Erectites yellow mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000873285.1 |
| Isolate | Viet Nam: Hoabinh |
| Release date | 2015/2/13 |
| Submitter | Ha,C., Coombs,S., Revill,P., Harding,R., Vu,M., Dale,J., Ha,C.V., Revill,P.A., Harding,R.M., Vu,M.T., Dale,J.L. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
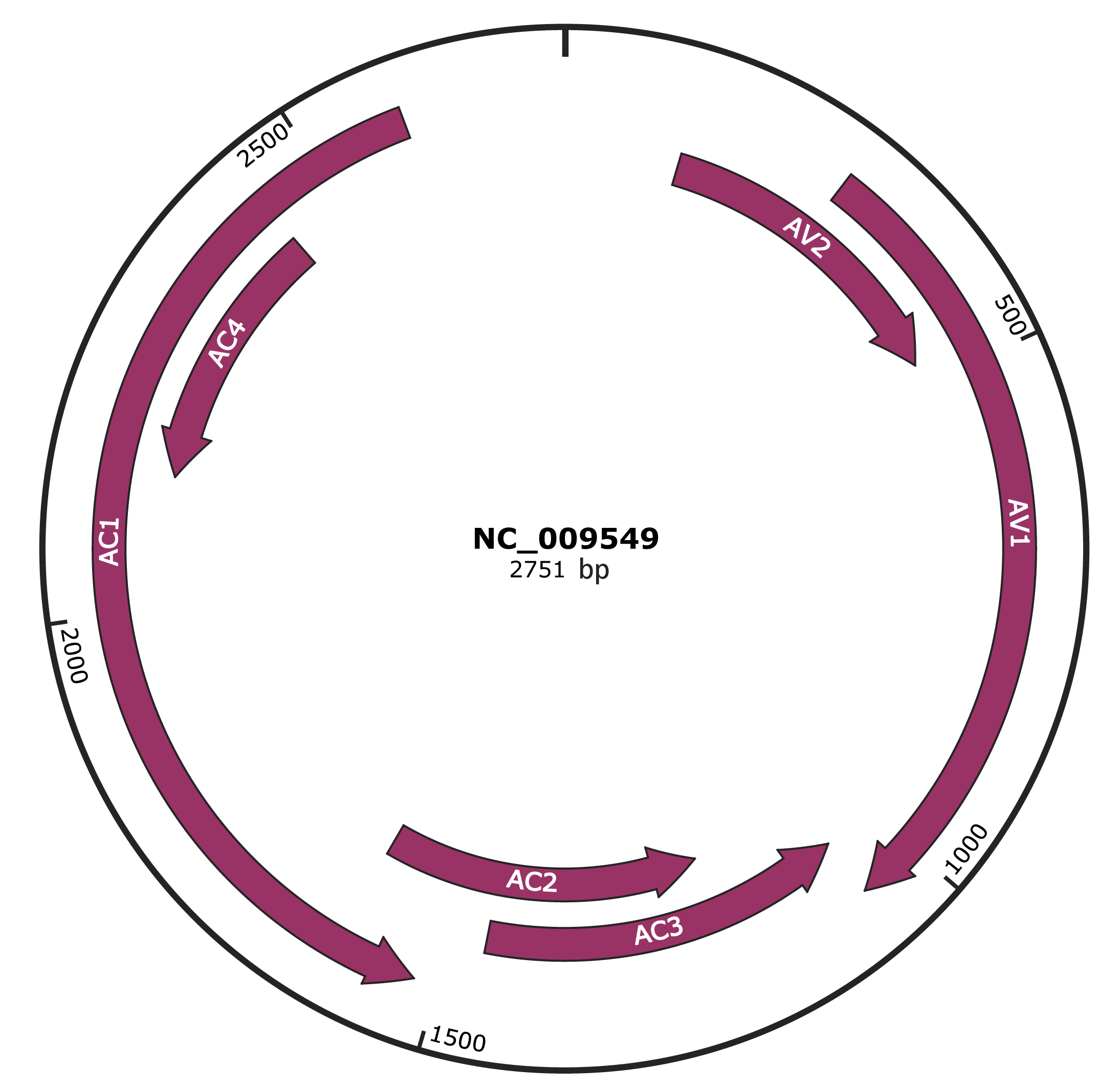
Genomic Organization
JBrowse
Genome
NC_009549
Gene Information
| NCBI Accession | YP_001285748.1 |
|---|---|
| Location | 127-477 |
| Gene Name | AV2 |
| Protein Name | AV2 protein |
| Coding Region | ATGTGGGATCCTTTACTAAACGAGTTCCCTGAGACCGTACATGGTTTTAGGTGTATGTTAGCAATTAAATATTTGCAACTAGTAGAAAATACATACTCTCCCGACACATTAGGTTACGACCTAATACGTGATCTCATCTTGGTGATTCGTGCTAGGGATTATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACTCCCGCCTCCAAGGTTCGTCGCCGATTGAACTTCGACAGCCCATATGTCAGCCGTGCTGCTGCCCCTACTGTCCTCGTCACAAACAAAAGGAGGTCATGGGCCAACCGGCCCATGAACAGAAAGCCCAGGATCTACAGGATGTACAAAAGCCCTGA |
| Protein Sequence | MWDPLLNEFPETVHGFRCMLAIKYLQLVENTYSPDTLGYDLIRDLILVIRARDYVEASRRYSHFHSRLQGSSPIELRQPICQPCCCPYCPRHKQKEVMGQPAHEQKAQDLQDVQKP |
| NCBI Accession | YP_001285749.1 |
|---|---|
| Location | 287-1060 |
| Gene Name | AV1 |
| Protein Name | CP protein |
| Coding Region | ATGTCGAAGCGTCCCGCAGATATAGTCATTTCCACTCCCGCCTCCAAGGTTCGTCGCCGATTGAACTTCGACAGCCCATATGTCAGCCGTGCTGCTGCCCCTACTGTCCTCGTCACAAACAAAAGGAGGTCATGGGCCAACCGGCCCATGAACAGAAAGCCCAGGATCTACAGGATGTACAAAAGCCCTGATGTTCCTCGGGGCTGTGAAGGCCCATGTAAGGTCCAGTCCTATGAACAACGTCATGATGTAGCCCATGTAGGTAAGGTAATTTGTGTCTCTGATGTCACCCGCGGTAATGGGCTGACACATCGTGTTGGTAAGAGGTTCTGTATTAAGTCTGTGTATGTGTTGGGAAAAATTTGGATGGATGAGAATATTAAGACCAAGAATCATACTAATACTGTCATGTTCTTCTTGGTTCGTGATAGGAGACCATTTGGTACTCCACAGGATTTTGGTCAGGTGTTCAACATGTATGATAATGAGCCCAGTACGGCCACCGTGAAGAACGACAATAGAGATCGATTTCAAGTCATTCGGCGTTTCCAGGCGACCGTGACGGGTGGTCAATATGCAAGCAAGGAACAGGCTATAGTTAGGAAATTCATGAAGGTCAACAACCATGTGACGTATAACCATCAAGAGGCTGCGAAGTATGATAACCACACAGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCTAGTAATCCAGTGTATGCTACTTTGAAAATCAGGATCTATTTCTATGATTCTGTTCAGAATTAA |
| Protein Sequence | MSKRPADIVISTPASKVRRRLNFDSPYVSRAAAPTVLVTNKRRSWANRPMNRKPRIYRMYKSPDVPRGCEGPCKVQSYEQRHDVAHVGKVICVSDVTRGNGLTHRVGKRFCIKSVYVLGKIWMDENIKTKNHTNTVMFFLVRDRRPFGTPQDFGQVFNMYDNEPSTATVKNDNRDRFQVIRRFQATVTGGQYASKEQAIVRKFMKVNNHVTYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
| NCBI Accession | YP_001285750.1 |
|---|---|
| Location | 1057-1461 |
| Gene Name | AC3 |
| Protein Name | REn protein |
| Coding Region | ATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGGAGAGAATGGCGTATATATCTGGACGGTCAACAATCCCCTGTATTTCAAAATAACACAACACCACGAGAGGCCATTCATGATGAAACACGACGTAATCACAGTGCAGGTCCAGTTCAACTACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAATCTGCCAAATCTGGACTCGTTTACGTCCTCAGACCTCGCGTTTCTTAAGAGTATTTAAATATCAATGTATGAAATATTTAGACATGTTAGGAGTAATTAGCATCAACAATGTAATTAGAGCAATTAATCATGTATTGTACAATGTATTGGAAGGCACAATTGATGCACATCTCTCAAATATAATAAAATTCAACATTTATTAA |
| Protein Sequence | MDSRTGEPITAAQGENGVYIWTVNNPLYFKITQHHERPFMMKHDVITVQVQFNYNLRKALGIHKCFLICQIWTRLRPQTSRFLRVFKYQCMKYLDMLGVISINNVIRAINHVLYNVLEGTIDAHLSNIIKFNIY |
| NCBI Accession | YP_001285751.1 |
|---|---|
| Location | 1202-1606 |
| Gene Name | AC2 |
| Protein Name | TrAP protein |
| Coding Region | ATGCAATCTTCGTCACCCTCGAGGGCCCACTCTACTCAGGTACCCATCAAAGTGCGACACAGAATCGCCAAGAAGACAACTAGAAGAAGACGAGTTGATCTCCCTTGTGGGTGTTCATTTTTCGTCGCTCTCAAGTGTCATAACCATGGATTCACGCACAGGGGAACCCATCACTGCAGCTCAAGGAGAGAATGGCGTATATATCTGGACGGTCAACAATCCCCTGTATTTCAAAATAACACAACACCACGAGAGGCCATTCATGATGAAACACGACGTAATCACAGTGCAGGTCCAGTTCAACTACAACCTGAGGAAAGCGTTGGGGATACACAAATGTTTTCTAATCTGCCAAATCTGGACTCGTTTACGTCCTCAGACCTCGCGTTTCTTAAGAGTATTTAA |
| Protein Sequence | MQSSSPSRAHSTQVPIKVRHRIAKKTTRRRRVDLPCGCSFFVALKCHNHGFTHRGTHHCSSRREWRIYLDGQQSPVFQNNTTPREAIHDETRRNHSAGPVQLQPEESVGDTQMFSNLPNLDSFTSSDLAFLKSI |
| NCBI Accession | YP_001285752.1 |
|---|---|
| Location | 1524-2594 |
| Gene Name | AC1 |
| Protein Name | rep protein |
| Coding Region | ATGCCTCCTCCTAATAAATTCAGAATAAATGCCAAAAACTATTTCCTCACATATCCACGCTGTTCTCTTACCAAAGAGGAGGCACTTTCCCAAATTAAAGCCCTAGAAACACCAATTTCTAAATTATTCATCAGAATCTGCAGGGAACTCCACGAAGATGGAACTCCTCACCTGCATATCCTCATCCAATTCGAAGGGAAATTCCAGTGTAAAAATCAAAGATTCTTCGATCTCATATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCATCAGATGTTAAATCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAATTTTCCAGATCGATGGACGATCGGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCACTCAATTCAGGGGCCAAAGCATCGGCCCTCAATATATTAAGGGAGAAAGCTCCCAAAGATTTTGTTTTACAGTTCCATAATTTAAATAATAATTTAGATAGGATTTTTACTCATCCAATAGAAATTTACATTTCTCCTTTTTGTTCTTCTTCATTCGACCAAGTTCCAGAGGAACTTAATGAATGGGTTTCCGCAAACGTTGTCAATGCCGCTGCGCGGCCATTAAGACCGATAAGTATTGTGGTAGAGGGCGATAGTAGGACAGGGAAGACGATATGGGCCAGGTCTTTGGGACCACATAACTACTTATGCGGACATTTAGATTTAAGTCCAAAAGTGTACAACAACAGTGCCTGGTATAACGTCATTGATGACGTCGATCCCCACTATCTAAAGCACTTTAAAGAGTTCATGGGGGCCCAAAGAGACTGGCAAAGCAACACCAAATACGGGAAGCCAGTTCAAATTAAAGGGGGTATTCCCACTATCTTCCTCTGCAATCCAGGACCACATTCCAGCTATAAAGAGTTCTTGGATGAAGAAAAGAACAGCGCACTTAAAAATTGGGCTGTAAAGAATGCAATCTTCGTCACCCTCGAGGGCCCACTCTACTCAGGTACCCATCAAAGTGCGACACAGAATCGCCAAGAAGACAACTAG |
| Protein Sequence | MPPPNKFRINAKNYFLTYPRCSLTKEEALSQIKALETPISKLFIRICRELHEDGTPHLHILIQFEGKFQCKNQRFFDLISPTRSAHFHPNIQGAKSSSDVKSYMEKDGDVLDHGIFQIDGRSARGGCQSANDAYAEALNSGAKASALNILREKAPKDFVLQFHNLNNNLDRIFTHPIEIYISPFCSSSFDQVPEELNEWVSANVVNAAARPLRPISIVVEGDSRTGKTIWARSLGPHNYLCGHLDLSPKVYNNSAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPHSSYKEFLDEEKNSALKNWAVKNAIFVTLEGPLYSGTHQSATQNRQEDN |
| NCBI Accession | YP_001285753.1 |
|---|---|
| Location | 2144-2437 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGAACTCCTCACCTGCATATCCTCATCCAATTCGAAGGGAAATTCCAGTGTAAAAATCAAAGATTCTTCGATCTCATATCCCCAACCAGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAAAGCTCATCAGATGTTAAATCATACATGGAAAAAGACGGAGACGTGCTTGATCATGGAATTTTCCAGATCGATGGACGATCGGCTAGAGGAGGTTGCCAATCTGCCAACGACGCATATGCCGAGGCACTCAATTCAGGGGCCAAAGCATCGGCCCTCAATATATTAA |
| Protein Sequence | MELLTCISSSNSKGNSSVKIKDSSISYPQPGQHISIQTFRELKAHQMLNHTWKKTETCLIMEFSRSMDDRLEEVANLPTTHMPRHSIQGPKHRPSIY |
References More References in PubMed
| 1 |
Wheat yellow mosaic virus NIb targets TaVTC2 to elicit broad-spectrum pathogen resistance in wheat. Zhang T, et al. Plant Biotechnol J. 2023 May;21(5):1073-1088. doi: 10.1111/pbi.14019. Epub 2023 Feb 14. PMID: 36715229 |
|---|---|
| 2 |
Dokka N, et al. Plant Dis. 2023 Oct;107(10):2924-2928. doi: 10.1094/PDIS-06-22-1473-SC. Epub 2023 Oct 11. PMID: 36890129 |
| 3 |
Australian Cool-Season Pulse Seed-Borne Virus Research: 2. Bean Yellow Mosaic Virus. Jones RAC. Viruses. 2025 May 3;17(5):668. doi: 10.3390/v17050668. PMID: 40431680 |
| 4 |
Geng G, et al. Virol J. 2019 Feb 20;16(1):23. doi: 10.1186/s12985-019-1130-z. PMID: 30786887 |
| 5 |
Development of an RT-LAMP assay for the detection of maize yellow mosaic virus in maize. Li X, et al. J Virol Methods. 2022 Feb;300:114384. doi: 10.1016/j.jviromet.2021.114384. Epub 2021 Nov 29. PMID: 34856307 |
| 6 |
Berbati M, et al. J Virol Methods. 2023 Nov;321:114805. doi: 10.1016/j.jviromet.2023.114805. Epub 2023 Sep 4. PMID: 37673287 |
| 7 |
Chen D, et al. Plant J. 2023 Dec;116(6):1717-1736. doi: 10.1111/tpj.16461. Epub 2023 Sep 26. PMID: 37751381 |
| 8 |
Portraits of viruses: turnip yellow mosaic virus. Matthews RE. Intervirology. 1981;15(3):121-44. doi: 10.1159/000149223. PMID: 7026488 |
| 9 |
Kan J, et al. Plant Biotechnol J. 2023 May;21(5):893-895. doi: 10.1111/pbi.14002. Epub 2023 Jan 24. PMID: 36628413 |
| 10 |
Liu P, et al. Nat Commun. 2023 Nov 27;14(1):7773. doi: 10.1038/s41467-023-43643-y. PMID: 38012219 |