Hollyhock yellow vein mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000896675.1 |
| Isolate | Pakistan:Lahore |
| Release date | 2015/2/22 |
| Submitter | Zia Ur Rehman,M., Haider,M.S., Zia ur Rehman,M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
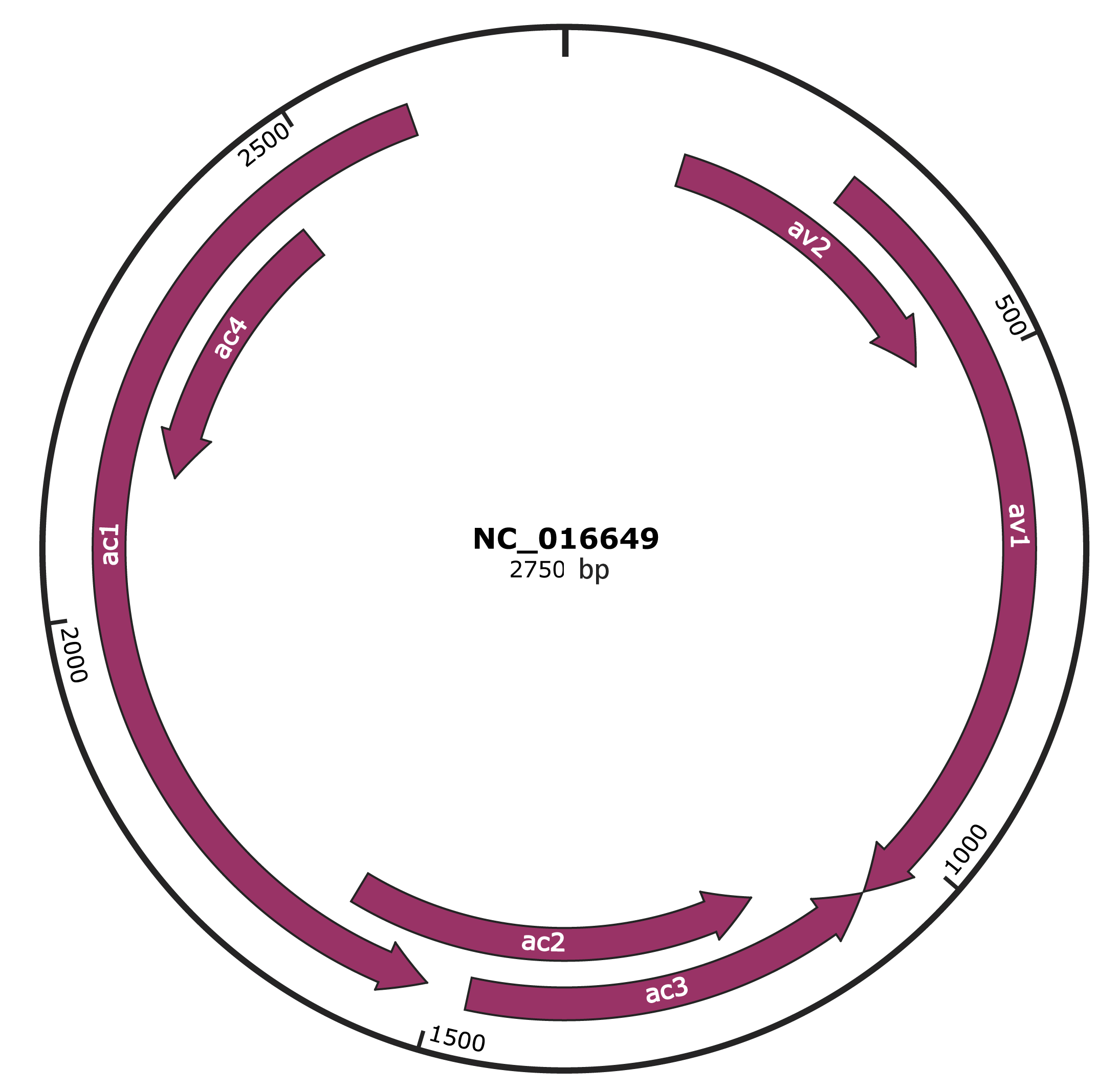
JBrowse
Genome
NC_016649
Gene Information
| NCBI Accession | YP_005086953.1 |
|---|---|
| Location | 131-478 |
| Gene Name | av2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCACTGTTAAACGAGTTCCCTGAGACTGTTCACGGGTTTCGTTGCATGCTTGCGATTAAATATCTTCAACAACTGTCTGAAGAATACTCTCCTGATACGGTAGGTTACGATCTAATTCGCGATTTAATTTCTATTTTACGTTCCAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAGTCTCGCATTTGGGCGAACAGGCCCATGTATCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPETVHGFRCMLAIKYLQQLSEEYSPDTVGYDLIRDLISILRSRNYVEASCRYRHFYPRVEGASSTELRQPLCNPCSCPHCPRHKVSHLGEQAHVSEAQNVQDVQKP |
| NCBI Accession | YP_005086954.1 |
|---|---|
| Location | 291-1061 |
| Gene Name | av1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGTCGACTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGCCCCCACTGTCCGCGTCACAAAGTCTCGCATTTGGGCGAACAGGCCCATGTATCGGAAGCCCAGAATGTACAGGATGTACAGAAGCCCTGATGTTCCTAAGGGTTGTGAAGGCCCATGTAAGGTGCAGTCTTTCGATGCGAAAAATGATATTGGGCATATGGGTAAGGTAATTTGTCTTTCTGATGTTACTAGGGGTATTGGGCTGACCCATCGAGTAGGGAAACGTTTTTGCGTTAAGTCATTGTATTTTGTTGGCAAAATATGGATGGACGAGAACATCAAGACTAAGAACCATACAAACACTGTTTTGTTCTGGATCGTGAGAGACAGGCGTCCTTCAGGAACTCCTAATGATTTCCAGCAAGTTTTCAATGTTTATGATAACGAGCCTTCTACGGCTACTGTGAAGAACGACCAGCGTAATCGTTTTCAGGTGTTGAGGAGGTTCCAGGCAACAGTCACAGGTGGTCAATATGCTGCTAAGGAACAAGCTATAATCAGGAAATTCTATCGTGTTAACAATTATGTTGTCTATAATCACCAGGAAGCTGGGAAGTATGAGAATCACACTGAGAATGCTTTGTTGTTGTACATGGCATGTACCCATGCCTCTAACCCCGTGTATGCTACTTTGAAAGTTAGAAGTTATTTCTATGATTCTGTAACCAATTAA |
| Protein Sequence | MSKRPADIVISTPASKVRRRLNFDSPYATRAVAPTVRVTKSRIWANRPMYRKPRMYRMYRSPDVPKGCEGPCKVQSFDAKNDIGHMGKVICLSDVTRGIGLTHRVGKRFCVKSLYFVGKIWMDENIKTKNHTNTVLFWIVRDRRPSGTPNDFQQVFNVYDNEPSTATVKNDQRNRFQVLRRFQATVTGGQYAAKEQAIIRKFYRVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKVRSYFYDSVTN |
| NCBI Accession | YP_005086955.1 |
|---|---|
| Location | 1064-1468 |
| Gene Name | ac3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTTACGCACAGAGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATATCTGGGAAGTACCAAATCCCCTTTATTTCAAGATCCTAAGCCACGAGGTCTGTCCTTACTCGAGCAAGATGGACATAATAACAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCGGGTTTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACCCAAGTCATAAAGTATCTCAACAATATAGGAGTAATCTCAATTAATTCGATTATTAGAGCAGTAGATCATGTATTGTACAGTAAAATAGAACAAACTATGTATGTAGACCAAGTTTCAGAAATAAAATTCGATATTTATTAA |
| Protein Sequence | MDLRTEEPITAAQAWSGAYIWEVPNPLYFKILSHEVCPYSSKMDIITIRIQFNYNLRRALGVHKCFLTFRVWTTLHPPTGLFLRVFKTQVIKYLNNIGVISINSIIRAVDHVLYSKIEQTMYVDQVSEIKFDIY |
| NCBI Accession | YP_005086956.1 |
|---|---|
| Location | 1161-1613 |
| Gene Name | ac2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCGATCTTCGTCACCCTTGAAGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAAACGCAACAGGAGGAGGAGAGTAGATCTTGAATGCGGGTGTTCTTATTATCTGTCTATAAACTGTTTCAACCATGGATTTACGCACAGAGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATATCTGGGAAGTACCAAATCCCCTTTATTTCAAGATCCTAAGCCACGAGGTCTGTCCTTACTCGAGCAAGATGGACATAATAACAATCAGGATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTGCACAAGTGTTTTCTGACCTTCCGGGTTTGGACGACCTTACACCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACCCAAGTCATAAAGTATCTCAACAATATAGGAGTAATCTCAATTAA |
| Protein Sequence | MRSSSPLKDHCTQVPIKVQHREAKKRNRRRRVDLECGCSYYLSINCFNHGFTHRGTHHCSSSMEWRLYLGSTKSPLFQDPKPRGLSLLEQDGHNNNQDPIQLQPSESSGSAQVFSDLPGLDDLTPSDWSFLKGIQDPSHKVSQQYRSNLN |
| NCBI Accession | YP_005086957.1 |
|---|---|
| Location | 1510-2601 |
| Gene Name | ac1 |
| Protein Name | replication associated protein |
| Coding Region | ATGGCTCCTCCCAAACAATTCCAGATAAATGCCAAAAATTATTTCATCACTTATCCCACATGCTCTCTTACTAAAGAGGAGGCACTTTCCCAATTACAAAACCTACAAACCCCAGTAAACAAAAAATACATTAGAATCTGCAGAGAGTTTCATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGCAAATACAAGTGCAAAAATAACAGATTCTTCGACCTCGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCCAAGGACGGGGACATTCTCGACTGGGGAGAATTTCAGATCGATGGAAGATCAGCAAGAGGAGGGCAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCGGAGGCTCTTAGAGTCATTAAGGAACTAGCTCCTAAAGATTTTGTACTACAATTTCATAATTTAAATGCAAATCTAGACAGGATCTTTCAGGAGCCACCAGCTCCTTATGTTTCTCCTTTTTCGTCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGCGTGTGTAAATGTTGTCGACGCCGCTGCGCGGCCCCTGAGACCTCAAAGTATAGTAATTGAGGGCGACAGTCGTACTGGGAAAACAATGTGGGCTAGGTCTTTAGGCCCACATAACTATTTATGTGGGCATTTAGATCTAAGCCCAAAGGTGTACAGTAATGACGCTTGGTATAACGTCATTGATGACGTTGATCCGCACTTCCTCAAACACTTTAAAGAGTTCATGGGGGCCCAAAGGGACTGGCAATCCAACACAAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGAATACCAACAATCTTCCTCTGCAATCCTGGTCCTAACAGCAGTTATAAAGAATTCCTGGACGAGGAAAAGAACACTGCACTAAAGAACTGGACAGACAAGAATGCGATCTTCGTCACCCTTGAAGGACCACTGTACTCAGGTTCCAATCAAAGTACAGCACAGGGAAGCGAAGAAACGCAACAGGAGGAGGAGAGTAGATCTTGA |
| Protein Sequence | MAPPKQFQINAKNYFITYPTCSLTKEEALSQLQNLQTPVNKKYIRICREFHENGEPHLHVLIQFEGKYKCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIAKDGDILDWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIKELAPKDFVLQFHNLNANLDRIFQEPPAPYVSPFSSSSFDQVPEELEEWACVNVVDAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNTALKNWTDKNAIFVTLEGPLYSGSNQSTAQGSEETQQEEESRS |
| NCBI Accession | YP_005086958.1 |
|---|---|
| Location | 2142-2450 |
| Gene Name | ac4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAAGGCAAATACAAGTGCAAAAATAACAGATTCTTCGACCTCGTATCCCCAACCAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCCAAGGACGGGGACATTCTCGACTGGGGAGAATTTCAGATCGATGGAAGATCAGCAAGAGGAGGGCAACAGACAGCCAACGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCGGAGGCTCTTAGAGTCATTAAGGAACTAG |
| Protein Sequence | MKMGNLIFTCSSSSKANTSAKITDSSTSYPQPGQHISIRTFRELNPAPTSSPTSPRTGTFSTGENFRSMEDQQEEGNRQPTTLTPQHLTREVSRRLLESLRN |
References More References in PubMed
| 1 |
Khan A, et al. Arch Virol. 2021 Sep;166(9):2607-2610. doi: 10.1007/s00705-021-05134-7. Epub 2021 Jun 11. PMID: 34115211 |
|---|---|
| 2 |
Singh AK, et al. Plant Dis. 2021 Sep;105(9):2595-2600. doi: 10.1094/PDIS-12-20-2655-RE. Epub 2021 Oct 28. PMID: 33393356 |
| 3 |
Srivastava A, et al. Arch Virol. 2014 Oct;159(10):2711-5. doi: 10.1007/s00705-014-2108-1. Epub 2014 May 9. PMID: 24810100 |
| 4 |
Meena PN, et al. J Virol Methods. 2019 Jan;263:81-87. doi: 10.1016/j.jviromet.2018.10.016. Epub 2018 Oct 22. PMID: 30359678 |
| 5 |
Ullah I, et al. Viruses. 2021 Oct 26;13(11):2152. doi: 10.3390/v13112152. PMID: 34834959 |
| 6 |
Kumar M, et al. Arch Virol. 2020 Sep;165(9):2099-2103. doi: 10.1007/s00705-020-04696-2. Epub 2020 Jun 18. PMID: 32556597 |
| 7 |
Gupta K, et al. J Virol Methods. 2022 Feb;300:114413. doi: 10.1016/j.jviromet.2021.114413. Epub 2021 Dec 10. PMID: 34902462 |
| 8 |
Ganesh KV, et al. J Virol Methods. 2022 Mar;301:114457. doi: 10.1016/j.jviromet.2022.114457. Epub 2022 Jan 6. PMID: 34998828 |
| 9 |
Jeyaseelan TC, et al. Mol Biol Rep. 2021 Feb;48(2):1383-1391. doi: 10.1007/s11033-021-06213-3. Epub 2021 Feb 18. PMID: 33599950 |
| 10 |
A novel weevil-transmitted tymovirus found in mixed infection on hollyhock. Mahillon M, et al. Virol J. 2023 Jan 30;20(1):17. doi: 10.1186/s12985-023-01976-6. PMID: 36710353 |