Hollyhock leaf curl virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_002986605.1 |
| Isolate | Pakistan:Faisalabad |
| Release date | 2018/8/26 |
| Submitter | Zia Ur Rehman,M., Haider,M.S., Zia ur Rehman,M. |
| Host | |
| Download | Genome |GFF3 |PEP |CDS |
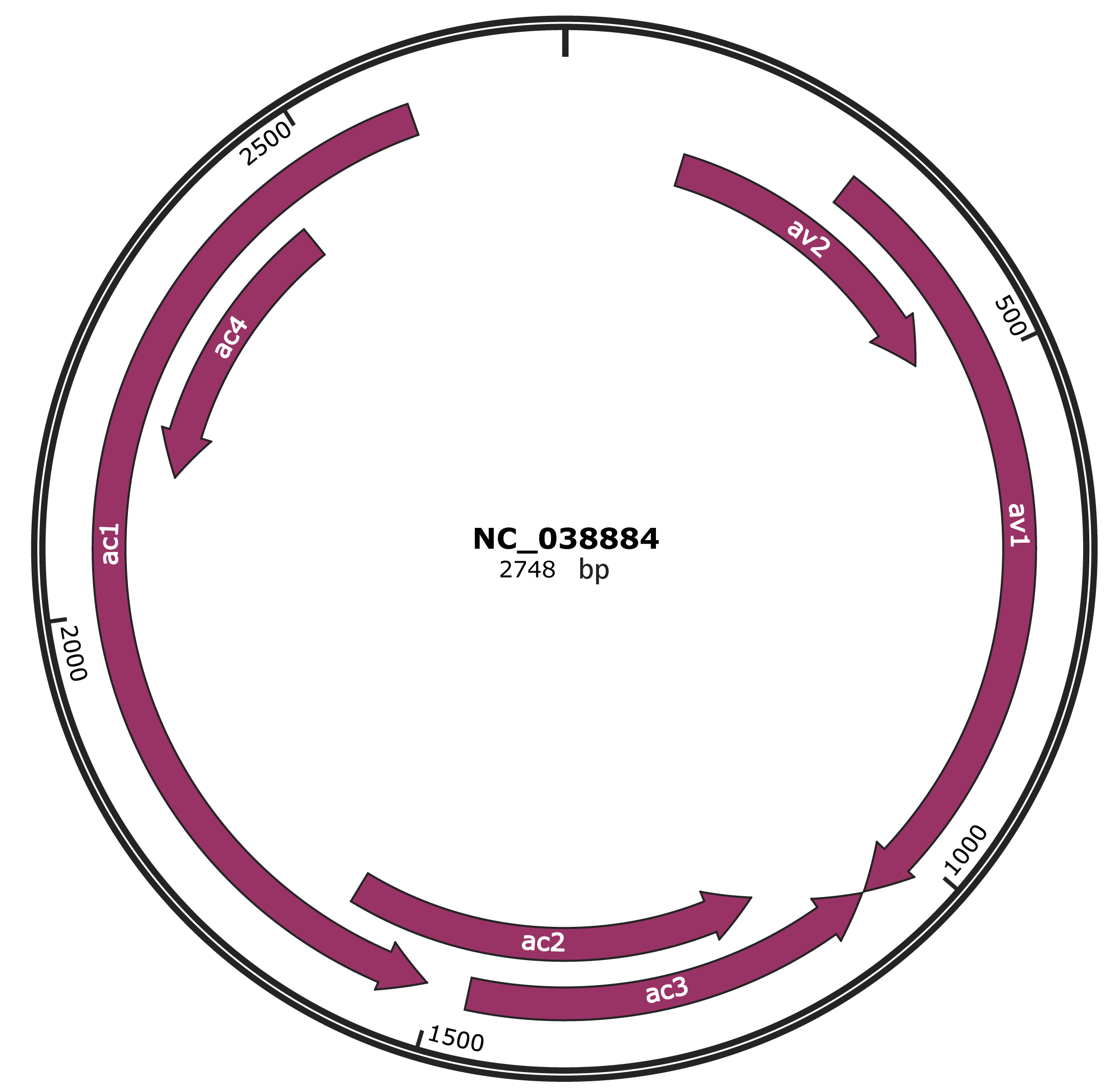
Genomic Organization
JBrowse
Genome
NC_038884
Gene Information
| NCBI Accession | YP_009508128.1 |
|---|---|
| Location | 130-477 |
| Gene Name | av2 |
| Protein Name | pre-coat protein |
| Coding Region | ATGTGGGATCCACTTTTAAACGAGTTCCCCGAGACGGTTCACGGGTTTCGTTGCATGCTTGCGATAAAATACCTGCAACTGCTGTCTGAGGAATACTCTCCGGATACGGTAGGTTACGATTTAATTCGCGATTTAATTTCTATTTTACGATCTAGGAATTATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGTCCCCACTGTCCGCGTCACAAAATCACGCATGTGGGCGAACAGGCCCATGAACCGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPETVHGFRCMLAIKYLQLLSEEYSPDTVGYDLIRDLISILRSRNYVEASCRYRHFYPRVEGASASELRQPLCNPCSCPHCPRHKITHVGEQAHEPEAQNVQNVQKP |
| NCBI Accession | YP_009508129.1 |
|---|---|
| Location | 290-1060 |
| Gene Name | av1 |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGTCCTGCCGATATCGTCATTTCTACCCCCGCGTCGAAGGTGCGTCGGCGTCTGAACTTCGACAGCCCCTATGCAACCCGTGCAGTTGTCCCCACTGTCCGCGTCACAAAATCACGCATGTGGGCGAACAGGCCCATGAACCGGAAGCCCAGAATGTACAGAATGTACAGAAGCCCTGATGTTCCAAGAGGCTGTGAGGGTCCATGTAAGGTCCAATCCTTTGAGTCCAGACACGATGTAGTCCATATAGGTAAGGTCATGTGTATTAGTGATGTTACTCGCGGTACTGGGCTGACCCATAGAGTTGGGAAACGTTTCTGTGTTAAATCAGTCTATGTATTGGGTAAGATCTGGATGGATGAAAACATAAAGTCCAAAAACCACACTAACAATGTGATGTTCTTCTTGGTCCGTGATCGACGGCCTGTGGATAAGCCTCAGGATTTTGGAGAGGTCTTCAACATGTTCGACAACGAGCCCAGCACCGCTACTGTCAAGAATGTTCATCGAGATCGCTACCAGGTGTTGAGGAAATGGTATGCAACAGTTACGGGTGGTCAATATGGAGCAAAGGAACAGGCCTTGGTCAAGAAGTTTGTCCGAGTTAACAATTATGTTGTTTACAATCAGCAAGAGGCAGGGAAATATGAGAATCATTCTGAGAATGCCCTGATGTTGTATATGGCATGTACCCATGCCTCTAATCCAGTTTACGCTACTCTTAAGATTAGGATTTACTTCTACGATTCTGTAACCAACTGA |
| Protein Sequence | MSKRPADIVISTPASKVRRRLNFDSPYATRAVVPTVRVTKSRMWANRPMNRKPRMYRMYRSPDVPRGCEGPCKVQSFESRHDVVHIGKVMCISDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKSKNHTNNVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWYATVTGGQYGAKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | YP_009508130.1 |
|---|---|
| Location | 1063-1467 |
| Gene Name | ac3 |
| Protein Name | replication enhancer protein |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATACCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACAACCGGCCATTCACAATGACAACGGACATAATAAAGATCAGAATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTCACAAGTGGTTTTCTGACCTACCGAATCTGGACGACCTTACGCCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACACAAATCCTCAAGTATCTCAACAATCTGGGTGTAATCTCAATTAATTCAATTATCAGAGCTGTAAACCATGTATTATGGGAAAAAATAGAACAAACTGTGTACGTAGACATGAATTCAGAAATAAAATTCGATATTTATTAA |
| Protein Sequence | MDSRTGEPITAAQAWSGAYTWEVPNPLYFKILSHDNRPFTMTTDIIKIRIQFNYNLRRALGVTSGFLTYRIWTTLRPPTGLFLRVFKTQILKYLNNLGVISINSIIRAVNHVLWEKIEQTVYVDMNSEIKFDIY |
| NCBI Accession | YP_009508131.1 |
|---|---|
| Location | 1160-1612 |
| Gene Name | ac2 |
| Protein Name | transcriptional activator protein |
| Coding Region | ATGCGATTTTCGTCACCCTCGAAGGACCACTGTACTCCGGTTCCAATCAAAGTACAGCACAGGGAAGCCAAGAGGGTACACAGGAGGAGGAGAGTCGATCTTGAATGCGGGTGTTCTTATTTTCTATCTATAAACTGCTTCAACCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGCATGGAGTGGCGCCTATACCTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCCTCAGCCACGACAACCGGCCATTCACAATGACAACGGACATAATAAAGATCAGAATCCAATTCAACTACAACCTTCGGAGAGCTCTGGGAGTCACAAGTGGTTTTCTGACCTACCGAATCTGGACGACCTTACGCCCTCCGACTGGTCTTTTCTTAAGGGTATTCAAGACACAAATCCTCAAGTATCTCAACAATCTGGGTGTAATCTCAATTAA |
| Protein Sequence | MRFSSPSKDHCTPVPIKVQHREAKRVHRRRRVDLECGCSYFLSINCFNHGFTHRGTHHCSSSMEWRLYLGGSKSPLFQDPQPRQPAIHNDNGHNKDQNPIQLQPSESSGSHKWFSDLPNLDDLTPSDWSFLKGIQDTNPQVSQQSGCNLN |
| NCBI Accession | YP_009508132.1 |
|---|---|
| Location | 1509-2600 |
| Gene Name | ac1 |
| Protein Name | replication associated protein |
| Coding Region | ATGGCTCCTCCCAAACAATTTCAGATATATGCCAAAAATTATTTCCTCACTTATCCCACTTGCTCTCTTACTAAAGAGGAAGCACTTTCCCAATTACAAAACCTACAGACACCAGTAAACAAAAAATACATTAGAATCTGCAGAGAGTTTCATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAGGGCAAATACAAATGCAAAAATAACAGATTCTTCGACCTCGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCTAAGGACGGGGACATTCTCGACTGGGGCGAATTTCAGATCGACGGAAGATCAGCAAGAGGAGGGCAACAAACAGCCAACGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAACTAGCTCCTAAAGATTTTGTACTACAATTTCATAATTTAAATGCAAATCTAGACAGGATCTTTCAGGAGCCTCCAGCTCCTTATGTTTCTCCTTTTTCCTATTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGTGTCTGAGAATGTTGTCGACGCCGCTGCGCGGCCCCTGAGACCTCAAAGTATAGTAATTGAGGGAGATAGTCGTACTGGGAAAACAATGTGGGCTAGGTCTCTAGGCCCACATAACTATTTATGTGGGCATTTGGATCTAAGCCCAAAAGTCTATAGTAACGACGCGTGGTACAACGTCATTGATGACGTCGACCCGCACTTCCTCAAGCACTTTAAGGAGTTTATGGGGGCCCAAAGGGACTGGCAGTCCAACACTAAGTACGGGAAGCCAGTTCAAATTAAAGGCGGCATACCGACAATCTTCTTATGCAATCCTGGTCCTAACAGCAGCTATAAAGAATTCCTCGACGAGGACAAGAACACAGCATTAAAGAATTGGGCTCTCAAAAATGCGATTTTCGTCACCCTCGAAGGACCACTGTACTCCGGTTCCAATCAAAGTACAGCACAGGGAAGCCAAGAGGGTACACAGGAGGAGGAGAGTCGATCTTGA |
| Protein Sequence | MAPPKQFQIYAKNYFLTYPTCSLTKEEALSQLQNLQTPVNKKYIRICREFHENGEPHLHVLIQFEGKYKCKNNRFFDLVSPTRSAHFHPNIQGAKSSSDVKSYIAKDGDILDWGEFQIDGRSARGGQQTANDAYAAALNAGSKSEALRVIKELAPKDFVLQFHNLNANLDRIFQEPPAPYVSPFSYSSFDQVPEELEEWVSENVVDAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHFLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEDKNTALKNWALKNAIFVTLEGPLYSGSNQSTAQGSQEGTQEEESRS |
| NCBI Accession | YP_009508133.1 |
|---|---|
| Location | 2141-2449 |
| Gene Name | ac4 |
| Protein Name | AC4 protein |
| Coding Region | ATGAAAATGGGGAACCTCATCTTCACGTGCTCATCCAGTTCGAGGGCAAATACAAATGCAAAAATAACAGATTCTTCGACCTCGTATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCCAGCTCCGACGTCAAGTCCTACATCGCTAAGGACGGGGACATTCTCGACTGGGGCGAATTTCAGATCGACGGAAGATCAGCAAGAGGAGGGCAACAAACAGCCAACGACGCTTACGCCGCAGCACTTAACGCGGGAAGTAAGTCAGAGGCTCTTAGAGTCATTAAGGAACTAG |
| Protein Sequence | MKMGNLIFTCSSSSRANTNAKITDSSTSYPQPGQHISIQTFRELNPAPTSSPTSLRTGTFSTGANFRSTEDQQEEGNKQPTTLTPQHLTREVSQRLLESLRN |
References More References in PubMed
| 1 |
Azeem H, et al. Mol Biol Rep. 2022 Jun;49(6):5635-5644. doi: 10.1007/s11033-022-07557-0. Epub 2022 May 22. PMID: 35598198 |
|---|---|
| 2 |
Cotton leaf curl virus disease. Briddon RW, et al. Virus Res. 2000 Nov;71(1-2):151-9. doi: 10.1016/s0168-1702(00)00195-7. PMID: 11137169 |
| 3 |
Zaidi SS, et al. Mol Plant Pathol. 2017 Sep;18(7):901-911. doi: 10.1111/mpp.12481. Epub 2016 Oct 17. PMID: 27553982 |
| 4 |
Kumar M, et al. Arch Virol. 2020 Sep;165(9):2099-2103. doi: 10.1007/s00705-020-04696-2. Epub 2020 Jun 18. PMID: 32556597 |
| 5 |
Using Multiplexed CRISPR/Cas9 for Suppression of Cotton Leaf Curl Virus. Binyameen B, et al. Int J Mol Sci. 2021 Nov 21;22(22):12543. doi: 10.3390/ijms222212543. PMID: 34830426 |
| 6 |
Widespread Occurrence of Cotton leaf curl virus on Radish in Pakistan. Mansoor S, et al. Plant Dis. 2000 Jul;84(7):809. doi: 10.1094/PDIS.2000.84.7.809B. PMID: 30832124 |
| 7 |
Mahmood MA, et al. Sci Rep. 2024 Jun 12;14(1):13532. doi: 10.1038/s41598-024-63211-8. PMID: 38866855 |
| 8 |
Khan A, et al. Arch Virol. 2021 Sep;166(9):2607-2610. doi: 10.1007/s00705-021-05134-7. Epub 2021 Jun 11. PMID: 34115211 |
| 9 |
Biswas KK, et al. PLoS One. 2020 Apr 22;15(4):e0231886. doi: 10.1371/journal.pone.0231886. eCollection 2020. PMID: 32320461 |
| 10 |
Exogenous Application of dsRNA for Protection against Tomato Leaf Curl New Delhi Virus. Frascati F, et al. Viruses. 2024 Mar 12;16(3):436. doi: 10.3390/v16030436. PMID: 38543801 |