East African cassava mosaic Malawi virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000912855.1 |
| Isolate | Malawi |
| Release date | 2015/2/22 |
| Submitter | Nawaz-ul-Rehman,M.S., Fauquet,C.M. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
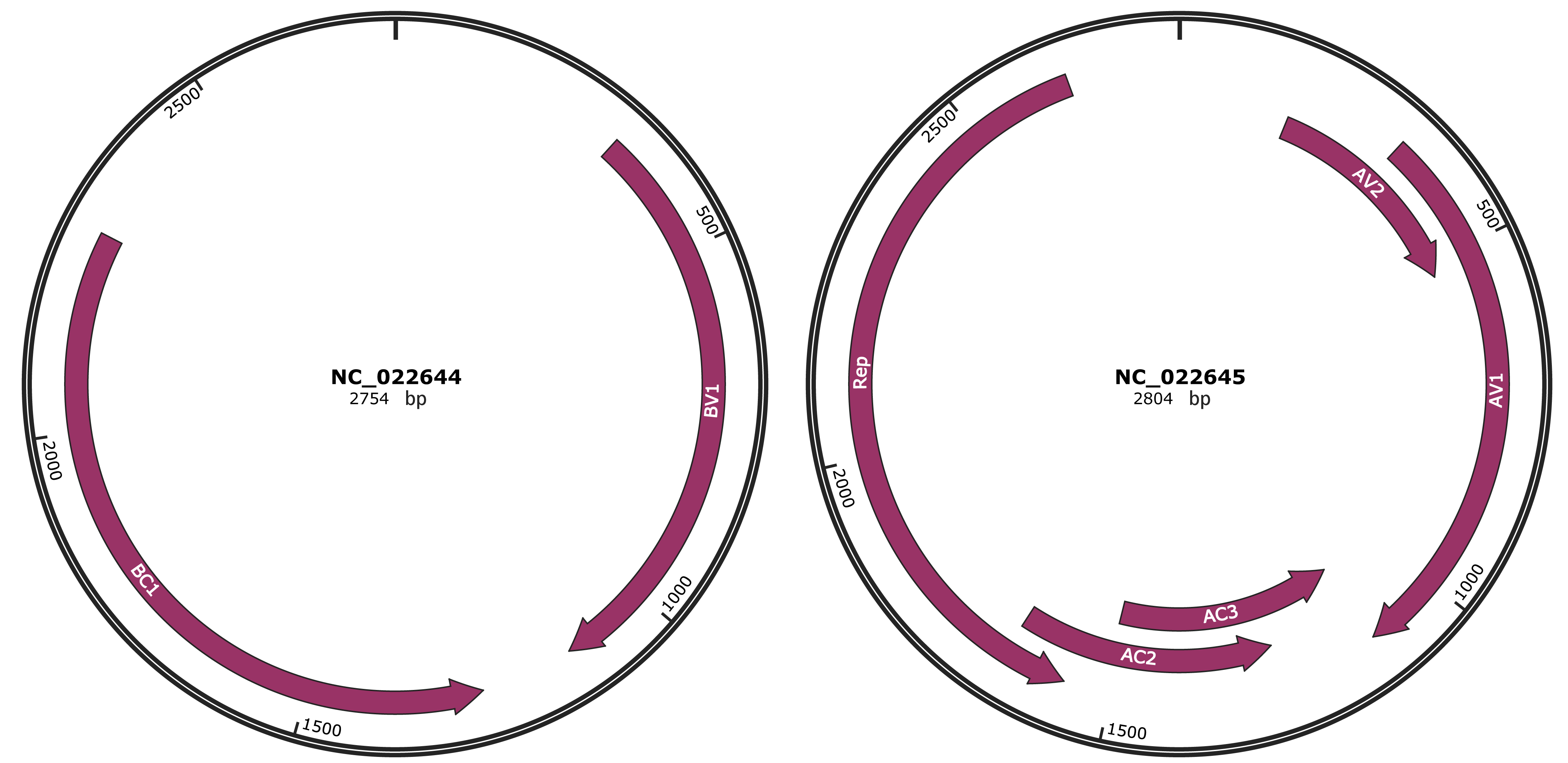
JBrowse
Genome
NC_022644
NC_022645
Gene Information
| NCBI Accession | YP_008719942.1 |
|---|---|
| Location | 324-1124 |
| Gene Name | BV1 |
| Protein Name | NSP |
| Coding Region | ATGTCTCCCGTTCGTCAATGCAAGATGTATTCGGTATACAGACGTGGGTATAAGACGCCGTATAGGAGTCCGTATGGCGCTCGTGGAACACCATATGTGAATCGTAAGACCTCTGGTAAACAGACGGCTAAATCTCGTGTATCGCGAAAGTTGGCGTATGAATCGCCAAAAGGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTGCCTTGAAGTTGCCGCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGCATCGATGGTAATGGGGGTAGGTCTGTGGATCATATAAAATTATTAAATTTGAGGGTTTCTGGGACCGTCAACGTCAGTCAATCCGGTGGTGATGACAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCGTGTCTTGTTGATAAGAAACCCTTCGTTCCAGATGGGGTCAGCATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTTTATGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGTTATCGCGTTATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCACATCCAGAAGCCTTTTAGTCTACGTCGAAGACTAAGTGGAGGGAAATATCCTATATGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGTAACTATAAAAATATAAATAAGAACGCTATACTCGTTAGTTATGTGTGGGTGTCGCTAAGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTTAATTACGTCGGCTGA |
| Protein Sequence | MSPVRQCKMYSVYRRGYKTPYRSPYGARGTPYVNRKTSGKQTAKSRVSRKLAYESPKGLYTRRSLEDIHNGAALKLPQQGDYTSYVTLPCRGIDGNGGRSVDHIKLLNLRVSGTVNVSQSGGDDNMGERTTMRGIFFMACLVDKKPFVPDGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEDHIQKPFSLRRRLSGGKYPIWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLSRTTCDVYSQFVLNYVG |
| NCBI Accession | YP_008719943.1 |
|---|---|
| Location | 1255-2274 |
| Gene Name | BC1 |
| Protein Name | MP |
| Coding Region | ATGCTTCCATGTCTACAAGACATTTTATCAACCTTGTTCTGCCTTTTATACATCTCTTCTCTCCGTTTCCTAACCCTTGTTTTTTTCATTCCTAGAATGGACAACCAATTCACCGTCACAGACAATAATTACATAAACAGCAAACGCACCGAGTACGCCTTAACCAACGATGCTGCACCAATCAATCTCCAATTTCCGAGCTCATTCGAGCAGGCGACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGCAACCAGGTCCCATTTAACGCAACTGGGTCGGTTATCGTAGAAATCCGAGACAATCGCGTCAGCCTTGAAGACGCAGCTCAAGCAGCATTCACTTTCCCAATAGCTTGCAACGTCGACCTCCACTACTTCTCTTCTACATATTTTTCGATTTCGGACCCCTCCCCTTGGAAAATAATGTACCGAGTCGAGGACTCCAACGTCGTAGAAGGCGTGAAATTCGCATCCATCAAAGCCAAGCTCCGATTATCATCGGCCAAACATTCCACAGACATACGTTTCAAACCCCCAACAATTAACATCTTATCCAAGGGATACACGAAAGACTGCATAGACTTTTGGTCTGTGGAAAAAGGAGAAACAAGACGGAGATTACTAAATCCAACTCCACATGCTCATAGTCCACGACCCATAGCCCACAGGCCCATCACCATCCTACCTGGAGAAACATGGGCAACTAAGTCTCAGATTGGGCTACCCAGCTCATCAGGCCCAACAAGGCTGGAACACTTTCGTTCACAGTCCATGAGAATGGACCCATCGACAATACCAACAGACTTAGACAACGACTCCACAGACTATCCTTACCAGAGACTACACAGATTACACACACCAGAGTTAGACCCAGGGGACTCGGTATCACAGGCCCAATCCGACTCAGTATCCAGAAAGGACCTCGAGACACTGCTTGAGAGTACCATCAACAAGTGCCTCATCAAGATCAAATCCGAAGCACCAAGGCCATTGTAA |
| Protein Sequence | MLPCLQDILSTLFCLLYISSLRFLTLVFFIPRMDNQFTVTDNNYINSKRTEYALTNDAAPINLQFPSSFEQATMRLKGRCMKIDHIIIEYRNQVPFNATGSVIVEIRDNRVSLEDAAQAAFTFPIACNVDLHYFSSTYFSISDPSPWKIMYRVEDSNVVEGVKFASIKAKLRLSSAKHSTDIRFKPPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPHAHSPRPIAHRPITILPGETWATKSQIGLPSSSGPTRLEHFRSQSMRMDPSTIPTDLDNDSTDYPYQRLHRLHTPELDPGDSVSQAQSDSVSRKDLETLLESTINKCLIKIKSEAPRPL |
| NCBI Accession | YP_008719944.1 |
|---|---|
| Location | 174-524 |
| Gene Name | AV2 |
| Protein Name | AV2 |
| Coding Region | ATGTGGGATCCATTGTTGAATGAGTTCCCCGAGTCTGTGCACGGTTTTCGCTGTATGCTTGCTATTAAATATTTGCAGGCTTTGGAGGAAACCTACGAGCCCAATACTTTGGGCCACGATCTAGTCCGTGATCTCATCTGTGTTATCCGAGCCCGTGATTATGTCGAAGCGACCCGCCGATATAATCATTTCCACTCCCGCCTCGAAGTGCGTCGAAGCTGCACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCATACCAACAAGCGACGATCATGGACGTTCCGGCCCATGTATCGAAAGCCCAGAATGTACAGAATGTACAGAAGTCCTGA |
| Protein Sequence | MWDPLLNEFPESVHGFRCMLAIKYLQALEETYEPNTLGHDLVRDLICVIRARDYVEATRRYNHFHSRLEVRRSCTSTARSAAVLLSPLSKAYQQATIMDVPAHVSKAQNVQNVQKS |
| NCBI Accession | YP_008719945.1 |
|---|---|
| Location | 334-1110 |
| Gene Name | AV1 |
| Protein Name | CP |
| Coding Region | ATGTCGAAGCGACCCGCCGATATAATCATTTCCACTCCCGCCTCGAAGTGCGTCGAAGCTGCACTTCGACAGCCCGTTCAGCAGCCGTGCTGCTGTCCCCATTGTCCAAGGCATACCAACAAGCGACGATCATGGACGTTCCGGCCCATGTATCGAAAGCCCAGAATGTACAGAATGTACAGAAGTCCTGATGTTCCTCGAGGATGTGAAGGCCCATGTAAGGTACAGTCCTATGAACAGAGAGACGATGTTAAGCACACCGGTGCTGTGCGTTGTGTTAGTGATGTTACTCGTGGTTCGGGTATTACTCATAGGGTAGGGAAGAGATTTTGTGTTAAGTCAATATATGTGTTAGGAAAGATCTGGATGGATGAAAACATCAAGAAGCAAAACCATACTAACCAGGTGATGTTCTTCTTAGTCCGTGACAGAAGGCCTTATGGCACAAGCCCCATGGACTTTGGACAGGTTTTTAATATGTTTGATAATGAGCCCAGTACAGCTACTATTAAGAATGATTTGCGAGATAGGTTCCAAGTGTTGCGGAAATTCCATGCCACTGTGGTAGGTGGTCCCTCAGGCATGAAGGAGCAGGCGTTGATTAAGAGGTTTTTTAAGGTGAATAATCATGTTGTGTATAATCACCAGGAGGCAGCGAAGTATGAGAATCATACAGAAAATGCGTTGTTGTTGTATATGGCATGTACGCATGCCTCTAATCCAGTGTATGCTACGCTTAAAATACGCATCTATTTTTATGATGCAGTAACAAATTAA |
| Protein Sequence | MSKRPADIIISTPASKCVEAALRQPVQQPCCCPHCPRHTNKRRSWTFRPMYRKPRMYRMYRSPDVPRGCEGPCKVQSYEQRDDVKHTGAVRCVSDVTRGSGITHRVGKRFCVKSIYVLGKIWMDENIKKQNHTNQVMFFLVRDRRPYGTSPMDFGQVFNMFDNEPSTATIKNDLRDRFQVLRKFHATVVGGPSGMKEQALIKRFFKVNNHVVYNHQEAAKYENHTENALLLYMACTHASNPVYATLKIRIYFYDAVTN |
| NCBI Accession | YP_008719946.1 |
|---|---|
| Location | 1107-1511 |
| Gene Name | AC3 |
| Protein Name | REn |
| Coding Region | ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAAGAATGGCGTTTTTACTTGGGAAATAACAAATCCCCTCTATTTCGCAATCACCAACCACGACAAGAGACCAGGGAACATGCACCACGATATCATCACACTCCAGATACGGTTCAACCACAACATCAGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACAGCCTCCGACTGGTCTTTTCTTAAAAGTATTTAGATATCAAGTGCTCAAATATTTAAATATGATAGGAGTTATTTCCATTAACACTGTACTTAGAGCTGTGATCATGTCCTGTACAATGTATTACTGGCCACACACTCAAGTTACGGAGCAACATGAAATAAAATTCAACCTTTATTAA |
| Protein Sequence | MDSRTGELITAPQAKNGVFTWEITNPLYFAITNHDKRPGNMHHDIITLQIRFNHNIRKALGIHKCFLNFKVWTTLQPPTGLFLKVFRYQVLKYLNMIGVISINTVLRAVIMSCTMYYWPHTQVTEQHEIKFNLY |
| NCBI Accession | YP_008719947.1 |
|---|---|
| Location | 1252-1659 |
| Gene Name | AC2 |
| Protein Name | TrAP |
| Coding Region | ATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCAAGTGCCTATCAAAGTCCAACACCGCACCGTGAAGAACAGGGCACTCAGACGTAGGAGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAATCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAAGAATGGCGTTTTTACTTGGGAAATAACAAATCCCCTCTATTTCGCAATCACCAACCACGACAAGAGACCAGGGAACATGCACCACGATATCATCACACTCCAGATACGGTTCAACCACAACATCAGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAAGGTCTGGACGACCTTACAGCCTCCGACTGGTCTTTTCTTAAAAGTATTTAG |
| Protein Sequence | MPPSSPSTSHCSQVPIKVQHRTVKNRALRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSKEWRFYLGNNKSPLFRNHQPRQETREHAPRYHHTPDTVQPQHQEGIGDSQVFSQLQGLDDLTASDWSFLKSI |
| NCBI Accession | YP_008719948.1 |
|---|---|
| Location | 1568-2647 |
| Protein Name | Rep |
| Coding Region | ATGCCAAGAGCAGGTCGTTTTCAAATCAATGCCAAAAATTATTTCATAACATATCCCCGATGCTCATTAACAAAAGAAGAGGCCCTTTCCCAATTACAAGCCCTTTCTTACCCGACGAATATCAAATTCATTAGGGTTTGCAGAGAACTACATCAGGATGGGGTGCCTCATCTCCATGTTCTCATTCAATTCGAAGGTAAATTCCAATGTACCAACCCGAGATTTTTCGATCTCATTTCCCCATCCCGATCAACACATTTCCATCCGAACATTGAGGGAGCTAAATCATCGTCCGATGTCAAAGCTTACATTGAAAAGGGAGGGGAATTTCTTGACGATGGAGTTTTCCAAGTCGATGCCAGAAGTGCAAGGGGTGAGGGCCAGCATTTAGCTCAGGTATATGCAGAAGCGTTGAATGCTTCTTCTAAATCAGAAGCTCTTCAAATTATTAAAGAAAAAGATCCGAAGTCTTTTTTTTTACAGTTCCATAACATATCTGCTAACGCAGATAGAATCTTCCAGCTCCCGCCACAAACTTATGTAAGTCCGTTTTTATCATCCTCATTTACACACGTCCCAGACGAAATAGAAATATGGGTATCCGAAAATATATGCAGTCCCGCTGCGCGGCCATGGAGACCGATCAGTATTGTTCTAGAAGGCGATAGTAGGACAGGGAAGACGATGTGGGCCCGATCTCTGGGACCACACAACTACTTGTGTGGACATTTGGATCTTAGTCCAAAGGTCTACAGCAACGACGCCTGGTACAACGTCATTGATGACGTCGACCCACACTACCTCAAGCACTTCAAAGAATTTATGGGGGCCCAAAGGGACTGGCAAAGCAATACAAAGTACGGGAAGCCGATTCAAATTAAAGGCGGCATTCCCACTATCTTCCTCTGCAATCCAGGACCAACATCATCATATAAAGAGTTTCTGGAAGAGGAAAAGAACCAATCCCTTAAAGCCTGGGCTTTAAAGAATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCAAGTGCCTATCAAAGTCCAACACCGCACCGTGAAGAACAGGGCACTCAGACGTAG |
| Protein Sequence | MPRAGRFQINAKNYFITYPRCSLTKEEALSQLQALSYPTNIKFIRVCRELHQDGVPHLHVLIQFEGKFQCTNPRFFDLISPSRSTHFHPNIEGAKSSSDVKAYIEKGGEFLDDGVFQVDARSARGEGQHLAQVYAEALNASSKSEALQIIKEKDPKSFFLQFHNISANADRIFQLPPQTYVSPFLSSSFTHVPDEIEIWVSENICSPAARPWRPISIVLEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLEEEKNQSLKAWALKNATFITLHEPLFSSAYQSPTPHREEQGTQT |
References More References in PubMed
| 1 |
First Report of East African Cassava Mosaic Begomovirus in Nigeria. Ogbe FO, et al. Plant Dis. 1999 Apr;83(4):398. doi: 10.1094/PDIS.1999.83.4.398A. PMID: 30845599 |
|---|---|
| 2 |
Zhou X, et al. J Gen Virol. 1998 Nov;79 ( Pt 11):2835-40. doi: 10.1099/0022-1317-79-11-2835. PMID: 9820161 |
| 3 |
Tairo F, et al. Afr J Biotechnol. 2017;16(36). doi: 10.5897/AJB2017.16130. Epub 2017 Sep 6. PMID: 33281889 |
| 4 |
Chen W, et al. Insect Biochem Mol Biol. 2019 Jul;110:112-120. doi: 10.1016/j.ibmb.2019.05.003. Epub 2019 May 15. PMID: 31102651 |
| 5 |
Aloyce RC, et al. J Virol Methods. 2013 Apr;189(1):148-56. doi: 10.1016/j.jviromet.2012.10.007. Epub 2012 Nov 19. PMID: 23174160 |
| 6 |
A method for generating virus-free cassava plants to combat viral disease epidemics in Africa. Maruthi MN, et al. Physiol Mol Plant Pathol. 2019 Jan;105:77-87. doi: 10.1016/j.pmpp.2018.09.002. PMID: 31007376 |
| 7 |
Mulenga RM, et al. Plant Dis. 2016 Jul;100(7):1379-1387. doi: 10.1094/PDIS-10-15-1170-RE. Epub 2016 Apr 8. PMID: 30686191 |
| 8 |
A New Tomato leaf curl virus from Mayotte. Lett JM, et al. Plant Dis. 2004 Jun;88(6):681. doi: 10.1094/PDIS.2004.88.6.681B. PMID: 30812598 |
| 9 |
Hong YG, et al. J Gen Virol. 1993 Nov;74 ( Pt 11):2437-43. doi: 10.1099/0022-1317-74-11-2437. PMID: 8245859 |
| 10 |
First Molecular Identification of a Begomovirus Isolated from Tomato in Madagascar. Delatte H, et al. Plant Dis. 2002 Dec;86(12):1404. doi: 10.1094/PDIS.2002.86.12.1404C. PMID: 30818457 |