East African cassava mosaic Kenya virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000882315.1 |
| Isolate | Kenya:Machakos, Mitaboni/Ngiini |
| Release date | 2015/2/22 |
| Submitter | Bull,S.E., Briddon,R.W., Sserubombwe,W.S., Ngugi,K., Markham,P.G., Stanley,J. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
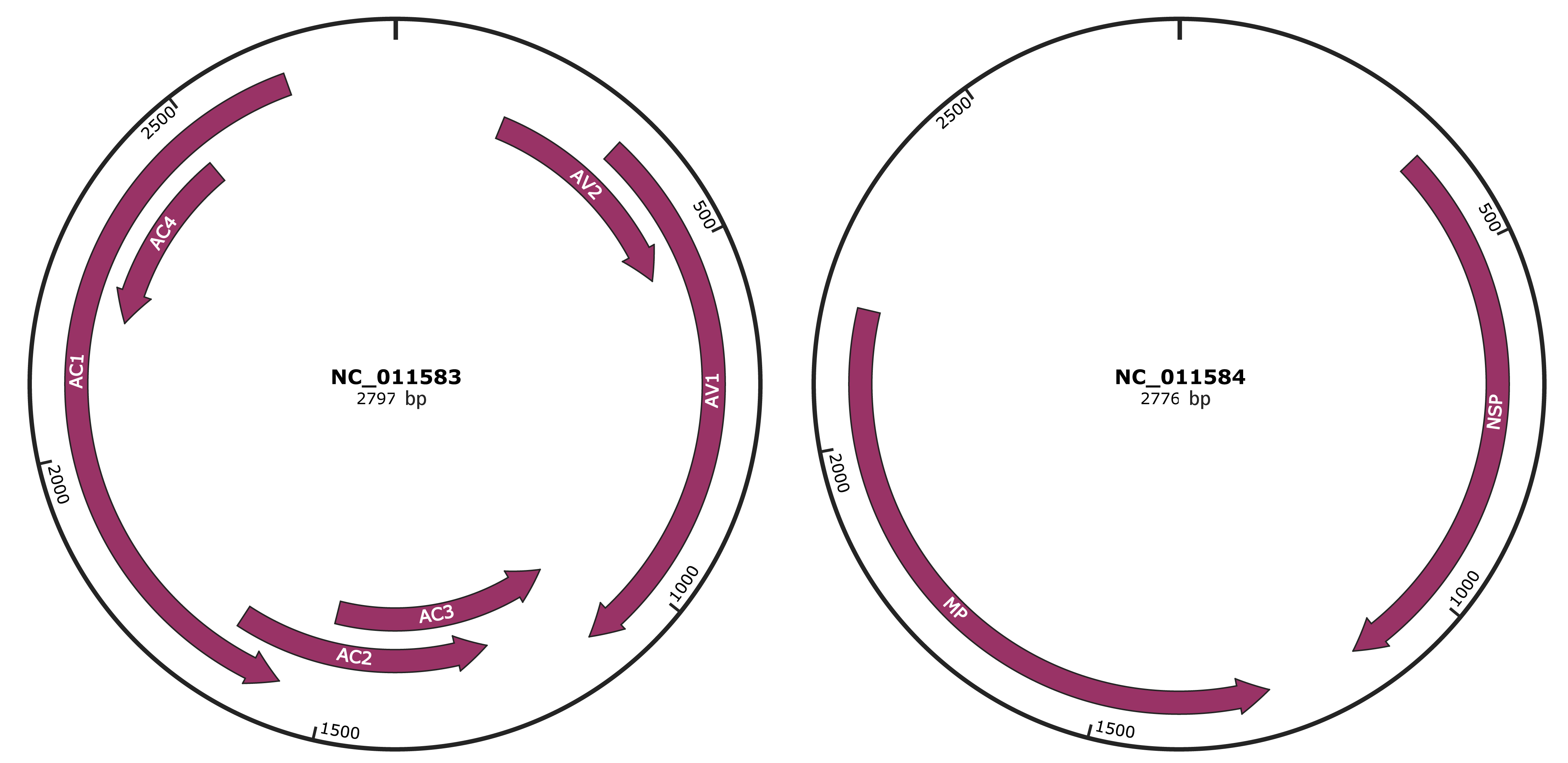
JBrowse
Genome
NC_011583
NC_011584
Gene Information
| NCBI Accession | YP_002317394.1 |
|---|---|
| Location | 174-530 |
| Gene Name | AV2 |
| Protein Name | AV2 protein |
| Coding Region | ATGTGGGATCCATTGTTGAACGACTTTCCCGAAACCGTTCACGGTTTCCGTTCTATGCTTGCTGTTAAATACCTGTTACATCTGGAACAGGAATACGACCGCGGTACTGTCGGGGCTGAGTATATACGGGATCTAATAGGGGTTCTACGGTGTAAGAGTTATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGACCCATGTATCGGAAGCCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAA |
| Protein Sequence | MWDPLLNDFPETVHGFRSMLAVKYLLHLEQEYDRGTVGAEYIRDLIGVLRCKSYVEATRRYNNLNTRIQGAEEAELRQPIHEPCCCPHCPRHQKQNMGQQTHVSEAQDVQNVSKPRCP |
| NCBI Accession | YP_002317395.1 |
|---|---|
| Location | 334-1107 |
| Gene Name | AV1 |
| Protein Name | AV1 protein |
| Coding Region | ATGTCGAAGCGACCAGGAGATATAATAATCTCAACACCCGTATCCAAGGTGCGGAGGAGGCTGAACTTCGACAGCCCATACACGAACCGTGTTGTTGCCCCCACTGTCCGCGTCACCAGAAGCAAAATATGGGCCAACAGACCCATGTATCGGAAGCCCAAGATGTACAGAATGTATCGAAGCCCAGATGTCCCTAAGGGCTGTGAAGGCCCATGTAAGGTTCAGTCCTATGAACAGAGGGATGATGTTAAGCACACTGGTATGGTCCGATGTGTCAGTGATGTTACTCGTGGGTCAGGCATTACCCATAGAGTCGGGAAGAGGTTTTGTGTTAAGTCCATATATATATTGGGCAAGATCTGGATGGATGAGAATGTCAAGAAGCAAAATCACACGAACCATGTGATGTTCTTCCTCGTTCGAGATAGAAGGCCGTATGGTCCGAGTCCTCAAGATTTTGGGCAAGTGTTCAACATGTTTGATAATGAACCAACTACTGCAACTGTGAAGAATGATCTTAGGGACCGGTATCAGGTGTTACGTAAATTCTATGCGACTGTGGTTGGTGGACCCTCTGGGATGAAGGAACAAGCTCTGGTTAAGAGGTTTTTTAGGATCAATAATCATGTAGTGTATAATCATCAGGAACAGGCCAAGTATGAGAATCATACTGAGAATGCGTTGTTATTGTATATGGCATGTACACATGCCGCTAATCCTGTGTACGCTACGCTGAAAATACGCATCTATTTTTATGATGCAGTGACAAATTAA |
| Protein Sequence | MSKRPGDIIISTPVSKVRRRLNFDSPYTNRVVAPTVRVTRSKIWANRPMYRKPKMYRMYRSPDVPKGCEGPCKVQSYEQRDDVKHTGMVRCVSDVTRGSGITHRVGKRFCVKSIYILGKIWMDENVKKQNHTNHVMFFLVRDRRPYGPSPQDFGQVFNMFDNEPTTATVKNDLRDRYQVLRKFYATVVGGPSGMKEQALVKRFFRINNHVVYNHQEQAKYENHTENALLLYMACTHAANPVYATLKIRIYFYDAVTN |
| NCBI Accession | YP_002317396.1 |
|---|---|
| Location | 1104-1508 |
| Gene Name | AC3 |
| Protein Name | AC3 protein |
| Coding Region | ATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAGGAATGGCGTTTTTACCTGGGACATAACAAATCCCCTCTATTTCGAAATCACCAACCACGACAAGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTCCGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAGGGTCTGGACGACCTTACGGCCTCAGACTGGTCTTTTCTTAAGAGTATTTAGATATCAAATGCTCAAGTATTTGGATATGATAGGCGTTATTTCCATTAACACTGTACTTCAAGCTGTTGATCATGTTATGTACGATGTATTACTAAACACGCTCCAAGTTACGGAGCAACATGCAATAAAATTCAACCTTTATTAA |
| Protein Sequence | MDSRTGELITAPQARNGVFTWDITNPLYFEITNHDKRPGNMNHDIITLQIRFNHNLRKALGIHKCFLNFRVWTTLRPQTGLFLRVFRYQMLKYLDMIGVISINTVLQAVDHVMYDVLLNTLQVTEQHAIKFNLY |
| NCBI Accession | YP_002317397.1 |
|---|---|
| Location | 1249-1656 |
| Gene Name | AC2 |
| Protein Name | AC2 protein |
| Coding Region | ATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCTAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAGGCGGGTAGACCTCGAATGCGGCTGCTCGTTCTATCTCCATATCGACTGCATCAACCATGGATTCTCGCACAGGGGAACTCATCACTGCGCCTCAAGCAAGGAATGGCGTTTTTACCTGGGACATAACAAATCCCCTCTATTTCGAAATCACCAACCACGACAAGAGGCCAGGGAACATGAACCACGACATCATCACACTCCAGATACGGTTCAACCACAACCTCCGGAAGGCATTGGGGATTCACAAGTGTTTTCTCAACTTCAGGGTCTGGACGACCTTACGGCCTCAGACTGGTCTTTTCTTAAGAGTATTTAG |
| Protein Sequence | MPPSSPSTSHCSLVPIKVQHRTAKTRAVRRRRVDLECGCSFYLHIDCINHGFSHRGTHHCASSKEWRFYLGHNKSPLFRNHQPRQEAREHEPRHHHTPDTVQPQPPEGIGDSQVFSQLQGLDDLTASDWSFLKSI |
| NCBI Accession | YP_002317398.1 |
|---|---|
| Location | 1565-2644 |
| Gene Name | AC1 |
| Protein Name | AC1 protein |
| Coding Region | ATGCCAAGGGCTGGTCGTTTTAGCATCAAAGCCAAAAACTATTTCCTAACATATCCCAAATGCTCTCTATCCAAAGAGGAGGCATTGGATCAAATCCGACAACTCCAAACCCCAACAAATAAATTGTTCATCAAGATCTGCAGAGAACTCCATGAAAATGGGGAACCTCATCTGCATGCCCTCATTCAGTTCGAGGGCAAGTACAATTGTACCAACCATCGATTCTTCGACCTCATATCCCCATCCCGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCCAGTCCTATATGGACAAGGACGGAGACACCATCCAATGGGGCACGTTTCAGATCGACGGACGATCTGCTCGAGGAGGACAACAATCAGCCAATGACGCTTACGCCAAGGCTCTTAACTCAGCAAATAAGTCAGAGGCTCTTAATGTAATACGCGAACTAGCTCCAAAAGATTTTGTTTTACAGTTTCATAATTTACATAGCAATTTAGATAGGATTTTTCAAGAGCCTCTGACTCCTTATGTTTCTCCATTTCTTTCATCTTCTTTCACTAACGTTCCTGAGGAACTTGAAGATTGGGTTTCCGAGAACGTGATGGGTTCCGCTGCGCGGCCATGGAGACCTACTAGTATCGTCATCGAGGGCGATAGTAGGACGGGGAAGACGATGTGGGCCCGCTCTTTGGGTCCACACAACTACTTGTGTGGACACCTGGATCTTAGTCCAAAGGTCTACAGCAACGACGCCTGGTACAACGTCATTGATGACGTCGACCCCCACTACCTCAAACACTTCAAAGAATTCATGGGGGCCCAAAGGGACTGGCAAAGCAATACAAAGTACGGGAAGCCGATTCAAATTAAAGGCGGCATTCCCACTATCTTCCTCTGCAATCCGGGCCCAACATCATCATATAAAGAGTTTCTGGACGAGGAAAAGAACCAGTCCCTTAAAGCCTGGGCTTTAAAGAATGCCACCTTCATCACCCTCCACGAGCCATTGTTCTCTAGTGCCCATCAAAGTCCAACACCGCACAGCGAAGACCAGGGCCGTCAGACGTAG |
| Protein Sequence | MPRAGRFSIKAKNYFLTYPKCSLSKEEALDQIRQLQTPTNKLFIKICRELHENGEPHLHALIQFEGKYNCTNHRFFDLISPSRSAHFHPNIQGAKSSSDVQSYMDKDGDTIQWGTFQIDGRSARGGQQSANDAYAKALNSANKSEALNVIRELAPKDFVLQFHNLHSNLDRIFQEPLTPYVSPFLSSSFTNVPEELEDWVSENVMGSAARPWRPTSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNVIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPIQIKGGIPTIFLCNPGPTSSYKEFLDEEKNQSLKAWALKNATFITLHEPLFSSAHQSPTPHSEDQGRQT |
| NCBI Accession | YP_002317399.1 |
|---|---|
| Location | 2197-2487 |
| Gene Name | AC4 |
| Protein Name | AC4 protein |
| Coding Region | ATGGGGAACCTCATCTGCATGCCCTCATTCAGTTCGAGGGCAAGTACAATTGTACCAACCATCGATTCTTCGACCTCATATCCCCATCCCGGTCAGCACATTTCCATCCAAACATTCAGGGAGCTAAATCAAGCTCCGACGTCCAGTCCTATATGGACAAGGACGGAGACACCATCCAATGGGGCACGTTTCAGATCGACGGACGATCTGCTCGAGGAGGACAACAATCAGCCAATGACGCTTACGCCAAGGCTCTTAACTCAGCAAATAAGTCAGAGGCTCTTAATGTAA |
| Protein Sequence | MGNLICMPSFSSRASTIVPTIDSSTSYPHPGQHISIQTFRELNQAPTSSPIWTRTETPSNGARFRSTDDLLEEDNNQPMTLTPRLLTQQISQRLLM |
| NCBI Accession | YP_002317400.1 |
|---|---|
| Location | 357-1133 |
| Gene Name | NSP |
| Protein Name | BV1 |
| Coding Region | ATGTATTCTGTTTACAGACGTGGGTATAAGACTCCGTATAGGAGTCCGTATGGCGCTCGTGTAACACCATATGTTTATCGTAAGACTGCTGTTAAACAGACGTCTAAATCTCGTGTACCGCGAAAGTTGGCGTATGAATCGCCAAAATGTCTATATACGCGACGCTCATTGGAGGATATCCATAATGGGGCTTCCTTAAAGTTACCTCAACAGGGGGATTATACGTCCTACGTGACACTCCCATGTCGAGGTATCGATGGTAATGGGGGAAGGTCTGTTGATCATATAAAATTATTAAGCTTGAGGGTTTCGGGGACCGTCAACGTCAGTCAATGCGGTGGTGATGATAATATGGGAGAGAGAACGACCATGAGGGGTATTTTTTTCATGGCTTGTCTTGTTGATAAGAAACCTTTCGTTCCAGAGGGGGTGAGTATATTGCCGACGTTTAATGAGTTGTTCGGGGAATATGAATCCGTGTATGGCATGCCTAGGTTGAAGGAAAACGTCCGTCACCGTTATCGCGTGATTGGGACGTCGAAATTATATATAACGACCGATGAAGATCACATCCAGAAGCCATTTAGTCTACGTCGAAGATTAAGTGGAGGGAAATATCCTATGTGGTCGTCGTTCAAGGATGTGGATAATAGTAGTACAGGTGGGAACTATAAAAATATAAATAAGAACGCTATACTAGTTAGTTATGTGTGGGTATCGCTATGTCGGACCACGTGTGATGTGTATTCGCAGTTTGTACTTAATTACGTCGGTTGA |
| Protein Sequence | MYSVYRRGYKTPYRSPYGARVTPYVYRKTAVKQTSKSRVPRKLAYESPKCLYTRRSLEDIHNGASLKLPQQGDYTSYVTLPCRGIDGNGGRSVDHIKLLSLRVSGTVNVSQCGGDDNMGERTTMRGIFFMACLVDKKPFVPEGVSILPTFNELFGEYESVYGMPRLKENVRHRYRVIGTSKLYITTDEDHIQKPFSLRRRLSGGKYPMWSSFKDVDNSSTGGNYKNINKNAILVSYVWVSLCRTTCDVYSQFVLNYVG |
| NCBI Accession | YP_002317401.1 |
|---|---|
| Location | 1262-2185 |
| Gene Name | MP |
| Protein Name | BC1 |
| Coding Region | ATGGACAACCAATTCACCGTCACAGACAATAATTACATCAACAGCAAACGCACAGAGTACGCATTAACCAACGATGCTGCACCAATCAATCTCCAATTTCCGAGCTCATTCGAGCAGGCGACCATGCGACTCAAAGGCCGATGTATGAAAATCGACCACATTATAATTGAATACCGAAACCAGGTCCCATTTAACGCAATTGGGTCGGTTATCGTAGAAATCAGAGACAATCGCGTCAGCCTTGAGGACGCTGCTCAAGCAGCATTCACTTTCCCAATAGCTTGCAACGTAGACCTCCACTACTTCTCTTCTACATATTTTTCGATTTCAGAACCCTCCCCTTGGAGAATCATGTACAGAGTCGAAGACTCAAACGTCATAGAAGGCGTGAAATTCGCATCCATAAAGGCCAAGCTCCGATTATCATCGGCCAAACATTCCACGGACATACGTTTCAAATCCCCAACAATTAACATCTTATCCAAGGGATACACAAAGGATTGCATAGACTTCTGGTCCGTGGAAAAAGGAGAAACACGACGGAGATTACTAAATCCAACTCCAACTGCTCATAGTCAACGACCCATAACCCACAGGCCCATCACCATTCTTCCTGGCGAAACATGGGCCACAAAGTCTCAGATTGGGCTACCAAGCTCATCCGGCCCAGCAAGGCTGGAACACTTTCGTTCACAGTCCATGAGAATGGACCCATCGACAACACCGACGGACTTAGACAACGACTCCACAGAATATCCTTACCAGACACTACACAGATTACACACACCCGAATTGGACCCAGGGGACTCGGTATCACAGACCCCATCCGACTCAGTATCAAGAAAGGACCTCGAGACACTGCTTGAGAGTACCATAAACAAGTGTCTCATCAAAATAAAATCCGAGGCACCAAGGCAATTGTAA |
| Protein Sequence | MDNQFTVTDNNYINSKRTEYALTNDAAPINLQFPSSFEQATMRLKGRCMKIDHIIIEYRNQVPFNAIGSVIVEIRDNRVSLEDAAQAAFTFPIACNVDLHYFSSTYFSISEPSPWRIMYRVEDSNVIEGVKFASIKAKLRLSSAKHSTDIRFKSPTINILSKGYTKDCIDFWSVEKGETRRRLLNPTPTAHSQRPITHRPITILPGETWATKSQIGLPSSSGPARLEHFRSQSMRMDPSTTPTDLDNDSTEYPYQTLHRLHTPELDPGDSVSQTPSDSVSRKDLETLLESTINKCLIKIKSEAPRQL |
References More References in PubMed
| 1 |
Khan AJ, et al. Virus Genes. 2013 Feb;46(1):195-8. doi: 10.1007/s11262-012-0838-2. Epub 2012 Oct 20. PMID: 23085885 |
|---|---|
| 2 |
Kidulile CE, et al. J Phytopathol (1986). 2018 Oct;166(10):739-745. doi: 10.1111/jph.12725. Epub 2018 Aug 12. PMID: 31031544 |
| 3 |
First Report of East African Cassava Mosaic Begomovirus in Nigeria. Ogbe FO, et al. Plant Dis. 1999 Apr;83(4):398. doi: 10.1094/PDIS.1999.83.4.398A. PMID: 30845599 |
| 4 |
Zhou X, et al. J Gen Virol. 1998 Nov;79 ( Pt 11):2835-40. doi: 10.1099/0022-1317-79-11-2835. PMID: 9820161 |
| 5 |
De Bruyn A, et al. BMC Evol Biol. 2012 Nov 27;12:228. doi: 10.1186/1471-2148-12-228. PMID: 23186303 |
| 6 |
Genetic diversity and phylogeography of cassava mosaic viruses in Kenya. Bull SE, et al. J Gen Virol. 2006 Oct;87(Pt 10):3053-3065. doi: 10.1099/vir.0.82013-0. PMID: 16963765 |
| 7 |
Kyallo M, et al. Arch Virol. 2017 May;162(5):1393-1396. doi: 10.1007/s00705-016-3217-9. Epub 2017 Jan 9. PMID: 28070648 |
| 8 |
Cassava begomovirus species diversity changes during plant vegetative cycles. Dye AE, et al. Front Microbiol. 2023 May 25;14:1163566. doi: 10.3389/fmicb.2023.1163566. eCollection 2023. PMID: 37303798 |
| 9 |
Tairo F, et al. Afr J Biotechnol. 2017;16(36). doi: 10.5897/AJB2017.16130. Epub 2017 Sep 6. PMID: 33281889 |
| 10 |
Differential response of cassava genotypes to infection by cassava mosaic geminiviruses. Kuria P, et al. Virus Res. 2017 Jan 2;227:69-81. doi: 10.1016/j.virusres.2016.09.022. Epub 2016 Sep 29. PMID: 27693919 |