Emilia yellow vein Fujian virus
Basic Information
| Genus |
Begomovirus
|
| NCBI Assembly |
GCF_013088295.1 |
| Isolate |
China: Fujian province |
| Release date |
2021/6/1 |
| Submitter |
Liu,Z. |
| Host |
|
| Vector |
|
| Download |
Genome
|GFF3
|PEP
|CDS |
Genomic Organization
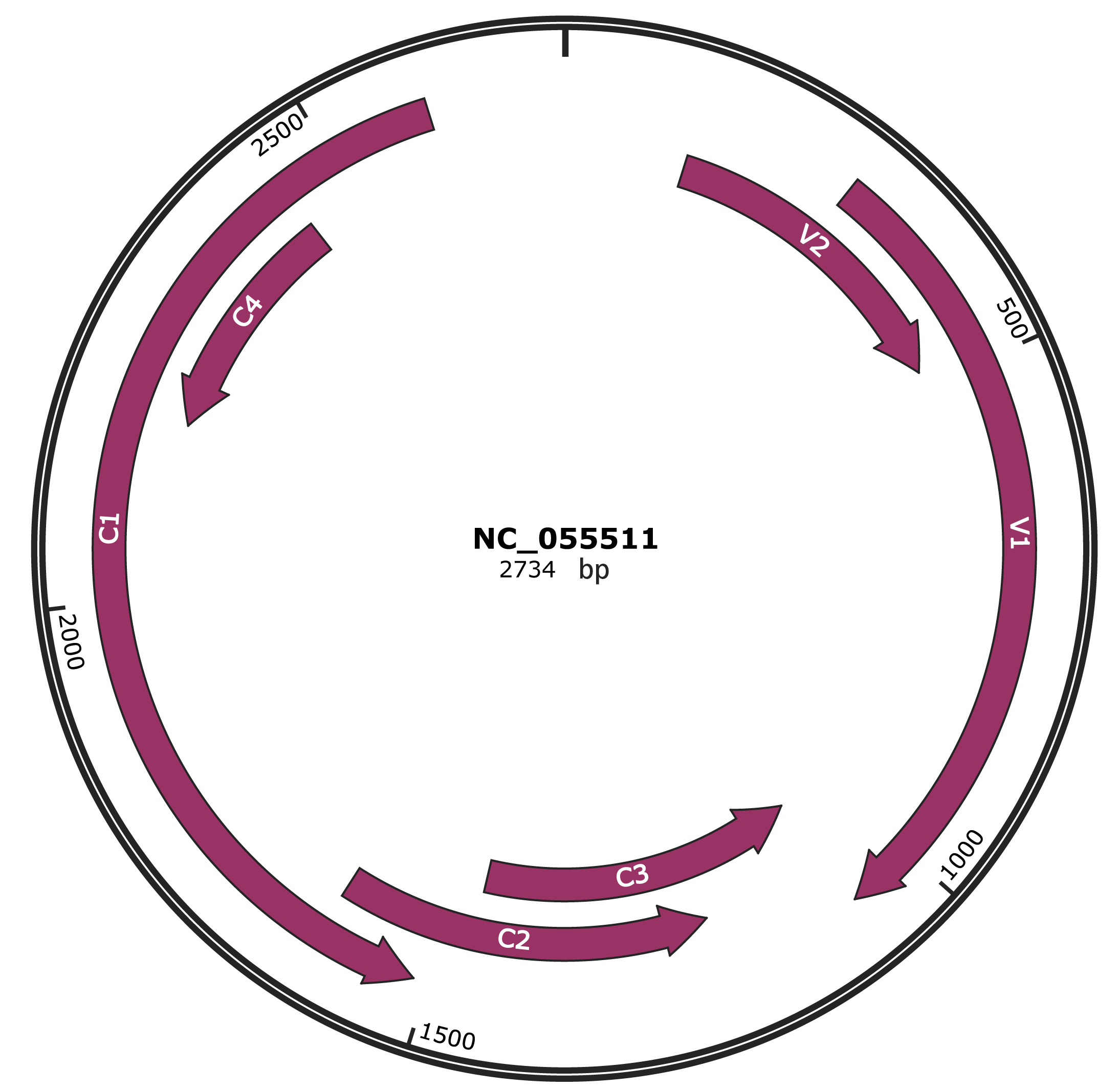
JBrowse
Genome
ACCGGATGGCCGCCCTTTTTTTTAAAGTGGGCCCCTCCACTCATACTTGTCCCCCACTCTGAACGCTCCCTCAAAGCTTATTTAGTAGGTGGTCCCCTATTTATATCTTAGAGACCAAGTTTTACCACAAACATGTGGGATCCACTTTTGAATGAGTTCCCTGATACTGTTCATGGTCTACGGTGTATGCTAGCAAAAAAATACGTACCAGGAGTTCAGAAGACGTATTCTCCGGATACGATTGGGTACGATTTATTTTGTGATTTGATACATCTTCTAAACACAAAAAATTATGAGCAAGCGTCCAGCAGATATAGTCATTTCTACTCCCGCCTCCAAGGTACGCCGCCGTCTGAACTTCGACACCCCTTATTCCAGTCGTGTTGTTGCCCCCACTGTCCTCGTCACAAACAAAAGGCGAGCATGGACACAGAGGCCCATGTATCGGAAGCCCAGACAATACAGAATGTACAGAAGCCCTGATGTCCCTAAAGGATGCGAGGGCCCATGTAAGGTCCAGTCCTATGAACAGCGACATGATATTTCTCATGTGGGTAAGGTTTTGTGTGTTAGTGACGTTACTCGTGGTAATGGGCTTACCCATCGTGTGGGTAAGAGATTCTGTGTTAAGTCAGTTTATGTTCTGGGTAAGATATGGATGGACGAAAACATCAAGACCAAAAATCATACCAACACGGTCATGTTTTATCTGGTTCGTGATAGAAGGCCTTTTGGCACTGCAATGGATTTTGGTCAGGTGTTTAACATGTATGACAATGAGCCCAGTACTGCTACTGTGAAGAACGACATGCGAGATCGTTACCAGGTTTTGAGGAAGTTTACTGCAACTGTGACTGGTGGTCAATATGCTTCGAAGGAACAGGCATTAGTTAGGAAATTTATGAAGATCAATAATTACGTTGTATATAATCATCAAGAGGCTGCGAAATATGATAACCACACAGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCCAGTAATCCAGTGTATGCTACATTGAAAATCAGAATCTATTTCTATGATTCAGTTCAGAATTAATAAATATTGAATTTTATTATATGAGAAACTTGTACATCGATTGTCTTTTCAAGTACATCGTACAGTACATGGTCGACTGCTCTGATTACGTTGTTTATGCTTATAACCCCTAAACTATCTAAATACTTCATACATTGATATTTAAATACTCTTAAGAAACGCCAAGTCTGAGGATGTAAATGAGTCCAGATTCTGTAGATCAGAAAACACTGGTGTATTCCCAACGCTTTCCTCAGGTTGTGATTGAACTGTAGTTGTATTGTTATGACATCGTAGTTCCTCAGGAACGGTCTCGTGTCGTGTTGGGATATCTTGAAATAGAGGGGATTTGTTATCGTCCAGGTATATACGCCATTCTCTGCTTGAGCTGCAGTGATAAGTCCCCCTGTGCGAGAATCCATATGACGCGCAGTTAAGTCCTAAATAGTAAGAGCAGCCGCATGAGAGATCAATCCTCCTCCTGCGTCCTGGTCTCTTCTTGGCTATTTTGTGTTGGACTTTGATGGGTACCTGAGTACAATGGTTGTGTGATGGTGATGAATTCTGCATTCTTTATTGCCCACTCTTTGAGTGCAGAATTCTTTTCTTCGTCCAAGTACTCTTTATACGATGATGTTGGTCCAGGATTGCAGAAGGAAGATAGTTGGGATTCCCCTTTAATTTGAAATGGGTTTCCCGTACTTCGTGTTGCTTGCCAGTCCCTTTGGGCCCCCATGAATTCTTTAAAGTGCTTTAGATAGTGGGGGTCTACGTCATCAATGACGTTGTACCAGGCATCATTACTGTATACCTTTGGACTTAGGTCAAGGTGCCCACATAAATAATTATGTGGACCCAATGACCTGGCCCACATCGTCTTTCCTGTACGACTCTCTCCCTCTATGACAATACTTTTGGGTCTCCAAGGCCGCGCAGCGGCACCACTCACATTCTCAGAAACCCACTCTTCAAGTTCTTCTGGAACTTGATCGAAAGAAGAAGATAAAAAAGGACATATAAATACCTCTAAAGGAGGTGCAAAAATCCTATCTAAATTAGTATTTAAATTATGAAATTGAAAAATATATTCTTTTGGAAGTTTTTCCCTTATTATTGCCATTGCTGCCTCTTTCGAACCTGCGTTTAACGCGTCTGCAGCTGCATCGTTAGCCGTCTGTTGACCTCCTCTAGCAGATCTTCCGTCGATCTGAAACACACCCCAGTCGACGTAATCACCGTCCTTCTCGATGTAGGACTTGACATCGGAACTGGACTTAGCTCCCTGGAAGTTTGGATGGAATTGTGTGGAGGTGTTGGGGTGTGTAAGGTCGAAGTGTCGACTATTTCTGAACTGGGCTTTACCTTTGAATTGTATGAGTGCGTGGAGATGCAGAGTCCCATCGGAGTGTTTTTCTTGTGCAACTCTGATAAATAATTTATCAGAAGGGCATTGTATATTTTTAATAAGCTCTAAGGCTTCTTCTTTGGGAATGGGGCATTTCGGATAAGTGAGGAAGATATTTTTGGCTTTTACTTGAAATGAACTTGAACGAGGCATTTTGACTAAGTCAATTGGGTGCTCTCAATCTTCTCTGGAATGGGGTGCTTTGGGTGCCTATTTATACGGAGCTCCCAATAGAAATTCAAAATTCAAATTTGAAATCCAAAAGCGGCCATCCGTATAATATT
Gene Information
|
NCBI Accession
|
YP_010087190.1
|
|
Location
|
133-483 |
|
Gene Name
|
V2 |
|
Protein Name
|
V2 |
|
Coding Region
|
ATGTGGGATCCACTTTTGAATGAGTTCCCTGATACTGTTCATGGTCTACGGTGTATGCTAGCAAAAAAATACGTACCAGGAGTTCAGAAGACGTATTCTCCGGATACGATTGGGTACGATTTATTTTGTGATTTGATACATCTTCTAAACACAAAAAATTATGAGCAAGCGTCCAGCAGATATAGTCATTTCTACTCCCGCCTCCAAGGTACGCCGCCGTCTGAACTTCGACACCCCTTATTCCAGTCGTGTTGTTGCCCCCACTGTCCTCGTCACAAACAAAAGGCGAGCATGGACACAGAGGCCCATGTATCGGAAGCCCAGACAATACAGAATGTACAGAAGCCCTGA |
|
Protein Sequence
|
MWDPLLNEFPDTVHGLRCMLAKKYVPGVQKTYSPDTIGYDLFCDLIHLLNTKNYEQASSRYSHFYSRLQGTPPSELRHPLFQSCCCPHCPRHKQKASMDTEAHVSEAQTIQNVQKP |
|
NCBI Accession
|
YP_010087191.1
|
|
Location
|
293-1066 |
|
Gene Name
|
V1 |
|
Protein Name
|
coat protein |
|
Coding Region
|
ATGAGCAAGCGTCCAGCAGATATAGTCATTTCTACTCCCGCCTCCAAGGTACGCCGCCGTCTGAACTTCGACACCCCTTATTCCAGTCGTGTTGTTGCCCCCACTGTCCTCGTCACAAACAAAAGGCGAGCATGGACACAGAGGCCCATGTATCGGAAGCCCAGACAATACAGAATGTACAGAAGCCCTGATGTCCCTAAAGGATGCGAGGGCCCATGTAAGGTCCAGTCCTATGAACAGCGACATGATATTTCTCATGTGGGTAAGGTTTTGTGTGTTAGTGACGTTACTCGTGGTAATGGGCTTACCCATCGTGTGGGTAAGAGATTCTGTGTTAAGTCAGTTTATGTTCTGGGTAAGATATGGATGGACGAAAACATCAAGACCAAAAATCATACCAACACGGTCATGTTTTATCTGGTTCGTGATAGAAGGCCTTTTGGCACTGCAATGGATTTTGGTCAGGTGTTTAACATGTATGACAATGAGCCCAGTACTGCTACTGTGAAGAACGACATGCGAGATCGTTACCAGGTTTTGAGGAAGTTTACTGCAACTGTGACTGGTGGTCAATATGCTTCGAAGGAACAGGCATTAGTTAGGAAATTTATGAAGATCAATAATTACGTTGTATATAATCATCAAGAGGCTGCGAAATATGATAACCACACAGAGAATGCTTTGTTATTGTATATGGCATGTACTCATGCCAGTAATCCAGTGTATGCTACATTGAAAATCAGAATCTATTTCTATGATTCAGTTCAGAATTAA |
|
Protein Sequence
|
MSKRPADIVISTPASKVRRRLNFDTPYSSRVVAPTVLVTNKRRAWTQRPMYRKPRQYRMYRSPDVPKGCEGPCKVQSYEQRHDISHVGKVLCVSDVTRGNGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNTVMFYLVRDRRPFGTAMDFGQVFNMYDNEPSTATVKNDMRDRYQVLRKFTATVTGGQYASKEQALVRKFMKINNYVVYNHQEAAKYDNHTENALLLYMACTHASNPVYATLKIRIYFYDSVQN |
|
NCBI Accession
|
YP_010087192.1
|
|
Location
|
1063-1467 |
|
Gene Name
|
C3 |
|
Protein Name
|
REn |
|
Coding Region
|
ATGGATTCTCGCACAGGGGGACTTATCACTGCAGCTCAAGCAGAGAATGGCGTATATACCTGGACGATAACAAATCCCCTCTATTTCAAGATATCCCAACACGACACGAGACCGTTCCTGAGGAACTACGATGTCATAACAATACAACTACAGTTCAATCACAACCTGAGGAAAGCGTTGGGAATACACCAGTGTTTTCTGATCTACAGAATCTGGACTCATTTACATCCTCAGACTTGGCGTTTCTTAAGAGTATTTAAATATCAATGTATGAAGTATTTAGATAGTTTAGGGGTTATAAGCATAAACAACGTAATCAGAGCAGTCGACCATGTACTGTACGATGTACTTGAAAAGACAATCGATGTACAAGTTTCTCATATAATAAAATTCAATATTTATTAA |
|
Protein Sequence
|
MDSRTGGLITAAQAENGVYTWTITNPLYFKISQHDTRPFLRNYDVITIQLQFNHNLRKALGIHQCFLIYRIWTHLHPQTWRFLRVFKYQCMKYLDSLGVISINNVIRAVDHVLYDVLEKTIDVQVSHIIKFNIY |
|
NCBI Accession
|
YP_010087193.1
|
|
Location
|
1208-1615 |
|
Gene Name
|
C2 |
|
Protein Name
|
TrAP |
|
Coding Region
|
ATGCAGAATTCATCACCATCACACAACCATTGTACTCAGGTACCCATCAAAGTCCAACACAAAATAGCCAAGAAGAGACCAGGACGCAGGAGGAGGATTGATCTCTCATGCGGCTGCTCTTACTATTTAGGACTTAACTGCGCGTCATATGGATTCTCGCACAGGGGGACTTATCACTGCAGCTCAAGCAGAGAATGGCGTATATACCTGGACGATAACAAATCCCCTCTATTTCAAGATATCCCAACACGACACGAGACCGTTCCTGAGGAACTACGATGTCATAACAATACAACTACAGTTCAATCACAACCTGAGGAAAGCGTTGGGAATACACCAGTGTTTTCTGATCTACAGAATCTGGACTCATTTACATCCTCAGACTTGGCGTTTCTTAAGAGTATTTAA |
|
Protein Sequence
|
MQNSSPSHNHCTQVPIKVQHKIAKKRPGRRRRIDLSCGCSYYLGLNCASYGFSHRGTYHCSSSREWRIYLDDNKSPLFQDIPTRHETVPEELRCHNNTTTVQSQPEESVGNTPVFSDLQNLDSFTSSDLAFLKSI |
|
NCBI Accession
|
YP_010087194.1
|
|
Location
|
1515-2603 |
|
Gene Name
|
C1 |
|
Protein Name
|
Rep |
|
Coding Region
|
ATGCCTCGTTCAAGTTCATTTCAAGTAAAAGCCAAAAATATCTTCCTCACTTATCCGAAATGCCCCATTCCCAAAGAAGAAGCCTTAGAGCTTATTAAAAATATACAATGCCCTTCTGATAAATTATTTATCAGAGTTGCACAAGAAAAACACTCCGATGGGACTCTGCATCTCCACGCACTCATACAATTCAAAGGTAAAGCCCAGTTCAGAAATAGTCGACACTTCGACCTTACACACCCCAACACCTCCACACAATTCCATCCAAACTTCCAGGGAGCTAAGTCCAGTTCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACGTCGACTGGGGTGTGTTTCAGATCGACGGAAGATCTGCTAGAGGAGGTCAACAGACGGCTAACGATGCAGCTGCAGACGCGTTAAACGCAGGTTCGAAAGAGGCAGCAATGGCAATAATAAGGGAAAAACTTCCAAAAGAATATATTTTTCAATTTCATAATTTAAATACTAATTTAGATAGGATTTTTGCACCTCCTTTAGAGGTATTTATATGTCCTTTTTTATCTTCTTCTTTCGATCAAGTTCCAGAAGAACTTGAAGAGTGGGTTTCTGAGAATGTGAGTGGTGCCGCTGCGCGGCCTTGGAGACCCAAAAGTATTGTCATAGAGGGAGAGAGTCGTACAGGAAAGACGATGTGGGCCAGGTCATTGGGTCCACATAATTATTTATGTGGGCACCTTGACCTAAGTCCAAAGGTATACAGTAATGATGCCTGGTACAACGTCATTGATGACGTAGACCCCCACTATCTAAAGCACTTTAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAGCAACACGAAGTACGGGAAACCCATTTCAAATTAAAGGGGAATCCCAACTATCTTCCTTCTGCAATCCTGGACCAACATCATCGTATAAAGAGTACTTGGACGAAGAAAAGAATTCTGCACTCAAAGAGTGGGCAATAAAGAATGCAGAATTCATCACCATCACACAACCATTGTACTCAGGTACCCATCAAAGTCCAACACAAAATAGCCAAGAAGAGACCAGGACGCAGGAGGAGGATTGA |
|
Protein Sequence
|
MPRSSSFQVKAKNIFLTYPKCPIPKEEALELIKNIQCPSDKLFIRVAQEKHSDGTLHLHALIQFKGKAQFRNSRHFDLTHPNTSTQFHPNFQGAKSSSDVKSYIEKDGDYVDWGVFQIDGRSARGGQQTANDAAADALNAGSKEAAMAIIREKLPKEYIFQFHNLNTNLDRIFAPPLEVFICPFLSSSFDQVPEELEEWVSENVSGAAARPWRPKSIVIEGESRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQATRSTGNPFQIKGESQLSSFCNPGPTSSYKEYLDEEKNSALKEWAIKNAEFITITQPLYSGTHQSPTQNSQEETRTQEED |
|
NCBI Accession
|
YP_010087195.1
|
|
Location
|
2189-2446 |
|
Gene Name
|
C4 |
|
Protein Name
|
C4 protein |
|
Coding Region
|
ATGGGACTCTGCATCTCCACGCACTCATACAATTCAAAGGTAAAGCCCAGTTCAGAAATAGTCGACACTTCGACCTTACACACCCCAACACCTCCACACAATTCCATCCAAACTTCCAGGGAGCTAAGTCCAGTTCCGATGTCAAGTCCTACATCGAGAAGGACGGTGATTACGTCGACTGGGGTGTGTTTCAGATCGACGGAAGATCTGCTAGAGGAGGTCAACAGACGGCTAACGATGCAGCTGCAGACGCGTTAA |
|
Protein Sequence
|
MGLCISTHSYNSKVKPSSEIVDTSTLHTPTPPHNSIQTSRELSPVPMSSPTSRRTVITSTGVCFRSTEDLLEEVNRRLTMQLQTR |