Honeysuckle yellow vein virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000859185.1 |
| Isolate | United Kingdom:Norfolk |
| Release date | 2015/2/13 |
| Submitter | Briddon,R.W. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
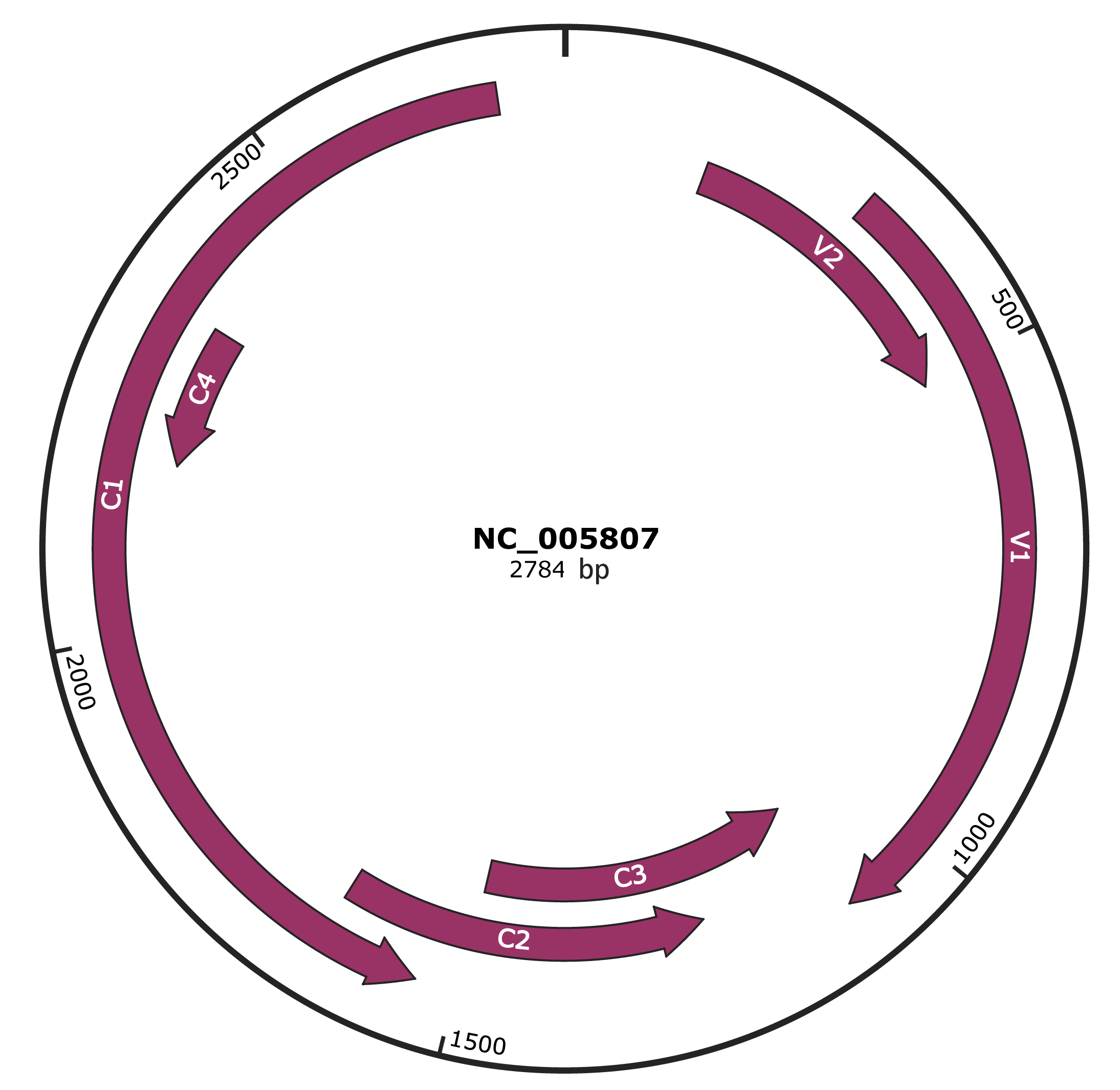
JBrowse
Genome
NC_005807
Gene Information
| NCBI Accession | NP_991332.1 |
|---|---|
| Location | 159-509 |
| Gene Name | V2 |
| Protein Name | V2 protein |
| Coding Region | ATGTGGGATCCTTTAGTTAACGATTTCCCTGAAACCGTTCACGGTTTTAGGTGTATGTTAGCGGTTAAGTACCTCCTACTTGTTGAATCTACGTACGCTCCAGATACTGTTGGGTACGATCTTGTACGCGATCTTATTGGAGTTGTTCGAGCTAAGAACTATGTCGAAGCGTCCTGCAGATATAGGAATTTTCACACCCGTCTCCAAGGTACGGCGCCGTCTGAACTTCGACAGCCCGTATGTCAGCCGTGCGAGTGCCCCCATTGCCCTCGTCACAAACAAAAGGAGATCATGGGCTCAGCGGCCCATGTATCGGAAGCCCAGGATGTACAGAATGTACAGAAGTCCTGA |
| Protein Sequence | MWDPLVNDFPETVHGFRCMLAVKYLLLVESTYAPDTVGYDLVRDLIGVVRAKNYVEASCRYRNFHTRLQGTAPSELRQPVCQPCECPHCPRHKQKEIMGSAAHVSEAQDVQNVQKS |
| NCBI Accession | NP_991333.1 |
|---|---|
| Location | 319-1092 |
| Gene Name | V1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGTCCTGCAGATATAGGAATTTTCACACCCGTCTCCAAGGTACGGCGCCGTCTGAACTTCGACAGCCCGTATGTCAGCCGTGCGAGTGCCCCCATTGCCCTCGTCACAAACAAAAGGAGATCATGGGCTCAGCGGCCCATGTATCGGAAGCCCAGGATGTACAGAATGTACAGAAGTCCTGATGTTCCCAAGGGGTGTGAAGGTCCGTGTAAGGTACAGTCATTTGAGACGAAGAATGATGTTGGGCATTCTGGTACTCTGCTCTGTGTTTCTGATATCACCCGTGGTAATGGACTTACTCATCGTGTTGGGAAGAGATTTTGTATAAAATCTGTTTATATTATTGGTAAAATCTGGATGGATGACAATATTAAGACGAAGAATCACACTAACAACGTGTTATTCTGGTTAGTTAGGGATAGACGTCCTGGTTCAACTCCTTATGGATTCCAAGAGGCATTCAATATGATTCAAAATGAGCCCAGTACAGCCACTATTAAACAGGAGTTGAGAGATCGTTTGCAGGTGTTACATAGGTTCAGTGCGACTGTTACAGGTGGACAATATGTGTCCAAGGAACAAGCTATCATCAAGAGGTTCTGGAAGTTGAATCATCATGTCACTTACAATCATCAGGAGCAAGCTAAATATGAGAACCATACTGAAAATGCTTTGTTATTGTATATGGCGTGTACTCATGCCAGTAATCCAGTGTATGCCACATTAAAAATCAGAGTGTATTTCTACGATTCAGTACAAAATTAA |
| Protein Sequence | MSKRPADIGIFTPVSKVRRRLNFDSPYVSRASAPIALVTNKRRSWAQRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSFETKNDVGHSGTLLCVSDITRGNGLTHRVGKRFCIKSVYIIGKIWMDDNIKTKNHTNNVLFWLVRDRRPGSTPYGFQEAFNMIQNEPSTATIKQELRDRLQVLHRFSATVTGGQYVSKEQAIIKRFWKLNHHVTYNHQEQAKYENHTENALLLYMACTHASNPVYATLKIRVYFYDSVQN |
| NCBI Accession | NP_991334.1 |
|---|---|
| Location | 1089-1493 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCACGCACAGGGGACACCATCACTGCAGCTCAGGCAAGGAATGGTGCGTATACCTGGACAGTGCCCAATCCCCTATATTTCAAAATCACGACACACGCGCAACGGCCACTCAACATGGATCAGGATATAATAACTTTACAGATACAATTCAACCACAACCTCAGGAATCAACTGCACATACACAAGTGCTTCCTCTCTTTCAAGATTTGGACTCGCTTACATCCTCAGACTTTGCATTTCTTGAGGGTATTTAGGACACAAGTGTTGAAGTACTTAGATAATTTGGGTGTAATATCAATTAACAATGTAATTAGAGCAGTAGATCATGTATTATATAATGTATTCGAAGGAACTGAATGTGTACAACAATTTACAGATATAAAATTTAAGCTTTATTAA |
| Protein Sequence | MDSRTGDTITAAQARNGAYTWTVPNPLYFKITTHAQRPLNMDQDIITLQIQFNHNLRNQLHIHKCFLSFKIWTRLHPQTLHFLRVFRTQVLKYLDNLGVISINNVIRAVDHVLYNVFEGTECVQQFTDIKFKLY |
| NCBI Accession | NP_991335.1 |
|---|---|
| Location | 1234-1641 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCAGCCTTCGTCACCCTCTACGGCCCACTCTACTCAGGTACCCATCAAGGTGCGACACAGATCAGAGAAGAGGAGAGCACCTCGCCGGAGGAGGATTGATCTGAACTGCGGGTGTTCTATTTACGTCGCATTGGGGTGTGCAAATCATGGATTCACGCACAGGGGACACCATCACTGCAGCTCAGGCAAGGAATGGTGCGTATACCTGGACAGTGCCCAATCCCCTATATTTCAAAATCACGACACACGCGCAACGGCCACTCAACATGGATCAGGATATAATAACTTTACAGATACAATTCAACCACAACCTCAGGAATCAACTGCACATACACAAGTGCTTCCTCTCTTTCAAGATTTGGACTCGCTTACATCCTCAGACTTTGCATTTCTTGAGGGTATTTAG |
| Protein Sequence | MQPSSPSTAHSTQVPIKVRHRSEKRRAPRRRRIDLNCGCSIYVALGCANHGFTHRGHHHCSSGKEWCVYLDSAQSPIFQNHDTRATATQHGSGYNNFTDTIQPQPQESTAHTQVLPLFQDLDSLTSSDFAFLEGI |
| NCBI Accession | NP_991336.1 |
|---|---|
| Location | 1541-2719 |
| Gene Name | C1 |
| Protein Name | replication associated protein |
| Coding Region | ATGCCATGCCCCCCAGAATATAAATTGCCCCCCAATGCCCCCCCATTCAGCAGGAGTTTGAAGTGCCCCCCAATTGACCAAGTCAACATGCCTAGAGCTGGGCGTTTCTCTTTAAAAGCCAAAAATTATTTCCTCACATACCCACAATGCTCCATCGACAAAGAAGAAGCCCTAACCCAATTACAAAAATTAAACACACCAACTAACATTAAATTCATAAGGATCTGCAGAGAGCTACATCAAAATGGGAGCCCTCATCTCCACGTCCTCATCCAGTTCGAGGGGAAATACAACTGCACAAATCAACGATTCTTCGACCTAGTATCCCCAAGCAGGTCAGCACATTTCCATCCCAACATTCAGGCGGCTAAAAGCTCGTCAGATGTCAAGACCTATATGGAGAAAGACGGAGACATCGTTGATTTTGGAGTGTTCCAGGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAGTCTGCCACCGACGCGTATGCCGAGGCAATCAACTCAGGATCTAAGTCATCGGCACTCTGTATATTAAGGGAGAAAGCTCCCAAAGATTTTGTTTTACAATTTCATAATTTAAATAGCAATTTAGATAGGATTTTTGCTCCTCCGTTGGAGGAATTTGTTTCTCCTTTTTTATCTTCTTCATTTGATCAAGTTCCAGAGCAACTTGAGGGATGGGCTGCCGAGAACGTCAGGGATTCCGCTGCGCGGCCATGGAGGCCCATTAGCATTGTGATAGAAGGGGATAGCAGGACAGGGAAGACCATGTGGGCCAGGTCTTTGAGTCCACGTCATAACTACCTTTGCGGCCATCTTGACTTAAGCCCCAAGGTTTACAGCAACGAGGCCTGGTACAACGTCATTGATGACGTGGATCCCCACTATCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAAAGCAACACCAAGTACGGGAAACCAATTCAAATTAAAGGAGGTATCCCAACAATCTTCCTCTGCAATCCAGGCCCAACGTCATCATACACCGAGTATTTAGACGAGGACAAGAATGCTGCCCTAAAAGCCTGGGCAATTAAAAATGCAGCCTTCGTCACCCTCTACGGCCCACTCTACTCAGGTACCCATCAAGGTGCGACACAGATCAGAGAAGAGGAGAGCACCTCGCCGGAGGAGGATTGA |
| Protein Sequence | MPCPPEYKLPPNAPPFSRSLKCPPIDQVNMPRAGRFSLKAKNYFLTYPQCSIDKEEALTQLQKLNTPTNIKFIRICRELHQNGSPHLHVLIQFEGKYNCTNQRFFDLVSPSRSAHFHPNIQAAKSSSDVKTYMEKDGDIVDFGVFQVDGRSARGGCQSATDAYAEAINSGSKSSALCILREKAPKDFVLQFHNLNSNLDRIFAPPLEEFVSPFLSSSFDQVPEQLEGWAAENVRDSAARPWRPISIVIEGDSRTGKTMWARSLSPRHNYLCGHLDLSPKVYSNEAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYTEYLDEDKNAALKAWAIKNAAFVTLYGPLYSGTHQGATQIREEESTSPEED |
| NCBI Accession | NP_991337.1 |
|---|---|
| Location | 2182-2337 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGTCAAGACCTATATGGAGAAAGACGGAGACATCGTTGATTTTGGAGTGTTCCAGGTCGATGGAAGATCAGCTAGAGGAGGTTGCCAGTCTGCCACCGACGCGTATGCCGAGGCAATCAACTCAGGATCTAAGTCATCGGCACTCTGTATATTAA |
| Protein Sequence | MSRPIWRKTETSLILECSRSMEDQLEEVASLPPTRMPRQSTQDLSHRHSVY |
References More References in PubMed
| 1 |
Ogawa T, et al. Virus Res. 2008 Nov;137(2):235-44. doi: 10.1016/j.virusres.2008.07.021. Epub 2008 Sep 13. PMID: 18722488 |
|---|---|
| 2 |
Evolutionary Changes in Tomato Yellow Leaf Curl Virus Associated with Widespread Ty-1 use in Japan. Nakajima M, et al. Phytopathology. 2026 May 28. doi: 10.1094/PHYTO-03-26-0062-R. Online ahead of print. PMID: 42208597 |
| 3 |
Lee G, et al. Arch Virol. 2011 May;156(5):785-91. doi: 10.1007/s00705-011-0916-0. Epub 2011 Jan 30. PMID: 21279729 |
| 4 |
Kitamura K, et al. Arch Virol. 2004 Jun;149(6):1221-9. doi: 10.1007/s00705-003-0276-5. Epub 2004 Feb 16. PMID: 15168208 |
| 5 |
Saunders K, et al. J Gen Virol. 2008 Dec;89(Pt 12):3165-3172. doi: 10.1099/vir.0.2008/003848-0. PMID: 19008407 |
| 6 |
Ueda S, et al. Arch Virol. 2008;153(3):417-26. doi: 10.1007/s00705-007-0011-8. Epub 2008 Jan 4. PMID: 18175045 |
| 7 |
A Novel Geminivirus of Ipomoea indica (Convolvulacae) from Southern Spain. Banks GK, et al. Plant Dis. 1999 May;83(5):486. doi: 10.1094/PDIS.1999.83.5.486B. PMID: 30845545 |
| 8 |
Kim NS, et al. Front Plant Sci. 2024 Jul 23;15:1407240. doi: 10.3389/fpls.2024.1407240. eCollection 2024. PMID: 39109056 |
| 9 |
Interaction of tomato yellow leaf curl virus with diverse betasatellites enhances symptom severity. Ito T, et al. Arch Virol. 2009;154(8):1233-9. doi: 10.1007/s00705-009-0431-8. Epub 2009 Jul 3. PMID: 19575277 |
| 10 |
Kim NS, et al. Front Bioeng Biotechnol. 2025 Nov 14;13:1693569. doi: 10.3389/fbioe.2025.1693569. eCollection 2025. PMID: 41323469 |