Euphorbia mosaic Peru virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_003034025.1 |
| Isolate |
Peru:Santa Maria, Machu Pichu |
| Release date |
2018/8/26 |
| Submitter |
Shepherd,D.N., Martin,D.P., Lefeuvre,P., Monjane,A.L., Owor,B.E., Rybicki,E.P., Varsani,A. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
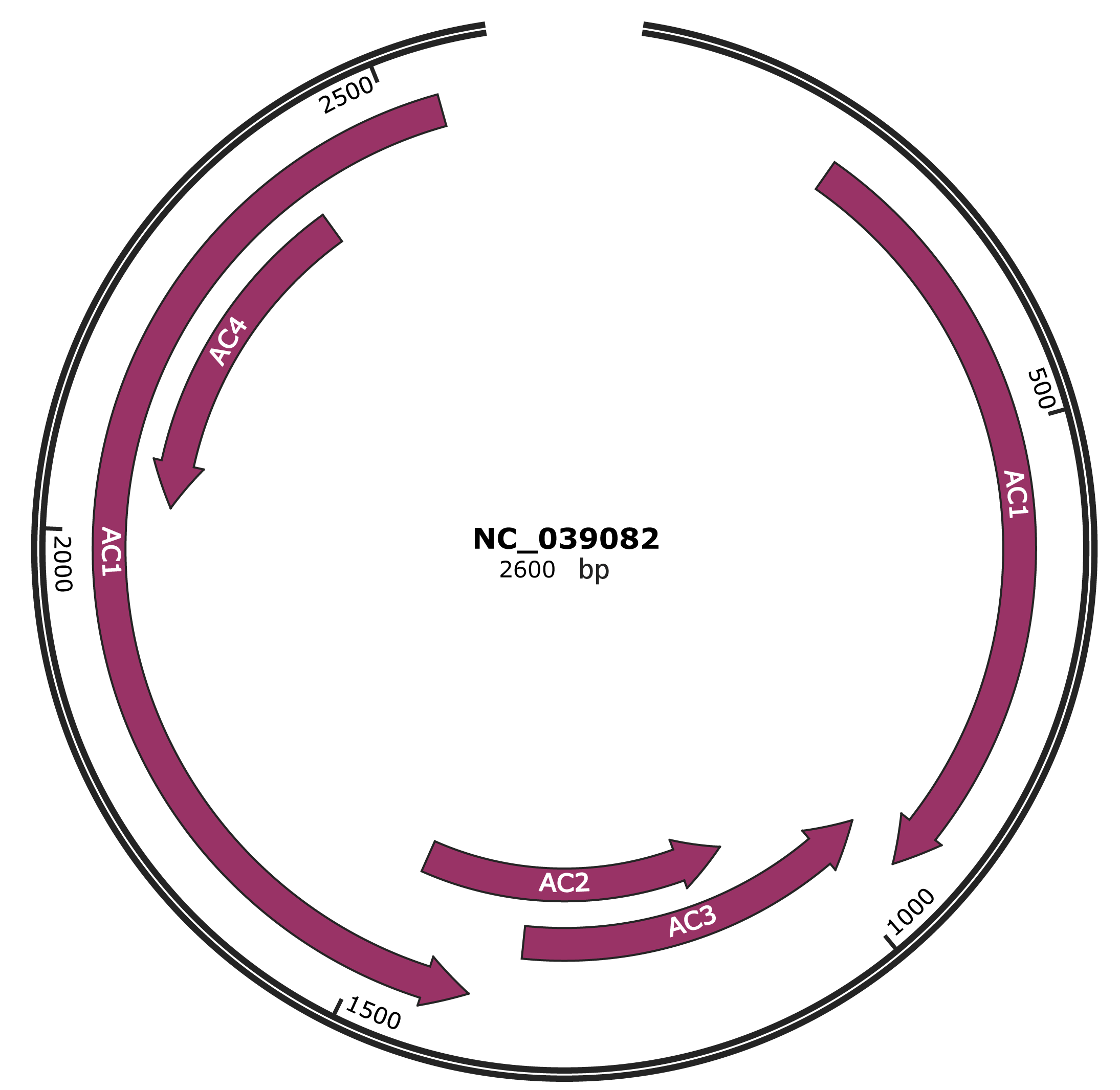
JBrowse
Genome
ATAGGATGGCCGCGATTTTTTTGGTGTCCTCTTTTAAGGCCCAGGCCCAAACGCATTTAGTTTTGAGGGGACCACACACAGATAACTATAGCCGACCAATCACATCACGTTATACGAGTTAAGATAAATGGGTCCTACTTGCTGAGTAAGTTGTGGTCCCTATATTAATAATTGACATTATTCGATATCTTTAATTCGAAATGCCTAAGCGTGATGCCCCATGGCGATTAATGGCGGGGACCTCCAAAGTCAGTCGTAATGTCAATTATTCGCCTCGTGGTGGTCCAAAATTGGACAAGGCCGCTGCTTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGCACTTTGCGAAGTCCAGATGTTCCTAAGGGTTGTGAAGGTCCTTGTAAAGTGCAGTCATACGAGCAGCGGCATGATGTTTCTCATGTTGGGAAGGTGATATGCATATCTGACGTCACACGAGGCAATGGCATAACTCATCGTGTGGGTAAGCGTTTTTGTGTGAAATCTGTGTACGTAATAGGCAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACGAACAGTGTCATGTTTTGGTTGGTGCGAGATCGTCGACCTTATGGCACGCCCATGGATTTTGGCCAGGTATTTAACATGTTCGACAACGAGCCTAGTACTGCTACCGTGAAGAACGATCTCCGTGACCGTTTTCAAGTTATGCACAAGTTTTACGCGAAGGTTACCGGTGGACAGTATGCTAGCAACGAGCAGGCGATTGTCAAGCGATTTTGGAAGGTCAACAACCATGTGGTATACAACCATCAAGAAGCTGGGAAGTACGAGAATCATACGGAGAACGCGTTACTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACGTTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAATAAAAATTGAATTTTATTTCATGATTCTCGAGTACATAATTTACATATGATCGATCAGTTGCGAAACGAACAGCCCTAATGACATGATTAAGACCAACAACACCCAATTGATCAATATACATTAAAACTAAATGCCTGAATCTACTTAAATAAATCATCCCAGAAGCTCGAATCGATGTCGTCCAGACTTGGAAGTTCAGGAAAGCTTTGCGTAGATTCAGTGCCCTCCTGAGGTTGTAATTGAACCGGACTTGGATGTGGTATATCCTGACTGACGTGTAAATTGGGTCCTCGACCCTGATGATCTTGAAATAGAGGGGATTTGGAACCTCCCAAATAAAAACGGAATTCTCCGCCTGAGACACAGTGATGAACTCCCCGGTGCTTAAATCCATAATCTGCACAGTCGATATGGAGGAATATGGAACAGCCGCAGTTCAAGTCAATTCGCCGTCGACGTATAGCTCTCTTCTTGGCTATCTTGTGCTGTGCTTTGATAGAGGGGGGAGTGGAGGAAGATGAATTTAGCATTTTTGCGTGTCCAAGCTCTCAGAGATGCATTCTCCTCTTTGTTGAGGAAGTCTTTATAACTGGCCCCCTCTCCTGGATTGCACAGCACGATTGATGGTATCCCGCCTTTAATTTGAACCGGCTTTCCATATTTACAGTTGGACTGCCAGTCTCTTTGGGACCCAATCAGTTCCTTCCAGTGCTTTAGCTTTAGATAGTGCGGTGCGACGTCATCTATGACGTTATAATCCACGTCATTCGAATAAACCCTAGAATTGAAATCTAGATGTCCACTCAGATAGTTATGTGGGCCTAAAGCCCTAGCCCACATCGTCTTGCCCGTTCGACTATCCCCTTCAACTATGATACTAATAGGTCTCTCCGGCCGCGCAGCGGCACCCCTTCCGAAATAATCATCCGCCCACTCTTGCATATCAGACGGAACATTATTAAACGACGACAATTGAAATGGAGCAATCCAAGGAAGGGGTGGTTTCTGGAAGAGGCGATCGATGTTAGCTCTCACGTTATGATAGCTTACGATGAACGTTCTTGGATCACCAGCTTTTATGATGTCGAGAGCCTCTCCTGCAGTTGCTGCATTGACGGCGTTGTGATAGACATCGTCTTTATTGGACTTGGAACCCCCAGACACTTTGTACTGTCCGGATTCACAATAATCACCCTCCTTGGTGATGTAATTCTTGACGGCGTTGGTGTCTTTTGCAGCTTGGACATTTGGATGGAATCCGGCAGACCGTCTGGGGTGAGTGAGGTCGAAAAATCTAGCATCCTTGATATTGGACTTGCCGGAGAGTTGAATAAGACAGTGGAGATGGGGGAACCCATCGGAGTGTTGTTCCCGAGCGACTCGGATGTACGTGGGCTTGACGACAGACCATGGCAAGTCCCGAAGCAACTGCATAGCCTCATCTTTTGTTATGTCGCACTGCGGATAAGTGAGGAATATGTTTTTAGCAGTTAAACGAAATGAATTAGGGTTCCGTGGCATTTTTGTAAATATAGCCCAGGACACCAGGGGGAGCTCTCTCAAAAATCTTATTTTGCTGGTGTCCTGGTGTCCCATTTATACTAAAAGCCTCTTGGGACACCAAAAAATCGCGGCCATCCGATAATATT
Gene Information
|
NCBI Accession
|
YP_009508880.1
|
|
Location
|
201-950 |
|
Gene Name
|
AC1 |
|
Protein Name
|
CP |
|
Coding Region
|
ATGCCTAAGCGTGATGCCCCATGGCGATTAATGGCGGGGACCTCCAAAGTCAGTCGTAATGTCAATTATTCGCCTCGTGGTGGTCCAAAATTGGACAAGGCCGCTGCTTGGGTTAACAGGCCCATGTATAGGAAGCCCAGGATCTATCGCACTTTGCGAAGTCCAGATGTTCCTAAGGGTTGTGAAGGTCCTTGTAAAGTGCAGTCATACGAGCAGCGGCATGATGTTTCTCATGTTGGGAAGGTGATATGCATATCTGACGTCACACGAGGCAATGGCATAACTCATCGTGTGGGTAAGCGTTTTTGTGTGAAATCTGTGTACGTAATAGGCAAGATATGGATGGACGAGAATATCAAGTTGAAGAACCACACGAACAGTGTCATGTTTTGGTTGGTGCGAGATCGTCGACCTTATGGCACGCCCATGGATTTTGGCCAGGTATTTAACATGTTCGACAACGAGCCTAGTACTGCTACCGTGAAGAACGATCTCCGTGACCGTTTTCAAGTTATGCACAAGTTTTACGCGAAGGTTACCGGTGGACAGTATGCTAGCAACGAGCAGGCGATTGTCAAGCGATTTTGGAAGGTCAACAACCATGTGGTATACAACCATCAAGAAGCTGGGAAGTACGAGAATCATACGGAGAACGCGTTACTATTGTATATGGCATGTACTCATGCCTCTAATCCTGTGTATGCTACGTTGAAAATTCGGATCTATTTTTATGATTCGATAACAAATTAA |
|
Protein Sequence
|
MPKRDAPWRLMAGTSKVSRNVNYSPRGGPKLDKAAAWVNRPMYRKPRIYRTLRSPDVPKGCEGPCKVQSYEQRHDVSHVGKVICISDVTRGNGITHRVGKRFCVKSVYVIGKIWMDENIKLKNHTNSVMFWLVRDRRPYGTPMDFGQVFNMFDNEPSTATVKNDLRDRFQVMHKFYAKVTGGQYASNEQAIVKRFWKVNNHVVYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDSITN |
|
NCBI Accession
|
YP_009508881.1
|
|
Location
|
947-1345 |
|
Gene Name
|
AC3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTTAAGCACCGGGGAGTTCATCACTGTGTCTCAGGCGGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATCAGGGTCGAGGACCCAATTTACACGTCAGTCAGGATATACCACATCCAAGTCCGGTTCAATTACAACCTCAGGAGGGCACTGAATCTACGCAAAGCTTTCCTGAACTTCCAAGTCTGGACGACATCGATTCGAGCTTCTGGGATGATTTATTTAAGTAGATTCAGGCATTTAGTTTTAATGTATATTGATCAATTGGGTGTTGTTGGTCTTAATCATGTCATTAGGGCTGTTCGTTTCGCAACTGATCGATCATATGTAAATTATGTACTCGAGAATCATGAAATAAAATTCAATTTTTATTAA |
|
Protein Sequence
|
MDLSTGEFITVSQAENSVFIWEVPNPLYFKIIRVEDPIYTSVRIYHIQVRFNYNLRRALNLRKAFLNFQVWTTSIRASGMIYLSRFRHLVLMYIDQLGVVGLNHVIRAVRFATDRSYVNYVLENHEIKFNFY |
|
NCBI Accession
|
YP_009508882.1
|
|
Location
|
1092-1481 |
|
Gene Name
|
AC2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCTAAATTCATCTTCCTCCACTCCCCCCTCTATCAAAGCACAGCACAAGATAGCCAAGAAGAGAGCTATACGTCGACGGCGAATTGACTTGAACTGCGGCTGTTCCATATTCCTCCATATCGACTGTGCAGATTATGGATTTAAGCACCGGGGAGTTCATCACTGTGTCTCAGGCGGAGAATTCCGTTTTTATTTGGGAGGTTCCAAATCCCCTCTATTTCAAGATCATCAGGGTCGAGGACCCAATTTACACGTCAGTCAGGATATACCACATCCAAGTCCGGTTCAATTACAACCTCAGGAGGGCACTGAATCTACGCAAAGCTTTCCTGAACTTCCAAGTCTGGACGACATCGATTCGAGCTTCTGGGATGATTTATTTAAGTAG |
|
Protein Sequence
|
MLNSSSSTPPSIKAQHKIAKKRAIRRRRIDLNCGCSIFLHIDCADYGFKHRGVHHCVSGGEFRFYLGGSKSPLFQDHQGRGPNLHVSQDIPHPSPVQLQPQEGTESTQSFPELPSLDDIDSSFWDDLFK |
|
NCBI Accession
|
YP_009508883.1
|
|
Location
|
1393-2547 |
|
Gene Name
|
AC1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGGGACACCAGGACACCAGCAAAATAAGATTTTTGAGAGAGCTCCCCCTGGTGTCCTGGGCTATATTTACAAAAATGCCACGGAACCCTAATTCATTTCGTTTAACTGCTAAAAACATATTCCTCACTTATCCGCAGTGCGACATAACAAAAGATGAGGCTATGCAGTTGCTTCGGGACTTGCCATGGTCTGTCGTCAAGCCCACGTACATCCGAGTCGCTCGGGAACAACACTCCGATGGGTTCCCCCATCTCCACTGTCTTATTCAACTCTCCGGCAAGTCCAATATCAAGGATGCTAGATTTTTCGACCTCACTCACCCCAGACGGTCTGCCGGATTCCATCCAAATGTCCAAGCTGCAAAAGACACCAACGCCGTCAAGAATTACATCACCAAGGAGGGTGATTATTGTGAATCCGGACAGTACAAAGTGTCTGGGGGTTCCAAGTCCAATAAAGACGATGTCTATCACAACGCCGTCAATGCAGCAACTGCAGGAGAGGCTCTCGACATCATAAAAGCTGGTGATCCAAGAACGTTCATCGTAAGCTATCATAACGTGAGAGCTAACATCGATCGCCTCTTCCAGAAACCACCCCTTCCTTGGATTGCTCCATTTCAATTGTCGTCGTTTAATAATGTTCCGTCTGATATGCAAGAGTGGGCGGATGATTATTTCGGAAGGGGTGCCGCTGCGCGGCCGGAGAGACCTATTAGTATCATAGTTGAAGGGGATAGTCGAACGGGCAAGACGATGTGGGCTAGGGCTTTAGGCCCACATAACTATCTGAGTGGACATCTAGATTTCAATTCTAGGGTTTATTCGAATGACGTGGATTATAACGTCATAGATGACGTCGCACCGCACTATCTAAAGCTAAAGCACTGGAAGGAACTGATTGGGTCCCAAAGAGACTGGCAGTCCAACTGTAAATATGGAAAGCCGGTTCAAATTAAAGGCGGGATACCATCAATCGTGCTGTGCAATCCAGGAGAGGGGGCCAGTTATAAAGACTTCCTCAACAAAGAGGAGAATGCATCTCTGAGAGCTTGGACACGCAAAAATGCTAAATTCATCTTCCTCCACTCCCCCCTCTATCAAAGCACAGCACAAGATAGCCAAGAAGAGAGCTATACGTCGACGGCGAATTGA |
|
Protein Sequence
|
MGHQDTSKIRFLRELPLVSWAIFTKMPRNPNSFRLTAKNIFLTYPQCDITKDEAMQLLRDLPWSVVKPTYIRVAREQHSDGFPHLHCLIQLSGKSNIKDARFFDLTHPRRSAGFHPNVQAAKDTNAVKNYITKEGDYCESGQYKVSGGSKSNKDDVYHNAVNAATAGEALDIIKAGDPRTFIVSYHNVRANIDRLFQKPPLPWIAPFQLSSFNNVPSDMQEWADDYFGRGAAARPERPISIIVEGDSRTGKTMWARALGPHNYLSGHLDFNSRVYSNDVDYNVIDDVAPHYLKLKHWKELIGSQRDWQSNCKYGKPVQIKGGIPSIVLCNPGEGASYKDFLNKEENASLRAWTRKNAKFIFLHSPLYQSTAQDSQEESYTSTAN |
|
NCBI Accession
|
YP_009508884.1
|
|
Location
|
2028-2393 |
|
Gene Name
|
AC4 |
|
Protein Name
|
AC4 protein |
|
Coding Region
|
ATGAGGCTATGCAGTTGCTTCGGGACTTGCCATGGTCTGTCGTCAAGCCCACGTACATCCGAGTCGCTCGGGAACAACACTCCGATGGGTTCCCCCATCTCCACTGTCTTATTCAACTCTCCGGCAAGTCCAATATCAAGGATGCTAGATTTTTCGACCTCACTCACCCCAGACGGTCTGCCGGATTCCATCCAAATGTCCAAGCTGCAAAAGACACCAACGCCGTCAAGAATTACATCACCAAGGAGGGTGATTATTGTGAATCCGGACAGTACAAAGTGTCTGGGGGTTCCAAGTCCAATAAAGACGATGTCTATCACAACGCCGTCAATGCAGCAACTGCAGGAGAGGCTCTCGACATCATAA |
|
Protein Sequence
|
MRLCSCFGTCHGLSSSPRTSESLGNNTPMGSPISTVLFNSPASPISRMLDFSTSLTPDGLPDSIQMSKLQKTPTPSRITSPRRVIIVNPDSTKCLGVPSPIKTMSITTPSMQQLQERLSTS |