East African cassava mosaic virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000859785.1 |
| Isolate | Uganda |
| Release date | 2015/2/13 |
| Submitter | Pita,J.S., Fondong,V.N., Sangare,A., Otim-Nape,G.W., Ogwal,S., Fauquet,C.M., Beachy,R.N. |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
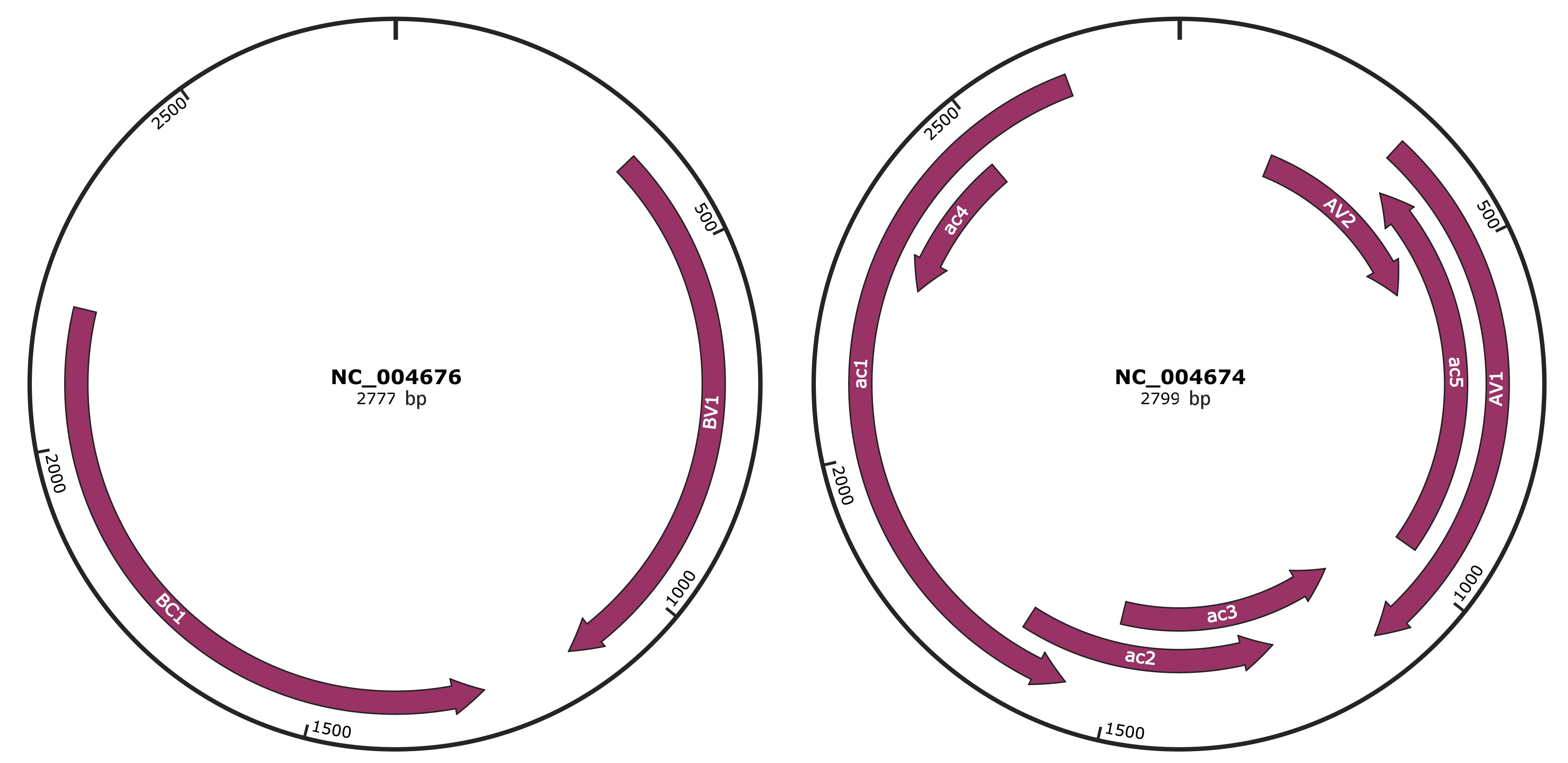
JBrowse
Genome
NC_004676
NC_004674
Gene Information
| NCBI Accession | NP_817128.1 |
|---|---|
| Location | 358-1134 |
| Gene Name | BV1 |
| Protein Name | BV1 protein |
| Coding Region | ATGTATTCTGTTTACAGGCGTGGGTATAAGACGCCGTATAGGAGTTCGTATGGCGCTCGTGTAACACCATATGTTTATCGTAAGACGGCTGGTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGCGTATGAATCGCCAAAATGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTAAAGTTGCCTCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGTATCGATGGTAATGGGGGTAGGTCTGTTGATCATATAAAATTATTAAGCTTGAGGGTGTCTGGGACCGTCAATATCAGTCAATGCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTTAGTATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTGTATGGCATGCCTAGGTTGAAGGAAAACGTTCGTCACCGTTATCGCGTGATTGGGACGTCGAAATTATATATAACGACCGATGAAGAGCACATCCAGAAGCCATTTAGTCTACGTCGAAGACTAAGTGGAGGGAAATATCCTATGTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGGAACTATAAAAATATAAATAAGAACGCTATACTAGTTAGTTATGTGTGGGTATCGCTATGTCGGTCCACGTGTGATGTGTATTCCCAGTTTGTACTTAATTACGTCGGTTGA |
| Protein Sequence | MYSVYRRGYKTPYRSSYGARVTPYVYRKTAGKQTSKSRVPRKLAYESPKCLYTRRSLEDIHNGASLKLPQQGDYTSYVTLPCRGIDGNGGRSVDHIKLLSLRVSGTVNISQCGGDDNMGERTTMRGIFFMACLVDKKPFVPEGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEEHIQKPFSLRRRLSGGKYPMWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLCRSTCDVYSQFVLNYVG |
| NCBI Accession | NP_817129.1 |
|---|---|
| Location | 1264-2187 |
| Gene Name | BC1 |
| Protein Name | BC1 protein |
| Coding Region | ATGGACAACCAATTCACCGTCACAGACAAGAATTACATCAACAGCAAACGCACAGAGTACGCATTAACCAACGATGCTGCACCAATCAATCTCCAATTCCCGAGCTCATTCGAGCAGGCTACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGAAACCAGGTCCCATTTAACGCAATTGGGTCGGTTATCGTAGAAATCAGAGACAATCGCGTCAGCCTTGAAGACGCTGCTCAAGCAGCATTCACTTTCCCAATAGCTTGCAACGTAGACCTCCACTACTTCTCGTCTACATATTTTTCGCTTTCAGAACCCTCCCCTTGGAGAATCATGTACAGAGTCGAAGACTCAAACGTCATAGAAGGCGTGAAATTCGCATCCATCAAGGCCAAGCTCCGATTATCATCGGCCAAACATTCCACGGACATACGTTTCAAACCCCCAACAATTAACATATTATCCAAGGGCTACACAAAGGATTGCATAGACTTCTGGTCCGTGGAAAAAGGAGAAACACGACGGAGATTACTAAATCCAACTCCACATGCTAATAGTCAACGACCCATAACCCACAGGCCCATCACCATTCTCCCTGGAGAAACATGGGCCACGAAGTCTCAAATTGGGCTACCCAGCTCATCCGGCCCAGCAAGGCTGGACCACTTTCGTTCACAGTCCATGAGAATGGGCCCATCGACAACCACAACGGACTTCGACAACGACTCCACAGAATATCCTTACCAGACACTACACAGATTACACACACCCGAATTGGACCCAGGGGACTCGGTATCACAGACCCCATCCGACTCAGTATCCCGAAAGGACCTCGAGACACTGCTTGAGAGTACCATAAACAAGTGTCTCATCAAAATAAAATCCGAAGCACCCAGGCAATTGTAA |
| Protein Sequence | MDNQFTVTDKNYINSKRTEYALTNDAAPINLQFPSSFEQATMRLKGRCMKIDHIIIEYRNQVPFNAIGSVIVEIRDNRVSLEDAAQAAFTFPIACNVDLHYFSSTYFSLSEPSPWRIMYRVEDSNVIEGVKFASIKAKLRLSSAKHSTDIRFKPPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPHANSQRPITHRPITILPGETWATKSQIGLPSSSGPARLDHFRSQSMRMGPSTTTTDFDNDSTEYPYQTLHRLHTPELDPGDSVSQTPSDSVSRKDLETLLESTINKCLIKIKSEAPRQL |
| NCBI Accession | NP_817107.1 |
|---|---|
| Location | 172-528 |
| Gene Name | AV2 |
| Protein Name | AV2 protein |
| Coding Region | ATGTGGGATCCATTGGTGAACGATTTTCCCGAAACCGTTCACGGTTTCCGTTCTATGCTTGCTGTTAAATACCTGTTACATTTGGAACAGGAATACGATCGCGGTACTGTCGGGGCTGAGTATATACGGGATCTAATAGGGGTTCTACGGTGTAAGAATTATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGGCCCATGTATCGGAAACCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAA |
| Protein Sequence | MWDPLVNDFPETVHGFRSMLAVKYLLHLEQEYDRGTVGAEYIRDLIGVLRCKNYVEATRRYNNLNTRIQGAEEAELRQPIHEPCCCPHCPRHQKQNMGQQAHVSETQDVQNVSKPRCP |
| NCBI Accession | NP_817108.1 |
|---|---|
| Location | 332-1105 |
| Gene Name | AV1 |
| Protein Name | AV1 protein |
| Coding Region | ATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGGCCCATGTATCGGAAACCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTCCAGTCTTTTGAGCAGAGGGATGATGTGAAGCACCTTGGTATCTGTAAGGTGATTAGTGATGTGACGCGTGGGCCTGGGCTGACACACAGGGTCGGAAAGAGGTTTTGTATCAAGTCCATTTACATTCTTGGTAAGATCTGGATGGATGAAAATATTAAGAAGCAGAATCACACTAATAATGTGATGTTTTACCTGCTTAGGGATAGAAGGCCGTATGGCAATGCGCCCCAAGACTTTGGGCAGATATTTAACATGTTTGATAATGAGCCCAGTACTGCAACAATTAAGAACGATTTGAGGGATAGGTTTCAGGTGTTGAGGAAATTTCATGCCACTGTTGTTGGTGGTCCATCTGGCATGAAGGAGCAGGCGTTGGTGAAAAGGTTTTACAAGCTGAATCATCACGTGACATATAATCATCAGGAGGCAGGGAAGTATGAGAATCACACAGAGAATGCGTTGTTATTGTATATGGCATGTACACATGCCTCGAATCCTGTGTATGCTACGCTGAAAATACGCATCTATTTTTATGATGCAGTGACAAATTAA |
| Protein Sequence | MSKRPGDIIISTPVSKVRRRLNFDSPYTNRVVAPTVRVTRSKIWANRPMYRKPKMYRMYRSPDVPKGCEGPCKVQSFEQRDDVKHLGICKVISDVTRGPGLTHRVGKRFCIKSIYILGKIWMDENIKKQNHTNNVMFYLLRDRRPYGNAPQDFGQIFNMFDNEPSTATIKNDLRDRFQVLRKFHATVVGGPSGMKEQALVKRFYKLNHHVTYNHQEAGKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
| NCBI Accession | NP_817109.1 |
|---|---|
| Location | 362-973 |
| Gene Name | ac5 |
| Protein Name | AC5 protein |
| Coding Region | ATGATTATATGTCACGTGATGATTCAGCTTGTAAAACCTTTTCACCAACGCCTGCTCCTTCATGCCAGATGGACCACCAACAACAGTGGCATGAAATTTCCTCAACACCTGAAACCTATCCCTCAAATCGTTCTTAATTGTTGCAGTACTGGGCTCATTATCAAACATGTTAAATATCTGCCCAAAGTCTTGGGGCGCATTGCCATACGGCCTTCTATCCCTAAGCAGGTAAAACATCACATTATTAGTGTGATTCTGCTTCTTAATATTTTCATCCATCCAGATCTTACCAAGAATGTAAATGGACTTGATACAAAACCTCTTTCCGACCCTGTGTGTCAGCCCAGGCCCACGCGTCACATCACTAATCACCTTACAGATACCAAGGTGCTTCACATCATCCCTCTGCTCAAAAGACTGGACCTTACATGGGCCTTCACAGCCCTTAGGGACATCTGGGCTTCGATACATTCTGTACATCTTGGGTTTCCGATACATGGGCCTGTTGGCCCATATTTTGCTTCTGGTGACGCGGACAGTGGGGGCAACAACACGGTTCGTGTATGGGCTGTCGAAGTTCAGCCTCCTCCGCACCTTGGATACGGGTGTTGA |
| Protein Sequence | MIICHVMIQLVKPFHQRLLLHARWTTNNSGMKFPQHLKPIPQIVLNCCSTGLIIKHVKYLPKVLGRIAIRPSIPKQVKHHIISVILLLNIFIHPDLTKNVNGLDTKPLSDPVCQPRPTRHITNHLTDTKVLHIIPLLKRLDLTWAFTALRDIWASIHSVHLGFPIHGPVGPYFASGDADSGGNNTVRVWAVEVQPPPHLGYGC |
| NCBI Accession | NP_817110.1 |
|---|---|
| Location | 1102-1506 |
| Gene Name | ac3 |
| Protein Name | AC3 protein |
| Coding Region | ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAGGAATGGCGTTTTTACCTGGGACATAACAAATCCCCTCTATTTCGAAATCACCGACCACGACAAGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTTCGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAGATATCAAGTGCTCAAGTATTTAGATATGATAGGCGTTATTTCCATTAACACTGTCCTTCAAGCTGTTGATCATGTTGTGTACGATGTATTACTAAACACACTCCAAGTTACGGAGCAACATGCAATAAAATTCAACCTTTATTAA |
| Protein Sequence | MDSRTGELITAPQARNGVFTWDITNPLYFEITDHDKRPGNMNHDIITLQIRFNHNLRKALGIHKCFLNFKVWTTLRPQTGRFLRVFRYQVLKYLDMIGVISINTVLQAVDHVVYDVLLNTLQVTEQHAIKFNLY |
| NCBI Accession | NP_817111.1 |
|---|---|
| Location | 1247-1654 |
| Gene Name | ac2 |
| Protein Name | AC2 protein |
| Coding Region | ATGCCACCTTCATCGCCCTCCACGAGCCATTGTTCTCAAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAGGCGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAACCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAGGAATGGCGTTTTTACCTGGGACATAACAAATCCCCTCTATTTCGAAATCACCGACCACGACAAGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTTCGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACGGCCTCAGACTGGTCGTTTCTTAAGAGTATTTAG |
| Protein Sequence | MPPSSPSTSHCSQVPIKVQHRTAKTRAVRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSKEWRFYLGHNKSPLFRNHRPRQEAREHEPRHHHTPDTVQPQPSEGIGDSQVFSQLQGLDDLTASDWSFLKSI |
| NCBI Accession | NP_817112.1 |
|---|---|
| Location | 1563-2642 |
| Gene Name | ac1 |
| Protein Name | AC1 protein |
| Coding Region | ATGCCAAGAGCCGGTCGTTTTCAAATTAATGCCAAAAATTATTTCATAACCTATCCCCGATGCTCATTAACAAAAGAAGAGGCCCTTTCCCAATTACAAGCCCTTTCGTACCCGACGATTATCAAATTCATTAGGGTTTGCAGAGAACTACATCAGGATGGGGTGCCTCATCTCCATGTTCTCATCCAATTCGAAGGCAAGTTCCAATGTACCAACCCGAGATTCTTCGATCTCATTTCCCCATCCCGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGATGTCAAAGCTTACATTGAAAAGGGAGGGGAATTTCTTGACGCTGGACTTTTCCAAGTCGATGCCAGAAGTGCAAGGGGGGAGGGCCAACATTTAGCTCAGGTATATGCAGACGCGTTGAATGCTTCGTCTAAATCCGAGGCTCTTCAAATTATTAAAGAAAAAGATCCAAAGTCCTTTTTTTTACAGTTCCATAACATATCTGCTAACGCAGATAGAATCTTCCAGGCTCCGCCACAAACTTACGTTAGTCCGTTCTTATCATCATCTTTTACACAAGTCCCAGAAGACATAGAGGTATGGGTATCCGAAAATATATGCAGTCCCGCTGCGCGGCCATGGAGACCGATCAGTATTGTTCTAGAAGGTGATAGCCGAACCGGCAAAACAATGTGGGCTCGTTCACTGGGACCCCATAATTATCTTTGTGGACACCTGGATCTGTCTCCCAAGGTATATTCAAACGACGCATGGTACAACGTCATTGATGACGTCGACCCCCACTACCTCAAACACTTCAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAATACAAAATACGGGAAGCCAATTCAAATTAAAGGCGGCATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCATCATATAAAGAGTTTCTGGACGAGGAAAAGAACCAATCCCTTAAAGCCTGGGCTTTAAAGAATGCCACCTTCATCGCCCTCCACGAGCCATTGTTCTCAAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAG |
| Protein Sequence | MPRAGRFQINAKNYFITYPRCSLTKEEALSQLQALSYPTIIKFIRVCRELHQDGVPHLHVLIQFEGKFQCTNPRFFDLISPSRSTHFHPNIQGAKSSSDVKAYIEKGGEFLDAGLFQVDARSARGEGQHLAQVYADALNASSKSEALQIIKEKDPKSFFLQFHNISANADRIFQAPPQTYVSPFLSSSFTQVPEDIEVWVSENICSPAARPWRPISIVLEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKNQSLKAWALKNATFIALHEPLFSSAHQSPTPHSEDQGRQT |
| NCBI Accession | NP_817113.1 |
|---|---|
| Location | 2252-2485 |
| Gene Name | ac4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGGTGCCTCATCTCCATGTTCTCATCCAATTCGAAGGCAAGTTCCAATGTACCAACCCGAGATTCTTCGATCTCATTTCCCCATCCCGATCAACACATTTCCATCCGAACATTCAGGGAGCTAAATCATCGTCCGATGTCAAAGCTTACATTGAAAAGGGAGGGGAATTTCTTGACGCTGGACTTTTCCAAGTCGATGCCAGAAGTGCAAGGGGGGAGGGCCAACATTTAG |
| Protein Sequence | MGCLISMFSSNSKASSNVPTRDSSISFPHPDQHISIRTFRELNHRPMSKLTLKREGNFLTLDFSKSMPEVQGGRANI |
References More References in PubMed
| 1 |
Eni AO, et al. Ann Appl Biol. 2021 May;178(3):466-479. doi: 10.1111/aab.12647. Epub 2020 Oct 19. PMID: 34219746 |
|---|---|
| 2 |
De Bruyn A, et al. BMC Evol Biol. 2012 Nov 27;12:228. doi: 10.1186/1471-2148-12-228. PMID: 23186303 |
| 3 |
First Report of East African Cassava Mosaic Begomovirus in Nigeria. Ogbe FO, et al. Plant Dis. 1999 Apr;83(4):398. doi: 10.1094/PDIS.1999.83.4.398A. PMID: 30845599 |
| 4 |
First Report of East African Cassava Mosaic Begomovirus in Ghana. Offei SK, et al. Plant Dis. 1999 Sep;83(9):877. doi: 10.1094/PDIS.1999.83.9.877C. PMID: 30841053 |
| 5 |
Maruthi MN, et al. Arch Virol. 2004 Dec;149(12):2365-77. doi: 10.1007/s00705-004-0380-1. Epub 2004 Sep 10. PMID: 15375675 |
| 6 |
First Report of the Presence of East African Cassava Mosaic Virus in Cameroon. Fondong VN, et al. Plant Dis. 1998 Oct;82(10):1172. doi: 10.1094/PDIS.1998.82.10.1172B. PMID: 30856787 |
| 7 |
Kidulile CE, et al. J Phytopathol (1986). 2018 Oct;166(10):739-745. doi: 10.1111/jph.12725. Epub 2018 Aug 12. PMID: 31031544 |
| 8 |
Naseem S, et al. J Virol Methods. 2016 Jan;227:23-32. doi: 10.1016/j.jviromet.2015.10.001. Epub 2015 Oct 8. PMID: 26456453 |
| 9 |
The role of pathogen-mediated insect superabundance in the East African emergence of a plant virus. Donnelly R, et al. J Ecol. 2022 May;110(5):1113-1124. doi: 10.1111/1365-2745.13854. Epub 2022 Mar 13. PMID: 35910423 |
| 10 |
Fondong VN, et al. Virology. 2011 May 10;413(2):275-82. doi: 10.1016/j.virol.2011.02.024. Epub 2011 Mar 23. PMID: 21429548 |