Euphorbia yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000882835.1 |
| Isolate | Brazil |
| Release date | 2015/2/22 |
| Submitter | Fernandes,F.R., Albuquerque,L.C., de Oliveira,C.L., Cruz,A.R., da Rocha,W.B., Pereira,T.G., Naito,F.Y., Dias Nde,M., Nagata,T., Faria,J.C., Zerbini,F.M., Aragao,F.J., Inoue-Nagata,A.K., Sousa,A.R.R.C., Aragao,F.J.L. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
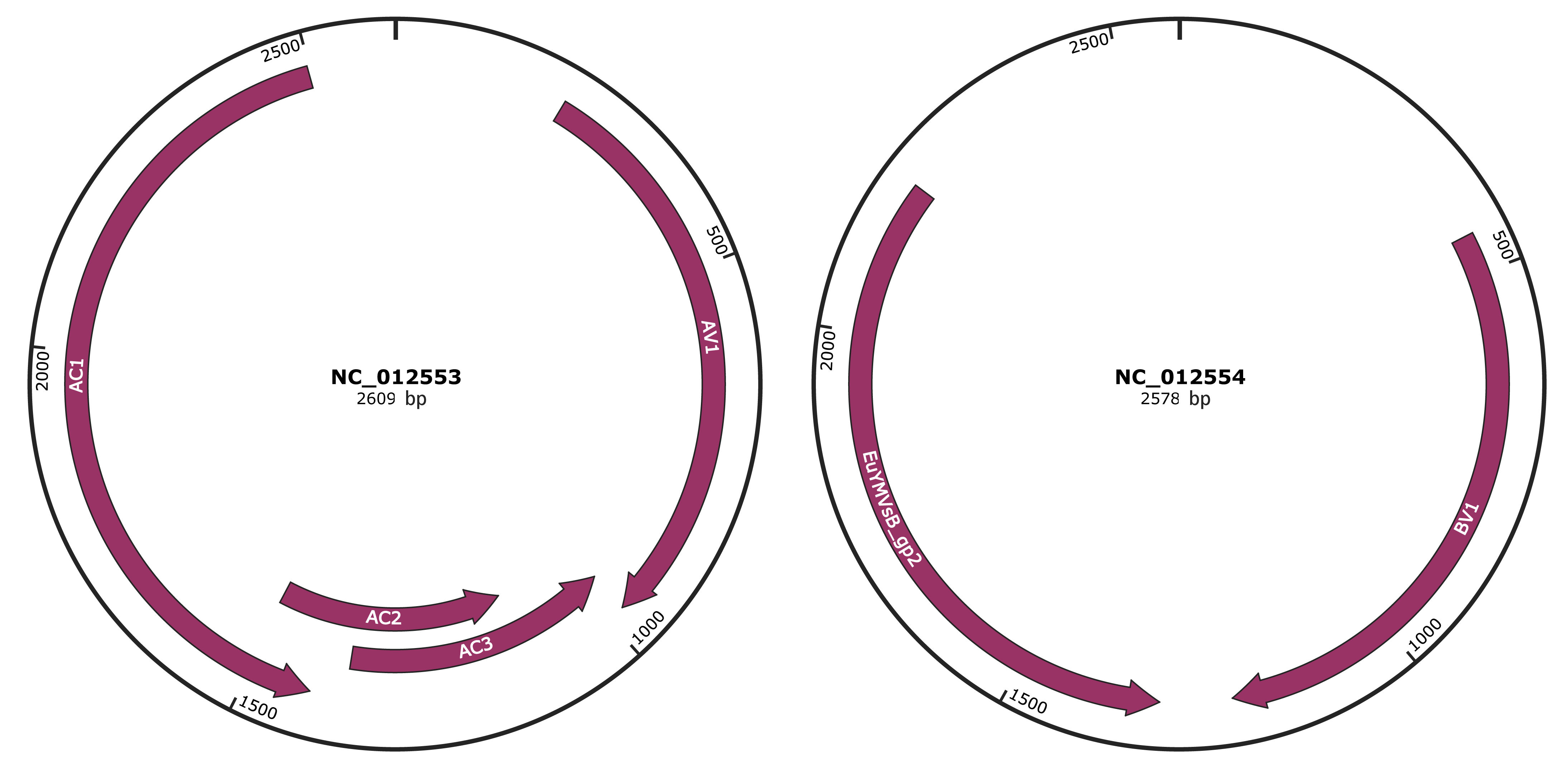
JBrowse
Genome
NC_012553
NC_012554
Gene Information
| NCBI Accession | YP_002791011.1 |
|---|---|
| Location | 226-975 |
| Gene Name | AV1 |
| Protein Name | CP |
| Coding Region | ATGCCTAAGCGAGATGCCCCATGGCGATTAATGGCGGGGACCTCCAAGGTCAGTCGTAATGTCAATTATTCGCCCCGTGGTGGTCCTAAAATAGACAAGGCCTCTTCATGGGTGAACAGGCCCATGTACAGGAAGCCCAGGATCTATCGCATGTATAGAGGCCCAGATGTTCCGAAGGGATGTGAAGGGCCTTGTAAGGTCCAGTCATACGAGTCTCGACATGACGTTTCCCATGTTGGGAAAGTGATATGTGTATCCGACGTGACACGGGGCAATGGTATTACGCATCGTGTGGGCAAGCGTTTCTGCGTCAAGTCTGTGTACATTCTAGGGAAGATCTGGATGGATGAGACCATCAAGTTGAAGAACCACACGAATAGCGTCATGTTCTGGTTGGTGCGAGATCGTCGACCATATAGCTCTCCTATGGATTTTGGCCAAGTGTTCAACATGTTCGACAACGAACCCAGTACAGCTACCGTGAAGAACGATCTCCGCGATCGCTTCCAAGTGATGCACAAGTTTTACGCGAAGGTCACTGGTGGACAATATGCGAGCAACGAGCAGGCGATCGTCAAACGTTTTTGGAAGGTCAACAACTATGTGGTGTATAACCACCAAGAGGCAGGGAAATACGAGAATCATACGGAGAACGCGTTACTATTATATATGGCATGTACTCATGCCTCTAATCCTGTATATGCGACGTTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
| Protein Sequence | MPKRDAPWRLMAGTSKVSRNVNYSPRGGPKIDKASSWVNRPMYRKPRIYRMYRGPDVPKGCEGPCKVQSYESRHDVSHVGKVICVSDVTRGNGITHRVGKRFCVKSVYILGKIWMDETIKLKNHTNSVMFWLVRDRRPYSSPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQAIVKRFWKVNNYVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
| NCBI Accession | YP_002791012.1 |
|---|---|
| Location | 972-1370 |
| Gene Name | AC3 |
| Protein Name | REn |
| Coding Region | ATGGATTTAAGCACCGGGGAATTCATCACTGTGTCTCAGGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATCGGGGTGGAGGACCCGATATACACGTCACTCCGGATATACCACATCCAGATCCGGTTCAATTACAACCTCAGGAGGGCACTGAATCTACGCAAAGCTTTCCTGAACTTCCAAGTCTGGACGACATCGATTCGAGCTTCTGGGATGACTTATTTAAGTAGATTCAGGCATTTAGTTTTAATGTATTTAGATCAATTGGGTGTCGTCGGTCTTAATCATGTAATTAGGGCTGTTCGTTTCGCAACTGATCGCTCATATGTAAATGATGTACTCGAGAATCATGAAATAAAATTCAATTTTTATTAA |
| Protein Sequence | MDLSTGEFITVSQAENSVFIWEVPNPLYFKIIGVEDPIYTSLRIYHIQIRFNYNLRRALNLRKAFLNFQVWTTSIRASGMTYLSRFRHLVLMYLDQLGVVGLNHVIRAVRFATDRSYVNDVLENHEIKFNFY |
| NCBI Accession | YP_002791013.1 |
|---|---|
| Location | 1117-1506 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGCTAAATTCATCTTCCTCCACGCCCCCCTCTATCAAAGCACAGCACCGAGTAGCCAAGAGGAGAGCTATACGTCGACGACGGATTGACTTGAACTGCGGCTGTTCCATATTTCTCCACATCGACTGTGCAGATTATGGATTTAAGCACCGGGGAATTCATCACTGTGTCTCAGGCAGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATCGGGGTGGAGGACCCGATATACACGTCACTCCGGATATACCACATCCAGATCCGGTTCAATTACAACCTCAGGAGGGCACTGAATCTACGCAAAGCTTTCCTGAACTTCCAAGTCTGGACGACATCGATTCGAGCTTCTGGGATGACTTATTTAAGTAG |
| Protein Sequence | MLNSSSSTPPSIKAQHRVAKRRAIRRRRIDLNCGCSIFLHIDCADYGFKHRGIHHCVSGREFRFYLGGSKSPLFQDHRGGGPDIHVTPDIPHPDPVQLQPQEGTESTQSFPELPSLDDIDSSFWDDLFK |
| NCBI Accession | YP_002791014.1 |
|---|---|
| Location | 1418-2497 |
| Gene Name | AC1 |
| Protein Name | Rep |
| Coding Region | ATGCCACGGAACCCTAATTCATTTCGCCTAACGGCCAAAAATATATTCCTCACTTATCCCCGGTGCGATATTCCGAAAGATGAAGTTCTGCAGTTGCTTCGGGACTTGCCATGGTCTGTCGTCAAGCCGACGTACATCCGAGTCGCTCGAGAGCTCCACGCCGATGGGTTCCCCCATCTCCACTGTCTTATTCAACTCTCCGGCAAGTCCAACATCAAGGACGCTAGGTTTTTCAACCTTACTCACCCCAGACGGTCTGCCGAATTTCACCCAAATGCGCAATCGGCCAAGGACGCCAACGCCGTCAAAAATTACATCACCAAAGAGGGTGATTATTGTGAATCCGGCCAATATAAGGTGTCTGGGGGTTCCAAGTCCAATAAAGATGACGTCTACCACAACGCTGTCAATGCAGCAACTGCAGGAGAGGCTCTCGACATAATAAGGGCTGGTGATCCGAGGACGTTCATCGTGAATTATCATAACGTCAAAGCTAACGTCGAGCGCCTCTTTCTGAAGCCACCCCTTCCTTGGGTTCCTCCATTTCAATTGTCGTCGTTTAACAATGTCCCGGACGATTTGCAAGAGTGGGCTGATGTTTATTTTGGAAGGGGTGCCGCTGCGCGGCCAGAGAGACCTATTAGTATTGTAGTCGAGGGGGATAGTCGAACGGGAAAGACCATGTGGGCTAGAGCTTTAGGCCCACATAATTATCTTAGTGGGCATCTCGATTTCAATTCTAGGGTTTACTCAAATGACGTTGAGTATAACGTCATTGATGATGTCGCTCCGCATTATCTAAAGTTAAAGCATTGGAAAGAGTTGATTGGGGCCCAAAGGGACTGGCAGTCCAACTGTAAATATGGAAAGCCGGTTCAAATTAAAGGCGGGATACCATCAATCGTGCTGTGCAATCCAGGCGAGGGGGCTAGTTATAAAGACTTCCTCAACAAAGAGGAGAATGCATCGTTGAGAGCTTGGACACGCAAGAATGCTAAATTCATCTTCCTCCACGCCCCCCTCTATCAAAGCACAGCACCGAGTAGCCAAGAGGAGAGCTATACGTCGACGACGGATTGA |
| Protein Sequence | MPRNPNSFRLTAKNIFLTYPRCDIPKDEVLQLLRDLPWSVVKPTYIRVARELHADGFPHLHCLIQLSGKSNIKDARFFNLTHPRRSAEFHPNAQSAKDANAVKNYITKEGDYCESGQYKVSGGSKSNKDDVYHNAVNAATAGEALDIIRAGDPRTFIVNYHNVKANVERLFLKPPLPWVPPFQLSSFNNVPDDLQEWADVYFGRGAAARPERPISIVVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNDVEYNVIDDVAPHYLKLKHWKELIGAQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENASLRAWTRKNAKFIFLHAPLYQSTAPSSQEESYTSTTD |
| NCBI Accession | YP_002791015.2 |
|---|---|
| Location | 450-1220 |
| Gene Name | BV1 |
| Protein Name | NS |
| Coding Region | ATGTATACGACTAAGTATAGACGTGGTGGGTCATCTTCTAAGCGACGAGGGTATTCACGATATCCAGCGTTTAAGCGAATGCAGAATGGAAAACGTTCCGAATGGAGACGTCGACCCAGCAGTCCTTGTAAGGCACATGACGATATTAAGTGGACGGCCCAATGTATACATGAAGATCAATTCGGCCCAGAATTTGTATTGGGCCATAATATAGCTACGTCGACCTATATTAGCTACCCTAGTATGAGTAAGACTGAACCGAACCGATCCCGATCGTATATTAAGTTGCGGCGTCTACGCTTTAAGGGCACTCTGAAGGTCGAGCGTGTACACGTCGATGTTAACATGATCGGTTCGAATGCAAAGATAGAAGGCGTATTCTCTATGGTCGTTATTGTCGACCGTAAACCTCACTTGGGTCCAACTGGATGCCTTCATACATTTGATGAGGTCTTTGGCGCCAGGATCCACAGTCATGGAAATCTAACCGTCAGTCCTTCTTTGAAGGATCGGTACTACATCCGCCACGTATTCAAGCGCGTCATATCTGTCGAGAAAGACACGATGATGGTGGATATAGAAGGGTCGACGTGTTTATCTACTAGGCGTTCTTCTTGCTGGGCTACTTTTAAGGATACGGAACGAGACTCATGTAATGGTGTATATGCGAATATAAGCAAGAACGCCATATTAGTGTATTATTGCTGGATGTCGGATCATATGTCCAAGGCATCTACATTTGTATCATTTGACCTCGATTATGTCGGATGA |
| Protein Sequence | MYTTKYRRGGSSSKRRGYSRYPAFKRMQNGKRSEWRRRPSSPCKAHDDIKWTAQCIHEDQFGPEFVLGHNIATSTYISYPSMSKTEPNRSRSYIKLRRLRFKGTLKVERVHVDVNMIGSNAKIEGVFSMVVIVDRKPHLGPTGCLHTFDEVFGARIHSHGNLTVSPSLKDRYYIRHVFKRVISVEKDTMMVDIEGSTCLSTRRSSCWATFKDTERDSCNGVYANISKNAILVYYCWMSDHMSKASTFVSFDLDYVG |
| NCBI Accession | YP_004935367.1 |
|---|---|
| Location | 1315-2199 |
| Protein Name | BC1 |
| Coding Region | ATGGAGGGGTCTCAGTTAGTAAATCCGCCGAGCGCTTTCAATTACATAGAGTCACATCGTGACGAGTATCAGCTATCGCATGACCTAACTGAGATAGTCTTGCAATTCCCCTCAACGGCGTCTCAATTAGGAGCCCGACTCTCACGCAGCTGCATGAAGATCGACCATTGCGTAATAGAATATAGGCAACAAGTGCCAATTAATGCGTCGGGCTCGGTAGTAGTGGAGATTCACGACAAGAGAATGACGGACAATGAGTCCTTACAGGCGTCATGGACATTCCCCATACGATGTAACATAGATCTCCACTACTTTTCATCTTCATTCTTCTCACTCAAAGACCCAATTCCTTGGAAACTATATTATAAGGTTTGCGACTCGAACGTCCATCAGAGGACGCATTTCGCGAAGTTCAAGGGTAAACTGAAGTTATCGACGGCAAAACATTCCGTTGATATCCCTTTCAGAGCGCCAACTGTCAAGATCCTGTCCAAACAGTTTACAGATAAGGATATCGACTTCAGTCATGTGGGCTACGGCAAATGGGAGAGAAGAATGATTAGATCCGCATCATCATCGAGACTTGGGCTACAAGGCCCAATTGAAATAAGGCCCGGTGAATCATGGGCCACAAGGTCTACTATAGGACTGGGCCATTTAGATGCGGATTCAGATGTGAGAGACGCCTCTTACCCATATCGGGAGTTAAATAGGCTAGGGACTCCCGTATTAGACCCGGGAGATTCAGCTTCCGTAGTAGCTGCTCAGAGAACACATTCGAACATATCGATGTCAATGGGTCAGCTGAACGAGATAGTTAGGTCAACCGTTCAGGAATGTATCAGCACTAATTGTATTCCTCCCAGAAATAAAACGCTTGATTAA |
| Protein Sequence | MEGSQLVNPPSAFNYIESHRDEYQLSHDLTEIVLQFPSTASQLGARLSRSCMKIDHCVIEYRQQVPINASGSVVVEIHDKRMTDNESLQASWTFPIRCNIDLHYFSSSFFSLKDPIPWKLYYKVCDSNVHQRTHFAKFKGKLKLSTAKHSVDIPFRAPTVKILSKQFTDKDIDFSHVGYGKWERRMIRSASSSRLGLQGPIEIRPGESWATRSTIGLGHLDADSDVRDASYPYRELNRLGTPVLDPGDSASVVAAQRTHSNISMSMGQLNEIVRSTVQECISTNCIPPRNKTLD |
References More References in PubMed
| 1 |
Detection of Poinsettia mosaic virus Infecting Poinsettias (Euphorbia pulcherrima) in Venezuela. Carballo O, et al. Plant Dis. 2001 Nov;85(11):1208. doi: 10.1094/PDIS.2001.85.11.1208D. PMID: 30823179 |
|---|---|
| 2 |
Mar TB, et al. J Gen Virol. 2017 Jun;98(6):1552-1562. doi: 10.1099/jgv.0.000814. Epub 2017 Jun 8. PMID: 28590236 |
| 3 |
Mar TB, et al. J Gen Virol. 2017 Jun;98(6):1537-1551. doi: 10.1099/jgv.0.000784. Epub 2017 Jun 13. PMID: 28612702 |
| 4 |
Fernandes FR, et al. Arch Virol. 2011 Nov;156(11):2063-9. doi: 10.1007/s00705-011-1070-4. Epub 2011 Jul 22. PMID: 21779908 |
| 5 |
Pramesh D, et al. Arch Virol. 2013 Mar;158(3):531-42. doi: 10.1007/s00705-012-1511-8. Epub 2012 Oct 25. PMID: 23096697 |
| 6 |
The recombination mediator RAD51D promotes geminiviral infection. Richter KS, et al. Virology. 2016 Jun;493:113-27. doi: 10.1016/j.virol.2016.03.014. Epub 2016 Mar 26. PMID: 27018825 |
| 7 |
Commodity risk assessment of Petunia spp. and Calibrachoa spp. unrooted cuttings from Costa Rica. EFSA Panel on Plant Health (PLH), et al. EFSA J. 2024 Nov 11;22(11):e9064. doi: 10.2903/j.efsa.2024.9064. eCollection 2024 Nov. PMID: 39529754 |
| 8 |
Lettuce mosaic virus: from pathogen diversity to host interactors. German-Retana S, et al. Mol Plant Pathol. 2008 Mar;9(2):127-36. doi: 10.1111/j.1364-3703.2007.00451.x. PMID: 18705846 |
| 9 |
The contribution of translesion synthesis polymerases on geminiviral replication. Richter KS, et al. Virology. 2016 Jan 15;488:137-48. doi: 10.1016/j.virol.2015.10.027. Epub 2015 Nov 27. PMID: 26638018 |
| 10 |
A study of weeds as potential inoculum sources for a tomato-infecting begomovirus in central Brazil. Barreto SS, et al. Phytopathology. 2013 May;103(5):436-44. doi: 10.1094/PHYTO-07-12-0174-R. PMID: 23489523 |