Horsegram yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000840965.1 |
| Isolate |
India:Tamil Nadu |
| Release date |
2015/2/12 |
| Submitter |
Barnabas,A.D., Girish,K.R., Usha,R. |
| Host |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
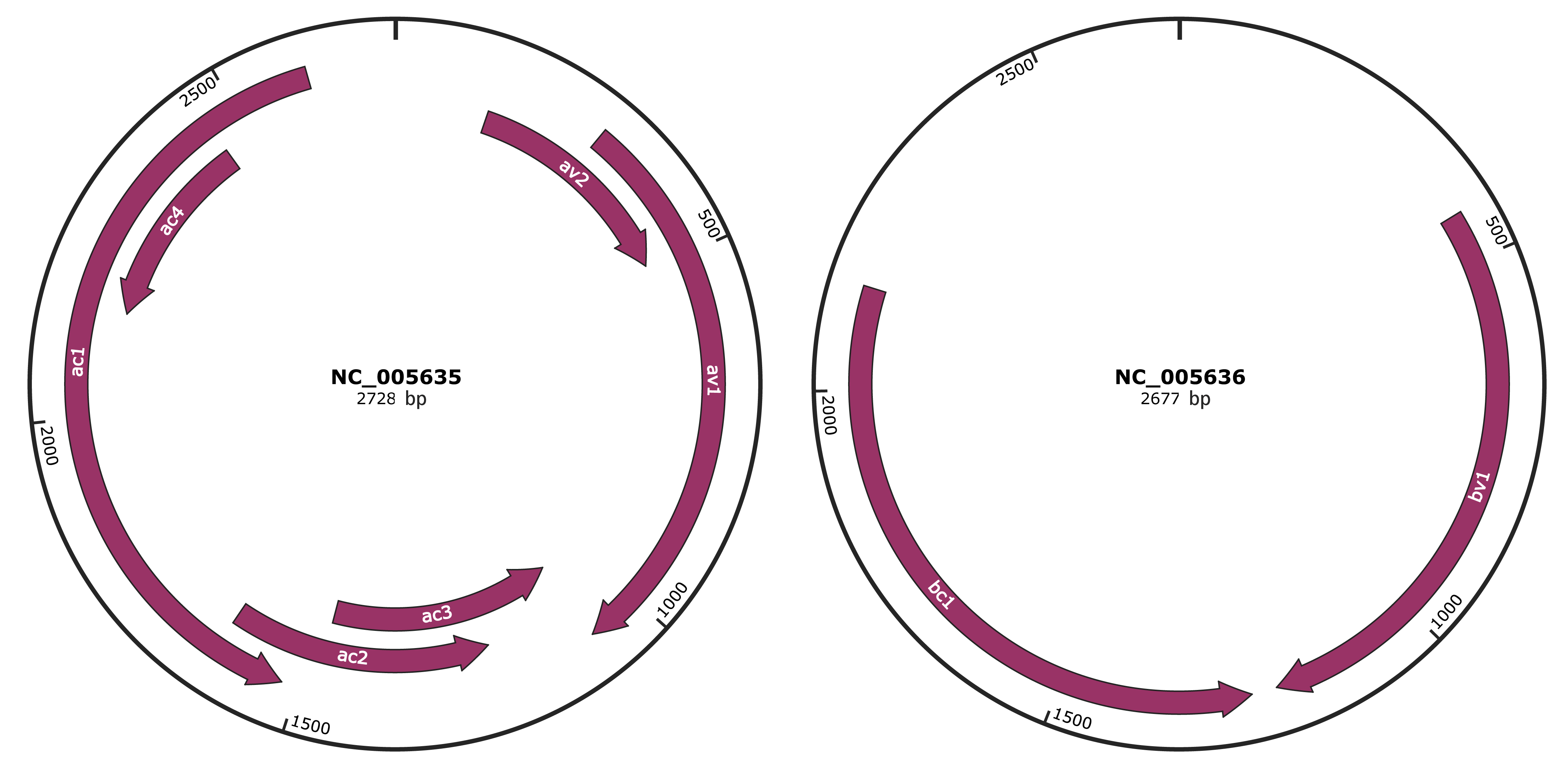
JBrowse
Genome
ACCTGAGTGCCCCGCGATCGTTCCACTCTGCTTTTGCTTTTGGACCGCTTTACTTTTAGTCGTTCAATGAGAAGCGCTCCTCAGCACTACGATAATTCAAATTTGAATTATAAAGCTAATAGCCACGTTGCATCGCACTAACCATGTGGGATCCATTGTTGAACGACTTTCCCAAAACAGTTCATGGTTTCCGTATGCTTGCAATTAAGTACTTGCAGCAAGTTCAAGAGAATTATTCCACTAATTCTGTTGGTTTTTTGTATATCACAGAGCTAATACAGGTATTACGCATTCGGAAACATGCCAAAGCGGAACTACGATACCGCCTTCTCTACCCCGGGATCCAGTGTTCGTCGGAGACTGACTTACGACACCCCCCTGGCGCTACCTGCTTCTGCGGGAAGTGCTCCTGCCAGCGTGAGAAGACGTCGGTGGACCAACCGTCCCATGTGGAGGAAACCGAGATTTTATCGGTTGTATCGCTCTCCTGATGTCCCACGTGGTTGTGAAGGACCGTGTAAGGTCCAATCATTTGAGGCGAGACATGACATCTCGCATGTGGGCAAAGTCATTTGTGTCACGGATGTGACTCGTGGTAGTGGTCTCACTCATCGTGTCGGTAAACGATTTTGTGTTAAGTCCATTTTTATTACTGGAAAGATTTGGATGGACGAAAACATCAAGACCAAGAATCACACTAACACTGTGATGTTCAGATTGGTTCGTGATAGGCGTCCTTTTGGAACGCCCCAGGACTTTGGTCAAGTTTTCAACATGTATGATAATGAACCCAGTACTGCCACTGTGAAGAACGATCTTCGTGATCGTTATCAGGTCGTGCGTAAGTTTCATGCCACCGTGACTGGTGGCCAGTATGCGTGCAAGGAGCAAGCTATAATTAGCCGATTTTATCGTGTTAATAATCATGTTGTTTACAACCATCAGGAAGCTGCGAAGTATGACAATCATACTGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCTTCTAATCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTTTACGATTCGATATCAAATTAATAAAGCTTGTATTGAACATTATGCGTAAAGCTTACATCCTCCACCAGGTGGAGTTTTTCATACAGGATATGTGAGGCGCCATTTAATACATTGCCTAAGCTAATGACGCCTAAATTATTTAAATATCTAAATAATTGGTTCCTAAAAATTGATAATATCATCCCAGAAGTCGTCGTCATATAGTGGTACAGCTTCAGGTCGAGGAAGCATTTGTGCATCTGCAATGCTTTCTTCAGTCCGTGGTTGAACATTAGGCGGATTTGGGTCACGATCATTCGGGACCCTGCTCCCATTGGACGATGTTGAAGGATCTTGAAAGAGAGGGGATTTCGCACCTCCCAGATATAGACGCCATTCCTGAGTTGAGCTGCAGTGATGTTGTCCCCGGTGCGAAAATCCATAGTTGCGACAGTTGATGTGAATGTAATAGCTACACCCACAGGTTAAGTCAATTCGAGAGCGTCGAATTGCTCGCTTCTTGGCAACCCTGTGTTGCGCTTTGATCGACGGAGGAGAAGAGTGGTTCTTTGAGGGTGTAGAATTCCGCATTTTTTGAAGCCCACACCTTTAGCGACGCATTATCAGCTTCGTCCAAGTACTCTTTATAAGAGGATTTGGGACCTGGGTTACAGAGAAAGATGGTGGGGATTCCACCTTTAATGTGTGTGGGCTTTCCGTATTTTACATTTGACTGCCAGTCTCTTTGCGCGCCCATGAATTCTTTGAAATGTTTCAAATAATGTGGATCAACGTCATCGATGACGTTATACCATGCCTCGTTAGAGAAAATCTTATCGTTCAGATCCAAATGGCCGCAAAGATAATTATGAGGACCCAATGCTCTTGCCCACATGGTTTTACCCGTCCGACTATCACCTTCAATCACTATACTTATGGGTCTCTCCGGCGCGCAGCGGGATCTTACATTTTCTGAAGCCCATGAAGAAATATATTCTGGGACTCTACTAAATGTATCTATACTATAAGGCGACACATATGCCTGAATAGGCGAAATGAAAATCTTATTCAAATTACAATTTAAATTATGAAATTGTAAAATATAATCTTTTGGAGCCTTCTCTTTCAATATATCGAGGGCCTGTGATTTGGATCCACAGTTGAGTGCCTCGGCATACGCGTCGTTTGCAGACTGTTTACCTCCTCTAGCCGATCTTCCATCGATTTGGAAGGTTCCATGATCAAGGACGTCTCCGTCTTTCTCCATGTATTGCTTAACATCTGAGCAGCTTTGAGCTGCCTGAATGTTCGGATGGAAATGTGTTGACCTGGTTGAGGATACCAGGTCGAAGAACCTTTGGTTACGTGTGTGGAATTTGCCTTCGAATTGCAGCAGAACATGGAGATGAGGTTCTCCATTCTCATAAGCTCTCGGCAGATGCGAATGAATCTTCTTGTTAACTGGTGTTGACAAATCTAATAGTTGCTCCAGTGTGTCCTCTTTAGTTAGAGGACAGCGAGGATATGTAAGGAAATAGTTTTTAGCGTTTATAGCAAAACGACGCTCTCTTGGCATTTTTAAAGTCGTTTTTGTATCGGTTGTCCACCGATTCTCATTTACTCCTGTCAATCGGTGAATGGTGACGCATATATAGTAGAGCTACTAATCCCCCAAGGGGCACTCAGCAATAATATT
ACCTGAGTGCCCCGCGACTGGGTGGGACCTGGATCACTCACGTGGGTGGTCCCGCTCATCGTGGCGCAACGAGGAGTCTCGTTGGGAGTTTTTATAATGGGTTACTACTTGGGAGAAGTGGGGAAACCGGAAGCTACCGCCGCAAATCGAGAAATTTGCTTTTAATGCGAAATTACGCTTTTTAGCAATCGGTGACCACCCTTGCCCTCCAATCAAATTCATTTGTTGAGGGTGTTTTTATGTCATTTCCACAAAATGACTCATTGCAACATAGTGTTTGAATTAAACAAACACGCGTCGTTGAATTTCGCGATCCTTATGTGGTTTTTAATTTGAGCGTCCATTAAGCCGATGTTAAACATACGATTTTGCTATAAATGTCGCTGTTGTGCCTATTAAAACCATGTGTAATGGTTTTGCCTTGTCTATTTGAGTATGTTTAACCGTAATTATCGTACTCCATCAAAATTGCGTAACAGTAATTTTGGTACTAAATGGAGTCACGTGACCCCCTCTAGAGCACGTGGACGTGCATTGAAGTACCCCGTGTCCCGTAGACTTTCATACGAGCGTATTGAGAGACCGCTAAGTACTAATACCATTGTTGAGGTTCAACATGGTAGTCATATGTCTCTCCAGAAGAACACTGACATTGCATCCTTTGTTCAATACCCCGTGCGAGGAATAAATGGCGATGGACGCTCTAGAGACTACATCAAGTTATTGAAACTTGATGTCTCCGGTGTCATTAATGTGAAGACAACGTCTATTGACCATACGATGGATCCAAGTGATAAACTCAGTGGTTTATTCGTTCTGACTATCTTATTAGACAGAAAACCCTATCTACCTGAAGGTGTGAACACGCTTCCTGGGTTCTCGGAGCTATTTGGCCCTTATGCATCTGCGTATGCAAACATGCATTTGCTAGATTCTCAAAAGAACCGTTTCAAGGTACTTGGTATTGTGAAGAAGTTCGTTGGATGTGCTTCTGGAGCAATATATGCACCTATTAACAAGTGCATCCCTTTGTCCAAGCGAAAGTACCCTTTGTGGGCTACTTTCAAAGACCCTGATCAAGGGAACTGTGGTGGAAATTACAAAAACATTTCTAAGAATGCAATTGTAATGAGCTATGCATTTATTTCATTGCATAGCCTAAGTGTGGAACCCTATGTCCAATTTGAACTCAAATATTTGGGCTGAAATAAATAAATACTTTTATTTATGCCTTCAACAATTACAAGGTTTTGTTTACAGTCGACTTCTGCGTTATTAGACATTTGTTAATAGCAGTTTCGATTATCTCTTCCATGTCTTTACGACTCATAGCATTTGATTGTGTTTGAGATATAGAGTCTCCTGGGTCTAAGGATGACTCATGTAACTTGTGCAAATGTCTAAGTGGATAGTCCGCATCTGATGTTGTTGGGTTGTCTTGGATACCGAGCCTGTCTTGGGTTGTGTATCTCATGGACGCACTCCTGCCGATACTGGACTTAGTGGCCCAAGTCTCTCCGGGCTGTAGCGTAATGGGCCTTTGGCCTTCAAAAACATCTGGACCCTGTTTAGGTCCAGGATTCAACAATCGTCTAATGGGCTTGGGCCTCTCAACAGACCAAAAGTCCACACAGTCTTTAGTAAAGTCCTTTGACAATATATTTATTGTTGGGGGTTTAAACCTTATGTCTGTTGAGTGTTTCGCTGAAGATAATTTCAGCTTTGCTTTAATCTGAGCGAATGTGGTTCCGTCGATCACGTTGGAGTCCTCCACCTTGTACACAATCTCCCATGGTGTGTCGTCCTTGAGGGAAAAGAACGACGAAGAGAAATAGTGTAGATCGACGTTACACCCAATTGGGAAAGTGAAAGCTGCTTGTGCAGCTTGTTCATAGCTTAATCTTGTGTCACGAATAGTGACTACGACTGATCCTTCAGCATTGAATGGGACTTGATTTCTGTACTCTATCACGGCGTGATCAACCTTCATGCATTTGCCCATGATTTGAACAGTCTTCTGTTCAAGATAAGAAGGAAATTGCAGCTTAATTGGGGTCTCATTATTGGTTAATCTGTATTCGCAACTCTTTGTCTCTACGTATTTGTTATTAACAACTGCACCGGAATAATGCTCCATTATTCAGCTTTGTGTTGCGAATAATTATCTGGAAAATAACACATGACAAGGGAATTATGAATTCATGAATAAATGGCCGCGCCAGCGGAAGTGACAACAAATATTATGTAAATCATAATATAAACCAAACAAATCAATCATGTGTTAGAGAAAAAATTAAATTAATACTTACTTAACGCCCAAAAGCTAAGCTAATTACAGAAGATGTGTATAGAGGGAGTAACAAATATTTTAAATAATATTTGTTTAATTGTGTCAACAACGAGGCGTTAATGTGTTTAAATAGTGCGCAGGAGTGTATAGATTGTGCGTATGAAAAATAAATTAATATTTAATTTATTAGCGATATATGGGTGCATCCAATGCTTCCAGGCAAAGTGGTGACAAAAGCGTTCAATTCTAGAGAGAGAAGCTCTCGTTTTAGAGAGAGAAGCTATTGGTGACATCCACCGATTGCCATTTACTCCTGTCTATCGGTGAATGGTGACGCATATATACTAGAGCTACTAATAGCCCATAGGGGCACTCAGTACTAATATT
Gene Information
|
NCBI Accession
|
NP_981934.1
|
|
Location
|
144-491 |
|
Gene Name
|
av2 |
|
Protein Name
|
AV2 protein |
|
Coding Region
|
ATGTGGGATCCATTGTTGAACGACTTTCCCAAAACAGTTCATGGTTTCCGTATGCTTGCAATTAAGTACTTGCAGCAAGTTCAAGAGAATTATTCCACTAATTCTGTTGGTTTTTTGTATATCACAGAGCTAATACAGGTATTACGCATTCGGAAACATGCCAAAGCGGAACTACGATACCGCCTTCTCTACCCCGGGATCCAGTGTTCGTCGGAGACTGACTTACGACACCCCCCTGGCGCTACCTGCTTCTGCGGGAAGTGCTCCTGCCAGCGTGAGAAGACGTCGGTGGACCAACCGTCCCATGTGGAGGAAACCGAGATTTTATCGGTTGTATCGCTCTCCTGA |
|
Protein Sequence
|
MWDPLLNDFPKTVHGFRMLAIKYLQQVQENYSTNSVGFLYITELIQVLRIRKHAKAELRYRLLYPGIQCSSETDLRHPPGATCFCGKCSCQREKTSVDQPSHVEETEILSVVSLS |
|
NCBI Accession
|
NP_981935.1
|
|
Location
|
301-1074 |
|
Gene Name
|
av1 |
|
Protein Name
|
AV1 protein |
|
Coding Region
|
ATGCCAAAGCGGAACTACGATACCGCCTTCTCTACCCCGGGATCCAGTGTTCGTCGGAGACTGACTTACGACACCCCCCTGGCGCTACCTGCTTCTGCGGGAAGTGCTCCTGCCAGCGTGAGAAGACGTCGGTGGACCAACCGTCCCATGTGGAGGAAACCGAGATTTTATCGGTTGTATCGCTCTCCTGATGTCCCACGTGGTTGTGAAGGACCGTGTAAGGTCCAATCATTTGAGGCGAGACATGACATCTCGCATGTGGGCAAAGTCATTTGTGTCACGGATGTGACTCGTGGTAGTGGTCTCACTCATCGTGTCGGTAAACGATTTTGTGTTAAGTCCATTTTTATTACTGGAAAGATTTGGATGGACGAAAACATCAAGACCAAGAATCACACTAACACTGTGATGTTCAGATTGGTTCGTGATAGGCGTCCTTTTGGAACGCCCCAGGACTTTGGTCAAGTTTTCAACATGTATGATAATGAACCCAGTACTGCCACTGTGAAGAACGATCTTCGTGATCGTTATCAGGTCGTGCGTAAGTTTCATGCCACCGTGACTGGTGGCCAGTATGCGTGCAAGGAGCAAGCTATAATTAGCCGATTTTATCGTGTTAATAATCATGTTGTTTACAACCATCAGGAAGCTGCGAAGTATGACAATCATACTGAGAACGCTTTGTTATTGTATATGGCATGTACTCATGCTTCTAATCCTGTGTATGCAACGCTTAAGATTCGGATCTATTTTTACGATTCGATATCAAATTAA |
|
Protein Sequence
|
MPKRNYDTAFSTPGSSVRRRLTYDTPLALPASAGSAPASVRRRRWTNRPMWRKPRFYRLYRSPDVPRGCEGPCKVQSFEARHDISHVGKVICVTDVTRGSGLTHRVGKRFCVKSIFITGKIWMDENIKTKNHTNTVMFRLVRDRRPFGTPQDFGQVFNMYDNEPSTATVKNDLRDRYQVVRKFHATVTGGQYACKEQAIISRFYRVNNHVVYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
NP_981936.1
|
|
Location
|
1071-1475 |
|
Gene Name
|
ac3 |
|
Protein Name
|
AC3 protein |
|
Coding Region
|
ATGGATTTTCGCACCGGGGACAACATCACTGCAGCTCAACTCAGGAATGGCGTCTATATCTGGGAGGTGCGAAATCCCCTCTCTTTCAAGATCCTTCAACATCGTCCAATGGGAGCAGGGTCCCGAATGATCGTGACCCAAATCCGCCTAATGTTCAACCACGGACTGAAGAAAGCATTGCAGATGCACAAATGCTTCCTCGACCTGAAGCTGTACCACTATATGACGACGACTTCTGGGATGATATTATCAATTTTTAGGAACCAATTATTTAGATATTTAAATAATTTAGGCGTCATTAGCTTAGGCAATGTATTAAATGGCGCCTCACATATCCTGTATGAAAAACTCCACCTGGTGGAGGATGTAAGCTTTACGCATAATGTTCAATACAAGCTTTATTAA |
|
Protein Sequence
|
MDFRTGDNITAAQLRNGVYIWEVRNPLSFKILQHRPMGAGSRMIVTQIRLMFNHGLKKALQMHKCFLDLKLYHYMTTTSGMILSIFRNQLFRYLNNLGVISLGNVLNGASHILYEKLHLVEDVSFTHNVQYKLY |
|
NCBI Accession
|
NP_981937.1
|
|
Location
|
1216-1623 |
|
Gene Name
|
ac2 |
|
Protein Name
|
AC2 protein |
|
Coding Region
|
ATGCGGAATTCTACACCCTCAAAGAACCACTCTTCTCCTCCGTCGATCAAAGCGCAACACAGGGTTGCCAAGAAGCGAGCAATTCGACGCTCTCGAATTGACTTAACCTGTGGGTGTAGCTATTACATTCACATCAACTGTCGCAACTATGGATTTTCGCACCGGGGACAACATCACTGCAGCTCAACTCAGGAATGGCGTCTATATCTGGGAGGTGCGAAATCCCCTCTCTTTCAAGATCCTTCAACATCGTCCAATGGGAGCAGGGTCCCGAATGATCGTGACCCAAATCCGCCTAATGTTCAACCACGGACTGAAGAAAGCATTGCAGATGCACAAATGCTTCCTCGACCTGAAGCTGTACCACTATATGACGACGACTTCTGGGATGATATTATCAATTTTTAG |
|
Protein Sequence
|
MRNSTPSKNHSSPPSIKAQHRVAKKRAIRRSRIDLTCGCSYYIHINCRNYGFSHRGQHHCSSTQEWRLYLGGAKSPLFQDPSTSSNGSRVPNDRDPNPPNVQPRTEESIADAQMLPRPEAVPLYDDDFWDDIINF |
|
NCBI Accession
|
NP_981938.1
|
|
Location
|
1523-2608 |
|
Gene Name
|
ac1 |
|
Protein Name
|
AC1 protein |
|
Coding Region
|
ATGCCAAGAGAGCGTCGTTTTGCTATAAACGCTAAAAACTATTTCCTTACATATCCTCGCTGTCCTCTAACTAAAGAGGACACACTGGAGCAACTATTAGATTTGTCAACACCAGTTAACAAGAAGATTCATTCGCATCTGCCGAGAGCTTATGAGAATGGAGAACCTCATCTCCATGTTCTGCTGCAATTCGAAGGCAAATTCCACACACGTAACCAAAGGTTCTTCGACCTGGTATCCTCAACCAGGTCAACACATTTCCATCCGAACATTCAGGCAGCTCAAAGCTGCTCAGATGTTAAGCAATACATGGAGAAAGACGGAGACGTCCTTGATCATGGAACCTTCCAAATCGATGGAAGATCGGCTAGAGGAGGTAAACAGTCTGCAAACGACGCGTATGCCGAGGCACTCAACTGTGGATCCAAATCACAGGCCCTCGATATATTGAAAGAGAAGGCTCCAAAAGATTATATTTTACAATTTCATAATTTAAATTGTAATTTGAATAAGATTTTCATTTCGCCTATTCAGGCATATGTGTCGCCTTATAGTATAGATACATTTAGTAGAGTCCCAGAATATATTTCTTCATGGGCTTCAGAAAATGTAAGATCCCGCTGCGCGCCGGAGAGACCCATAAGTATAGTGATTGAAGGTGATAGTCGGACGGGTAAAACCATGTGGGCAAGAGCATTGGGTCCTCATAATTATCTTTGCGGCCATTTGGATCTGAACGATAAGATTTTCTCTAACGAGGCATGGTATAACGTCATCGATGACGTTGATCCACATTATTTGAAACATTTCAAAGAATTCATGGGCGCGCAAAGAGACTGGCAGTCAAATGTAAAATACGGAAAGCCCACACACATTAAAGGTGGAATCCCCACCATCTTTCTCTGTAACCCAGGTCCCAAATCCTCTTATAAAGAGTACTTGGACGAAGCTGATAATGCGTCGCTAAAGGTGTGGGCTTCAAAAAATGCGGAATTCTACACCCTCAAAGAACCACTCTTCTCCTCCGTCGATCAAAGCGCAACACAGGGTTGCCAAGAAGCGAGCAATTCGACGCTCTCGAATTGA |
|
Protein Sequence
|
MPRERRFAINAKNYFLTYPRCPLTKEDTLEQLLDLSTPVNKKIHSHLPRAYENGEPHLHVLLQFEGKFHTRNQRFFDLVSSTRSTHFHPNIQAAQSCSDVKQYMEKDGDVLDHGTFQIDGRSARGGKQSANDAYAEALNCGSKSQALDILKEKAPKDYILQFHNLNCNLNKIFISPIQAYVSPYSIDTFSRVPEYISSWASENVRSRCAPERPISIVIEGDSRTGKTMWARALGPHNYLCGHLDLNDKIFSNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNVKYGKPTHIKGGIPTIFLCNPGPKSSYKEYLDEADNASLKVWASKNAEFYTLKEPLFSSVDQSATQGCQEASNSTLSN |
|
NCBI Accession
|
NP_981939.1
|
|
Location
|
2158-2457 |
|
Gene Name
|
ac4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAGAATGGAGAACCTCATCTCCATGTTCTGCTGCAATTCGAAGGCAAATTCCACACACGTAACCAAAGGTTCTTCGACCTGGTATCCTCAACCAGGTCAACACATTTCCATCCGAACATTCAGGCAGCTCAAAGCTGCTCAGATGTTAAGCAATACATGGAGAAAGACGGAGACGTCCTTGATCATGGAACCTTCCAAATCGATGGAAGATCGGCTAGAGGAGGTAAACAGTCTGCAAACGACGCGTATGCCGAGGCACTCAACTGTGGATCCAAATCACAGGCCCTCGATATATTGA |
|
Protein Sequence
|
MRMENLISMFCCNSKANSTHVTKGSSTWYPQPGQHISIRTFRQLKAAQMLSNTWRKTETSLIMEPSKSMEDRLEEVNSLQTTRMPRHSTVDPNHRPSIY |
|
NCBI Accession
|
NP_981940.1
|
|
Location
|
436-1206 |
|
Gene Name
|
bv1 |
|
Protein Name
|
BV1 protein |
|
Coding Region
|
ATGTTTAACCGTAATTATCGTACTCCATCAAAATTGCGTAACAGTAATTTTGGTACTAAATGGAGTCACGTGACCCCCTCTAGAGCACGTGGACGTGCATTGAAGTACCCCGTGTCCCGTAGACTTTCATACGAGCGTATTGAGAGACCGCTAAGTACTAATACCATTGTTGAGGTTCAACATGGTAGTCATATGTCTCTCCAGAAGAACACTGACATTGCATCCTTTGTTCAATACCCCGTGCGAGGAATAAATGGCGATGGACGCTCTAGAGACTACATCAAGTTATTGAAACTTGATGTCTCCGGTGTCATTAATGTGAAGACAACGTCTATTGACCATACGATGGATCCAAGTGATAAACTCAGTGGTTTATTCGTTCTGACTATCTTATTAGACAGAAAACCCTATCTACCTGAAGGTGTGAACACGCTTCCTGGGTTCTCGGAGCTATTTGGCCCTTATGCATCTGCGTATGCAAACATGCATTTGCTAGATTCTCAAAAGAACCGTTTCAAGGTACTTGGTATTGTGAAGAAGTTCGTTGGATGTGCTTCTGGAGCAATATATGCACCTATTAACAAGTGCATCCCTTTGTCCAAGCGAAAGTACCCTTTGTGGGCTACTTTCAAAGACCCTGATCAAGGGAACTGTGGTGGAAATTACAAAAACATTTCTAAGAATGCAATTGTAATGAGCTATGCATTTATTTCATTGCATAGCCTAAGTGTGGAACCCTATGTCCAATTTGAACTCAAATATTTGGGCTGA |
|
Protein Sequence
|
MFNRNYRTPSKLRNSNFGTKWSHVTPSRARGRALKYPVSRRLSYERIERPLSTNTIVEVQHGSHMSLQKNTDIASFVQYPVRGINGDGRSRDYIKLLKLDVSGVINVKTTSIDHTMDPSDKLSGLFVLTILLDRKPYLPEGVNTLPGFSELFGPYASAYANMHLLDSQKNRFKVLGIVKKFVGCASGAIYAPINKCIPLSKRKYPLWATFKDPDQGNCGGNYKNISKNAIVMSYAFISLHSLSVEPYVQFELKYLG |
|
NCBI Accession
|
NP_981941.1
|
|
Location
|
1241-2137 |
|
Gene Name
|
bc1 |
|
Protein Name
|
BC1 protein |
|
Coding Region
|
ATGGAGCATTATTCCGGTGCAGTTGTTAATAACAAATACGTAGAGACAAAGAGTTGCGAATACAGATTAACCAATAATGAGACCCCAATTAAGCTGCAATTTCCTTCTTATCTTGAACAGAAGACTGTTCAAATCATGGGCAAATGCATGAAGGTTGATCACGCCGTGATAGAGTACAGAAATCAAGTCCCATTCAATGCTGAAGGATCAGTCGTAGTCACTATTCGTGACACAAGATTAAGCTATGAACAAGCTGCACAAGCAGCTTTCACTTTCCCAATTGGGTGTAACGTCGATCTACACTATTTCTCTTCGTCGTTCTTTTCCCTCAAGGACGACACACCATGGGAGATTGTGTACAAGGTGGAGGACTCCAACGTGATCGACGGAACCACATTCGCTCAGATTAAAGCAAAGCTGAAATTATCTTCAGCGAAACACTCAACAGACATAAGGTTTAAACCCCCAACAATAAATATATTGTCAAAGGACTTTACTAAAGACTGTGTGGACTTTTGGTCTGTTGAGAGGCCCAAGCCCATTAGACGATTGTTGAATCCTGGACCTAAACAGGGTCCAGATGTTTTTGAAGGCCAAAGGCCCATTACGCTACAGCCCGGAGAGACTTGGGCCACTAAGTCCAGTATCGGCAGGAGTGCGTCCATGAGATACACAACCCAAGACAGGCTCGGTATCCAAGACAACCCAACAACATCAGATGCGGACTATCCACTTAGACATTTGCACAAGTTACATGAGTCATCCTTAGACCCAGGAGACTCTATATCTCAAACACAATCAAATGCTATGAGTCGTAAAGACATGGAAGAGATAATCGAAACTGCTATTAACAAATGTCTAATAACGCAGAAGTCGACTGTAAACAAAACCTTGTAA |
|
Protein Sequence
|
MEHYSGAVVNNKYVETKSCEYRLTNNETPIKLQFPSYLEQKTVQIMGKCMKVDHAVIEYRNQVPFNAEGSVVVTIRDTRLSYEQAAQAAFTFPIGCNVDLHYFSSSFFSLKDDTPWEIVYKVEDSNVIDGTTFAQIKAKLKLSSAKHSTDIRFKPPTINILSKDFTKDCVDFWSVERPKPIRRLLNPGPKQGPDVFEGQRPITLQPGETWATKSSIGRSASMRYTTQDRLGIQDNPTTSDADYPLRHLHKLHESSLDPGDSISQTQSNAMSRKDMEEIIETAINKCLITQKSTVNKTL |