Hemidesmus yellow mosaic virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_000911895.1 |
| Isolate |
India: Tirupati |
| Release date |
2015/2/22 |
| Submitter |
Reddy,M.S., Kanakala,S., Srinivas,K.P., Hema,M., Malathi,V.G., Sreenivasulu,P., Sreekanth Reddy,M. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
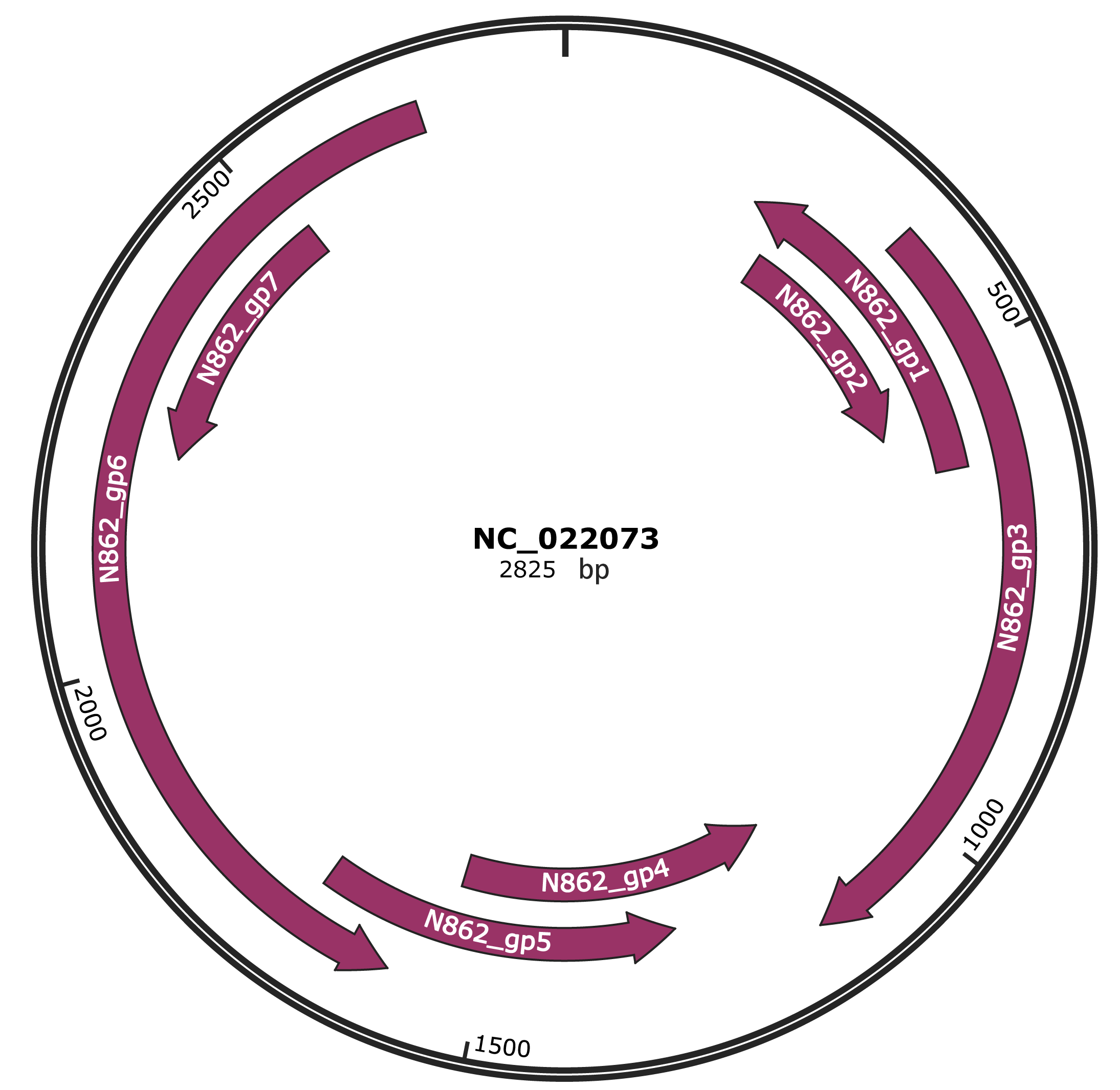
JBrowse
Genome
ACCGGGTGTCCGCGAAAATCGGAGGGCAAAAAAGAGCCCCCGCTCCTCCCGTGATTTACGGCTTTTGCTTTTGCTTTTGTCAAATCTTGTCGGCCACTTGTCTGCCACTACTTTTGACTGGCCAATCAGAAGAGGCCCTCAAAGCTTAGTTGCCAGCTGTATTCCACTATATATGGCTTTTGACCAGTCAAAGACGCGTAAAATGTGGGATCAGATGATCCATTACTTAATGATTTCCCCGAGACTGTGCACGGCTTTCGGTGCATGCTAGCTGTAAAATATCTTCTTTTGATACAGGAAACATACGCGCCTGATACTGTTGGGCGGGAATTAATTCGAGATTTGATTTGTGTTCTACGCGCCAAGAACTATGTCGAAGCGAGTAGCCGATATCGGAGTTTTCACTCCCGCCTCGAAAGTACGTCGGAGGCTGAACTTCGACAGCCCGTACAAGAGCCGTGCTGCTGTCCCCATTGTCCCCGTCACAAGGCGAAGGAGGTCGTGGGTATATCGACCAAGTTACCGGAAGCCATGGATGTACAGGATGTTCAGAAGTCCTGATGTGCCTAGGGGATGTGAGGGTCCTTGTAAGGTTCAATCTTTTGAACAGAGGCATGACATAGCACACACTGGGAAGGTGATATGTATATCAGATGTCACTAGAGGGGGTGGTATCACACATAGAGTAGGGAAGAGGTTTTGTGTTAAGTCTGTTTACATTATAGGTAAAATATGGATGGATAAAAATATTAAGGTTAAGAATCATACTAATAGTGTTATGTTTTGGTTAGTTAGGGATAGGAGACCATTTGGTAGTCCTATGGATTTTGGTCAGGTGTTCAACATGTATGATAATGAACCCAGTACTGCAACCGTGAAGAATGATCTCCGTGATAGATACCAGGTGTTGCATAGATTCTCAGCAACTGTGACTGGTGGCCAATATGCAAGCAAGGAGCAAGCTTTGGTGAAGAAATTTTGGAAGATTAACAATTATGTTGTTTACAATCATCAAGAAGCTGCTAAGTATGAAAATCATACAGAAAATGCTTTGTTATTGTATATGGCATGTACTCATGCTTCAAATCCAGTGTATGCTACTTTGAAGATACGGATCTATTTCTATGATTCGATATCAAATTAATAAAGATTGAATTTTATTGAAGTTGAAAGCTGTACATCTATTGTATTCTGAAATACTTCGTACAATACATAATCAGCTGCCCTAATTACACTATTAATTGAAATTACACCAAGATTATCTAAATACTGAAGAACTTGAAATCTAAACACTCTTAAGAAATGCCAAGTCTGAGGACGTAAACGAGTCCAGACTTGGAAGACTAAGAAACATTTGTGAATCCCCAGAGCCTTCCGGAGGTTGTGGTTGAACTGGATCTGGATGGTGATGATGTCGTGGTTGGTGAAACAAGGCCTGCTGTGGTGCTCGGTGATCTTGAAATAGAGGGGATTTTGAATCTCCCAGATAAAAACGCCACTCCTGGCTTGAATTGCAGTGATGTCTTCCCCGGTGCGTAAATCCATAGTTCTGGCAGTGGATGCTGATGAAGTAACTGCAGCCGCAGTCAAGATCAATTCTCTTCCTGCGGAAGATCTTCTTCTTGGCCTGGCTGTGTTGGACTTTGATTGGTACCGGAGAAGAGTGGCTGGAAGAGGGTGATGAACCTGGCATTCTTGATAGCCCAGGCCTTGAGGGATTTGTTTTTCTCCTCGTCGAGGAATTCGGTATAAGAAGAAGTTGGCCCTGGATTGCAGAGGAAGATTGTCGGAATTCCTCCTCTGACCTGAATGGGTTTTCCGTATTTGGTGTTGCTTTGCCAATCCCTCTGGGCCCCCATAAACTCCTTGAAGTGCTTTAAATAGTGGGGGTCTACGTCATCAATGACGTTGTACCAGGCATCATTACTAAAAACCCTAGGGCTTAAATCCAGGTGTCCACACAAATAATTATGTGGGCCTAATGATCTGGCCCACAATGTCTTGCCTGTTCTAGAATCTCCTTCTACTACTATGCTAATCGGTCTCTCAGGCCGCGCAGTGGCAGGCAACACATTCTCAGAGACCCACTCCTCTAACTCATCTGGAACTTGATCAAAAGAAGAAGAAAGAAAGGGGGACTTATAAGGGGGAATTGCAGAAGTAAAAATCCTATCAAAATTAGAGTGCAGATTATGATACTGCAGTACATAATCTTTGGGCATTAATTCTTTAATAATATTAAGAGCCTCCTGCTTACTTCCTGCGTTATTGCTGAGACGTATGCATCGTTTGCAGATTTCTGGCCTCCTCTTGCAGATCTCATCGTCGACCTGAAACTCACCCCAGTCGAGGGTGTCTCCGTCCTTTCCGATATATGCCTTGACGTCGGAGGAGGACTTAGCGCGTTGAATGTTTGGGTGGAAACTGGCGCTACAGCTTGGGTGAGACAGATCGAAGAAACGATCGGAGGTGCAGTTGTATTTTCCCTCGAACTGCAACAGCACATGGAGATGAGGTTCCCCATTCTCGTGTAGTTCTCTGCAAACCTTAATGTACTTCAGATTGGTTGGGTATTGAAGGTTACGGAGTTGTTCTATGGTTTCCTCTTTGGTCAGAGAGCATCTGGGATAGGTGAGGAAGTAGTTCTTGGCATTAATGGAGAATCGCCCAGATCTAGGCATTTTTAGAGAGAAGGAGGAGAGAAATTTCTAGAGAGAGAAAGCTGGGATCAATTGGAGGGCAGCCAAAACTACATGTAATCGGTGGAACGGAGGGCAATATATAGACATCTCTACATCTCTACTAGCGGACACCCTAATAATATT
Gene Information
|
NCBI Accession
|
YP_008411020.1
|
|
Location
|
227-616 |
|
Protein Name
|
AC5 |
|
Coding Region
|
ATGCCTCTGTTCAAAAGATTGAACCTTACAAGGACCCTCACATCCCCTAGGCACATCAGGACTTCTGAACATCCTGTACATCCATGGCTTCCGGTAACTTGGTCGATATACCCACGACCTCCTTCGCCTTGTGACGGGGACAATGGGGACAGCAGCACGGCTCTTGTACGGGCTGTCGAAGTTCAGCCTCCGACGTACTTTCGAGGCGGGAGTGAAAACTCCGATATCGGCTACTCGCTTCGACATAGTTCTTGGCGCGTAGAACACAAATCAAATCTCGAATTAATTCCCGCCCAACAGTATCAGGCGCGTATGTTTCCTGTATCAAAAGAAGATATTTTACAGCTAGCATGCACCGAAAGCCGTGCACAGTCTCGGGGAAATCATTAA |
|
Protein Sequence
|
MPLFKRLNLTRTLTSPRHIRTSEHPVHPWLPVTWSIYPRPPSPCDGDNGDSSTALVRAVEVQPPTYFRGGSENSDIGYSLRHSSWRVEHKSNLELIPAQQYQARMFPVSKEDILQLACTESRAQSRGNH |
|
NCBI Accession
|
YP_008411021.1
|
|
Location
|
265-561 |
|
Protein Name
|
AV2 |
|
Coding Region
|
ATGCTAGCTGTAAAATATCTTCTTTTGATACAGGAAACATACGCGCCTGATACTGTTGGGCGGGAATTAATTCGAGATTTGATTTGTGTTCTACGCGCCAAGAACTATGTCGAAGCGAGTAGCCGATATCGGAGTTTTCACTCCCGCCTCGAAAGTACGTCGGAGGCTGAACTTCGACAGCCCGTACAAGAGCCGTGCTGCTGTCCCCATTGTCCCCGTCACAAGGCGAAGGAGGTCGTGGGTATATCGACCAAGTTACCGGAAGCCATGGATGTACAGGATGTTCAGAAGTCCTGA |
|
Protein Sequence
|
MLAVKYLLLIQETYAPDTVGRELIRDLICVLRAKNYVEASSRYRSFHSRLESTSEAELRQPVQEPCCCPHCPRHKAKEVVGISTKLPEAMDVQDVQKS |
|
NCBI Accession
|
YP_008411022.1
|
|
Location
|
371-1144 |
|
Protein Name
|
AV1 |
|
Coding Region
|
ATGTCGAAGCGAGTAGCCGATATCGGAGTTTTCACTCCCGCCTCGAAAGTACGTCGGAGGCTGAACTTCGACAGCCCGTACAAGAGCCGTGCTGCTGTCCCCATTGTCCCCGTCACAAGGCGAAGGAGGTCGTGGGTATATCGACCAAGTTACCGGAAGCCATGGATGTACAGGATGTTCAGAAGTCCTGATGTGCCTAGGGGATGTGAGGGTCCTTGTAAGGTTCAATCTTTTGAACAGAGGCATGACATAGCACACACTGGGAAGGTGATATGTATATCAGATGTCACTAGAGGGGGTGGTATCACACATAGAGTAGGGAAGAGGTTTTGTGTTAAGTCTGTTTACATTATAGGTAAAATATGGATGGATAAAAATATTAAGGTTAAGAATCATACTAATAGTGTTATGTTTTGGTTAGTTAGGGATAGGAGACCATTTGGTAGTCCTATGGATTTTGGTCAGGTGTTCAACATGTATGATAATGAACCCAGTACTGCAACCGTGAAGAATGATCTCCGTGATAGATACCAGGTGTTGCATAGATTCTCAGCAACTGTGACTGGTGGCCAATATGCAAGCAAGGAGCAAGCTTTGGTGAAGAAATTTTGGAAGATTAACAATTATGTTGTTTACAATCATCAAGAAGCTGCTAAGTATGAAAATCATACAGAAAATGCTTTGTTATTGTATATGGCATGTACTCATGCTTCAAATCCAGTGTATGCTACTTTGAAGATACGGATCTATTTCTATGATTCGATATCAAATTAA |
|
Protein Sequence
|
MSKRVADIGVFTPASKVRRRLNFDSPYKSRAAVPIVPVTRRRRSWVYRPSYRKPWMYRMFRSPDVPRGCEGPCKVQSFEQRHDIAHTGKVICISDVTRGGGITHRVGKRFCVKSVYIIGKIWMDKNIKVKNHTNSVMFWLVRDRRPFGSPMDFGQVFNMYDNEPSTATVKNDLRDRYQVLHRFSATVTGGQYASKEQALVKKFWKINNYVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSISN |
|
NCBI Accession
|
YP_008411023.1
|
|
Location
|
1141-1545 |
|
Protein Name
|
AC3 |
|
Coding Region
|
ATGGATTTACGCACCGGGGAAGACATCACTGCAATTCAAGCCAGGAGTGGCGTTTTTATCTGGGAGATTCAAAATCCCCTCTATTTCAAGATCACCGAGCACCACAGCAGGCCTTGTTTCACCAACCACGACATCATCACCATCCAGATCCAGTTCAACCACAACCTCCGGAAGGCTCTGGGGATTCACAAATGTTTCTTAGTCTTCCAAGTCTGGACTCGTTTACGTCCTCAGACTTGGCATTTCTTAAGAGTGTTTAGATTTCAAGTTCTTCAGTATTTAGATAATCTTGGTGTAATTTCAATTAATAGTGTAATTAGGGCAGCTGATTATGTATTGTACGAAGTATTTCAGAATACAATAGATGTACAGCTTTCAACTTCAATAAAATTCAATCTTTATTAA |
|
Protein Sequence
|
MDLRTGEDITAIQARSGVFIWEIQNPLYFKITEHHSRPCFTNHDIITIQIQFNHNLRKALGIHKCFLVFQVWTRLRPQTWHFLRVFRFQVLQYLDNLGVISINSVIRAADYVLYEVFQNTIDVQLSTSIKFNLY |
|
NCBI Accession
|
YP_008411024.1
|
|
Location
|
1286-1693 |
|
Protein Name
|
AC2 |
|
Coding Region
|
ATGCCAGGTTCATCACCCTCTTCCAGCCACTCTTCTCCGGTACCAATCAAAGTCCAACACAGCCAGGCCAAGAAGAAGATCTTCCGCAGGAAGAGAATTGATCTTGACTGCGGCTGCAGTTACTTCATCAGCATCCACTGCCAGAACTATGGATTTACGCACCGGGGAAGACATCACTGCAATTCAAGCCAGGAGTGGCGTTTTTATCTGGGAGATTCAAAATCCCCTCTATTTCAAGATCACCGAGCACCACAGCAGGCCTTGTTTCACCAACCACGACATCATCACCATCCAGATCCAGTTCAACCACAACCTCCGGAAGGCTCTGGGGATTCACAAATGTTTCTTAGTCTTCCAAGTCTGGACTCGTTTACGTCCTCAGACTTGGCATTTCTTAAGAGTGTTTAG |
|
Protein Sequence
|
MPGSSPSSSHSSPVPIKVQHSQAKKKIFRRKRIDLDCGCSYFISIHCQNYGFTHRGRHHCNSSQEWRFYLGDSKSPLFQDHRAPQQALFHQPRHHHHPDPVQPQPPEGSGDSQMFLSLPSLDSFTSSDLAFLKSV |
|
NCBI Accession
|
YP_008411025.1
|
|
Location
|
1593-2681 |
|
Protein Name
|
AC1 |
|
Coding Region
|
ATGCCTAGATCTGGGCGATTCTCCATTAATGCCAAGAACTACTTCCTCACCTATCCCAGATGCTCTCTGACCAAAGAGGAAACCATAGAACAACTCCGTAACCTTCAATACCCAACCAATCTGAAGTACATTAAGGTTTGCAGAGAACTACACGAGAATGGGGAACCTCATCTCCATGTGCTGTTGCAGTTCGAGGGAAAATACAACTGCACCTCCGATCGTTTCTTCGATCTGTCTCACCCAAGCTGTAGCGCCAGTTTCCACCCAAACATTCAACGCGCTAAGTCCTCCTCCGACGTCAAGGCATATATCGGAAAGGACGGAGACACCCTCGACTGGGGTGAGTTTCAGGTCGACGATGAGATCTGCAAGAGGAGGCCAGAAATCTGCAAACGATGCATACGTCTCAGCAATAACGCAGGAAGTAAGCAGGAGGCTCTTAATATTATTAAAGAATTAATGCCCAAAGATTATGTACTGCAGTATCATAATCTGCACTCTAATTTTGATAGGATTTTTACTTCTGCAATTCCCCCTTATAAGTCCCCCTTTCTTTCTTCTTCTTTTGATCAAGTTCCAGATGAGTTAGAGGAGTGGGTCTCTGAGAATGTGTTGCCTGCCACTGCGCGGCCTGAGAGACCGATTAGCATAGTAGTAGAAGGAGATTCTAGAACAGGCAAGACATTGTGGGCCAGATCATTAGGCCCACATAATTATTTGTGTGGACACCTGGATTTAAGCCCTAGGGTTTTTAGTAATGATGCCTGGTACAACGTCATTGATGACGTAGACCCCCACTATTTAAAGCACTTCAAGGAGTTTATGGGGGCCCAGAGGGATTGGCAAAGCAACACCAAATACGGAAAACCCATTCAGGTCAGAGGAGGAATTCCGACAATCTTCCTCTGCAATCCAGGGCCAACTTCTTCTTATACCGAATTCCTCGACGAGGAGAAAAACAAATCCCTCAAGGCCTGGGCTATCAAGAATGCCAGGTTCATCACCCTCTTCCAGCCACTCTTCTCCGGTACCAATCAAAGTCCAACACAGCCAGGCCAAGAAGAAGATCTTCCGCAGGAAGAGAATTGA |
|
Protein Sequence
|
MPRSGRFSINAKNYFLTYPRCSLTKEETIEQLRNLQYPTNLKYIKVCRELHENGEPHLHVLLQFEGKYNCTSDRFFDLSHPSCSASFHPNIQRAKSSSDVKAYIGKDGDTLDWGEFQVDDEICKRRPEICKRCIRLSNNAGSKQEALNIIKELMPKDYVLQYHNLHSNFDRIFTSAIPPYKSPFLSSSFDQVPDELEEWVSENVLPATARPERPISIVVEGDSRTGKTLWARSLGPHNYLCGHLDLSPRVFSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQVRGGIPTIFLCNPGPTSSYTEFLDEEKNKSLKAWAIKNARFITLFQPLFSGTNQSPTQPGQEEDLPQEEN |
|
NCBI Accession
|
YP_008411026.1
|
|
Location
|
2222-2524 |
|
Protein Name
|
AC4 |
|
Coding Region
|
ATGGGGAACCTCATCTCCATGTGCTGTTGCAGTTCGAGGGAAAATACAACTGCACCTCCGATCGTTTCTTCGATCTGTCTCACCCAAGCTGTAGCGCCAGTTTCCACCCAAACATTCAACGCGCTAAGTCCTCCTCCGACGTCAAGGCATATATCGGAAAGGACGGAGACACCCTCGACTGGGGTGAGTTTCAGGTCGACGATGAGATCTGCAAGAGGAGGCCAGAAATCTGCAAACGATGCATACGTCTCAGCAATAACGCAGGAAGTAAGCAGGAGGCTCTTAATATTATTAAAGAATTAA |
|
Protein Sequence
|
MGNLISMCCCSSRENTTAPPIVSSICLTQAVAPVSTQTFNALSPPPTSRHISERTETPSTGVSFRSTMRSARGGQKSANDAYVSAITQEVSRRLLILLKN |