGTCTCAAACAATCGGTGTATTGGGGTAACTTAAATACTAGAACCCTCAATCTCGGTTTGGGGACACGTGGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010087338.1
|
|
Location
|
185-940 |
|
Gene Name
|
AR1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGCCTAAGCGCGATGCCCCGTGGCGCTCGATGGCGGGAACATCAAAGGTTAGTCGCAATGTGAATTATTCTCCTCGTGGAGGCAGTGGCCCAAAATTAAACAGGGCCTCTGAATGGGTTAACAGGCCCATGTACAGGAAGCCCAGGATCTACCGAACACTGAGGACTCCTGATGTTCCAAGGGGATGTGAAGGCCCGTGTAAGGTACAGTCTTACGAACAGCGTCATGACATATCCCATGTCGGTAAGGTAATGTGTATATCTGACGTCACACGTGGAAATGGTATCACCCACCGTGTTGGCAAGCGTTTCTGTGTTAAGTCTGTGTATATTCTAGGCAAGATATGGATGGATGAGAATATCAAGCTGAAGAACCACACGAACAGCGTCATGTTCTGGCTGGTCAGGGACCGTAGACCGTATGGAACTCCCATGGACTTTGGCCAGGTGTTCAACATGTTTGACAACGAGCCCAGCACTGCCACAGTGAAGAACGATCTCCGTGATCGTTTCCAGGTCATGCATAAGTTTTATGGCAAGGTGACAGGTGGACAATATGCCAGCAATGAACAGGCAATCGTCAAGCGTTTCTGGAGGGTCAACAATCATGTGGTCTACAACCACCAGGAGGCTGGCAAGTACGAGAATCATACGGAGAACGCTTTGTTATTGTACATGGCATGTACACATGCCTCTAATCCCGTGTATGCAACGCTTAAGATTCGGATCTATTTTTATGATTCGATTTTAAATTAA |
|
Protein Sequence
|
MPKRDAPWRSMAGTSKVSRNVNYSPRGGSGPKLNRASEWVNRPMYRKPRIYRTLRTPDVPRGCEGPCKVQSYEQRHDISHVGKVMCISDVTRGNGITHRVGKRFCVKSVYILGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYGKVTGGQYASNEQAIVKRFWRVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSILN |
|
NCBI Accession
|
YP_010087339.1
|
|
Location
|
937-1326 |
|
Gene Name
|
AL3 |
|
Protein Name
|
replication enhancement protein |
|
Coding Region
|
ATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAGTGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCGAGATCACGTCGGTTGTGGAGCTCAACAGAGCGAAGAGGTACCGGTTCCAAATACGATTCAACCACAACCTCAGGAAGAAGCTGGGTCTTCTCAAGTGTTGGCTGAACCTGATGATCTGGACACCATCTCACTGGAACAGTACCAGTTTCTACAAGATATTCTGTTCGAGGATTAATCGTTACTTAGATAGATTAGGTGTCATTTGTATTAATAATGTAATTAGGGCTGTGACATACTCCGTCGATACGATGGACATCGAATGTAATGAGCTTCCACATGTAATAAAATTCAAGCTTTATTAA |
|
Protein Sequence
|
MDSRTGELITARQAESGVYIWEIENPLYFEITSVVELNRAKRYRFQIRFNHNLRKKLGLLKCWLNLMIWTPSHWNSTSFYKIFCSRINRYLDRLGVICINNVIRAVTYSVDTMDIECNELPHVIKFKLY |
|
NCBI Accession
|
YP_010087340.1
|
|
Location
|
1064-1462 |
|
Gene Name
|
AL2 |
|
Protein Name
|
transactivator protein |
|
Coding Region
|
ATGCGGTCTTCATCACCTTGCACTCCCCCCTCTATCAAGAAGAAACACAGGGAGGCCAAGAAAAGGGCGGTCAGACGACGCCGCATTGATCTGGAGTGCGGTTGCTCCATATATTTCCACATAGGCTGTACGGGACATGGATTCACGCACAGGGGAACTCATCACTGCACGTCAGGCAGAGAGTGGCGTGTATATCTGGGAGATAGAAAATCCCCTATATTTCGAGATCACGTCGGTTGTGGAGCTCAACAGAGCGAAGAGGTACCGGTTCCAAATACGATTCAACCACAACCTCAGGAAGAAGCTGGGTCTTCTCAAGTGTTGGCTGAACCTGATGATCTGGACACCATCTCACTGGAACAGTACCAGTTTCTACAAGATATTCTGTTCGAGGATTAA |
|
Protein Sequence
|
MRSSSPCTPPSIKKKHREAKKRAVRRRRIDLECGCSIYFHIGCTGHGFTHRGTHHCTSGREWRVYLGDRKSPIFRDHVGCGAQQSEEVPVPNTIQPQPQEEAGSSQVLAEPDDLDTISLEQYQFLQDILFED |
|
NCBI Accession
|
YP_010087341.1
|
|
Location
|
1374-2459 |
|
Gene Name
|
AL1 |
|
Protein Name
|
replication associated protein |
|
Coding Region
|
ATGCCACCGCCTAAGAAGTTTAGAGTTCACTCGAAGAACTATTTCCTCACATATCCCCAGTGCTCTCTTACTAAAGAAGAAGCACTTTCCCAAATCAAAAACCTAAAAACGCCAGTGAACAAGAAATTTATCAAGATCTGCAGGGAATTACACGAAGATGGGGAACCTCATCTGCACGTCCTTATCCAGTTCGAGGGGAAATACCAGTGCACGAGTAACAGATTCTTCGATCTGGTGTCCCCAACCAGGTCAGTACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCTTACATCGACAAGGACGGAGACACCATTGAATGGGGAGAGTTCCAAATCGACGGCAGATCTGCTCGAGGAGGCAAGCAGTCTGCTAACGACACATATGCCAAGGCGTTAAATGCAGGATCCGCAGAACAAGCTCTGCGCATAATAAAGGAAGAACAACCGCAACATTTCTTCCTTCAGCATCACAATCTCGTCGCTAACGCTACAAGCATATTTAAAAAGCCTCCGGAACCATGGGTTCCTCCGTTTCCCCTTTCCTCGTTCACTAACGTTCCAGAAGAAATGCAAGAATGGGCAGACGATTATTTTGGAAGAGATGCCGCTGCGCGGCCAGAAAGACCAGTGAGTCTCATAGTAGAAGGTGATTCAAGGACAGGGAAGACGATGTGGGCTCGGGCATTAGGCCCACATAATTATTTAAGTGGACACCTAGACTTCAATTCCAGAGTTTTCTCAGACGAAGTGGAATATAACGTCATTGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAGGATTTGATAGGCGCCCAAAAAGATTGGCAGTCAAATTGCAAGTACGGAAAGCCAGTCCTGATTAAAGGAGGGATCCCATCAATCGTGCTGTGCAATCCTGGCGAGGGTGCCAGCTATAAAGATTACCTGAACAAAGAGGAAAACACAGCTCTCAGGAACTGGACTTTAAAGAATGCGGTCTTCATCACCTTGCACTCCCCCCTCTATCAAGAAGAAACACAGGGAGGCCAAGAAAAGGGCGGTCAGACGACGCCGCATTGA |
|
Protein Sequence
|
MPPPKKFRVHSKNYFLTYPQCSLTKEEALSQIKNLKTPVNKKFIKICRELHEDGEPHLHVLIQFEGKYQCTSNRFFDLVSPTRSVHFHPNIQGAKSSSDVKSYIDKDGDTIEWGEFQIDGRSARGGKQSANDTYAKALNAGSAEQALRIIKEEQPQHFFLQHHNLVANATSIFKKPPEPWVPPFPLSSFTNVPEEMQEWADDYFGRDAAARPERPVSLIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVFSDEVEYNVIDDVAPHYLKLKHWKDLIGAQKDWQSNCKYGKPVLIKGGIPSIVLCNPGEGASYKDYLNKEENTALRNWTLKNAVFITLHSPLYQEETQGGQEKGGQTTPH |