Ageratum enation virus
Basic Information
| Genus | Begomovirus |
|---|---|
| NCBI Assembly | GCF_000859025.1 |
| Isolate | Nepal |
| Release date | 2015/2/13 |
| Submitter | Briddon,R.W., Bull,S.E., Markham,P.G. |
| Host | |
| Vector | |
| Download | Genome |GFF3 |PEP |CDS |
Genomic Organization
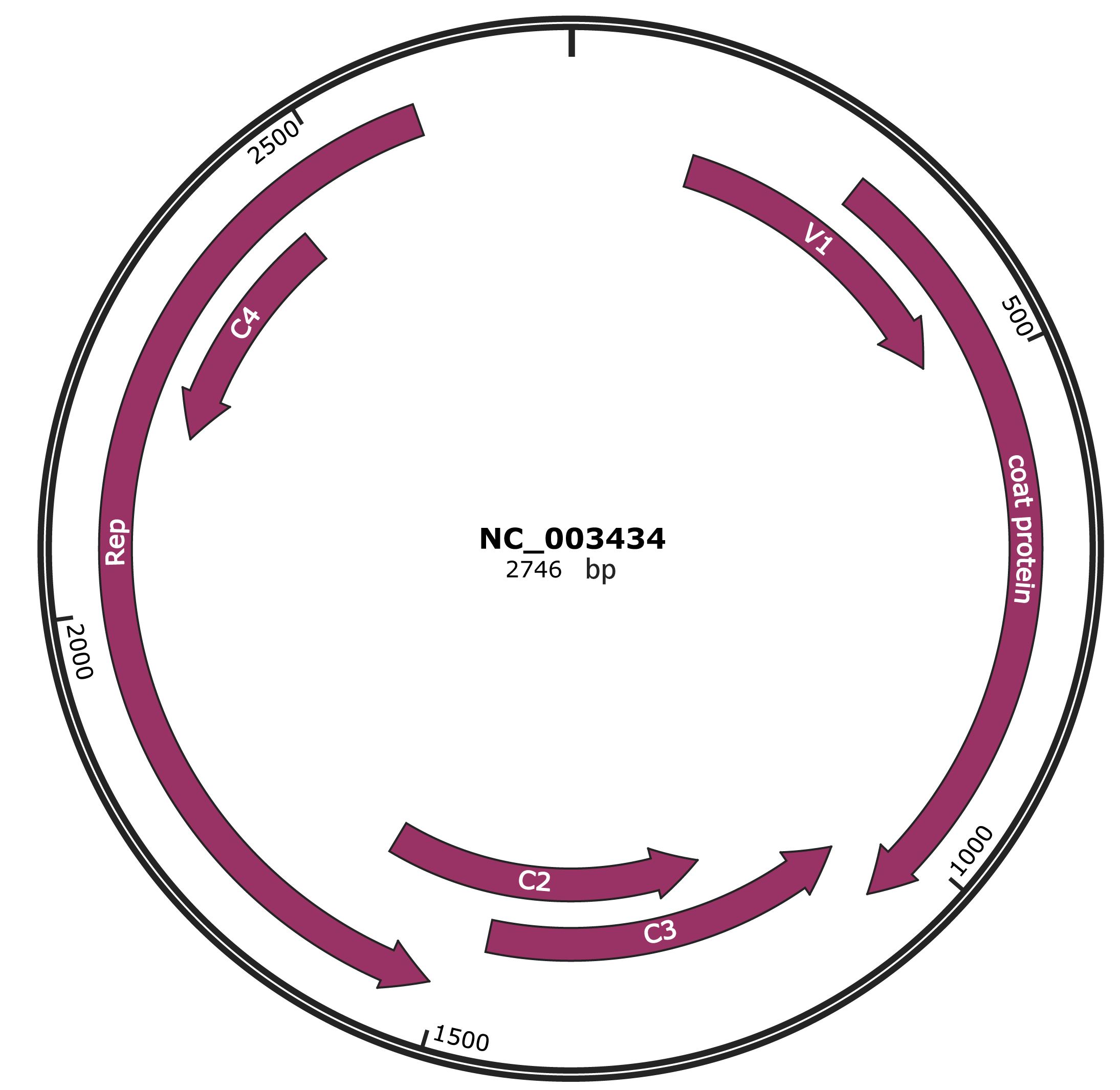
JBrowse
Genome
NC_003434
Gene Information
| NCBI Accession | NP_598186.1 |
|---|---|
| Location | 133-480 |
| Gene Name | V1 |
| Protein Name | V1 protein |
| Coding Region | ATGTGGGATCCATTAGTAAACGAGTTTCCCGAAACCGTTCACGGTTTTAGATGTATGTTAGCAGTTAAATATCTGCAGTTAGTAGAGAAGACTTATTCGCCTGACACATTAGGGCACGATTTAATTAGGGATTTAATTTCAGTTATTAGGGCTAGAAATTATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGGACGCCGACGTCTCAACTTCGACAGCCCATATGTGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAGAGCATGGGCGAACAGGCCCATGAACAGAAAACCCAGGATGTACAGGATGTACAGAAGTCCTGA |
| Protein Sequence | MWDPLVNEFPETVHGFRCMLAVKYLQLVEKTYSPDTLGHDLIRDLISVIRARNYVEATSRYNHFHARFEGTPTSQLRQPICEPCCCPHCPRHQSKSMGEQAHEQKTQDVQDVQKS |
| NCBI Accession | NP_598187.1 |
|---|---|
| Location | 293-1063 |
| Gene Name | coat protein |
| Protein Name | coat protein |
| Coding Region | ATGTCGAAGCGACCAGCAGATATAATCATTTCCACGCCCGCTTCGAAGGGACGCCGACGTCTCAACTTCGACAGCCCATATGTGAGCCGTGCTGCTGCCCCCATTGTCCGCGTCACCAAAGCAAGAGCATGGGCGAACAGGCCCATGAACAGAAAACCCAGGATGTACAGGATGTACAGAAGTCCTGATGTCCCTAGAGGATGTGAAGGTCCATGTAAGGGCCAGTCTTTTGAGTCTAGACATGACATTCAGCATATAGGTAAAGTTATGTGTGTCAGTGATGTTACGCGTGGAACTGGGCTGACTCATCGAGTGGGTAAAAGGTTTTGTGTTAAATCCGTTTATGTCTTGGGTAAGATCTGGATGGATGAAAATATTAAGACCAAGAACCACACTAACAGTGTTATGTTTTTTTTAGTTAGGGATCGTAGGCCTGTCGATAAACCTCAAGATTTTGGAGAGGTTTTTAACATGTTTGATAATGAGCCCAGTACGGCTACTGTGAAGAATGTTCATCGTGATAGGTATCAAGTGCTTCGGAAATGGCATGCAACTGTTACGGGTGGACAATATGCGTCAAAGGAACAAGCTCTTGTGAAGAAGTTTGTTAGGGTTAATAATTATGTTGTGTATAATCAGCAAGAAGCTGGCAAGTATGAGAATCATTCTGAGAATGCGTTAATGTTGTATATGGCATGTACTCATGCCTCTAACCCAGTGTATGCTACTTTGAAGATACGGATCTATTTCTATGATTCTGTAACAAATTAA |
| Protein Sequence | MSKRPADIIISTPASKGRRRLNFDSPYVSRAAAPIVRVTKARAWANRPMNRKPRMYRMYRSPDVPRGCEGPCKGQSFESRHDIQHIGKVMCVSDVTRGTGLTHRVGKRFCVKSVYVLGKIWMDENIKTKNHTNSVMFFLVRDRRPVDKPQDFGEVFNMFDNEPSTATVKNVHRDRYQVLRKWHATVTGGQYASKEQALVKKFVRVNNYVVYNQQEAGKYENHSENALMLYMACTHASNPVYATLKIRIYFYDSVTN |
| NCBI Accession | NP_598188.1 |
|---|---|
| Location | 1060-1464 |
| Gene Name | C3 |
| Protein Name | C3 protein |
| Coding Region | ATGGATTCACGCACAGCGGAACTCATCAAAGCTTCTCAAGCAGAGAATGGCGTGTTTATCTGGGAGATTCAAAATCCCCTGTATTTCAAGATAACAGAACACAACAACCGGCCATTTCTTATGAAAGAGGACATCATCACCGTCCAAATACAGTTCAATTACAACCTGAGGAAAGCGTTGGAGATACACAAGTGTTTTCTAGCCTACCGAATCTGGATGACTTCACAGCCTCCGACTGGGCAATTCTTAAGGGTCTTTAAGACCCAAGTGCTTAAATATTTAAATAATTTAGGAATTATCAGTATTAATAATGTAATTCGTGCAGTTGATCATGTATTATGGGATGTATTAGAACACATTGTATATGTAGACCAATCTTATTCAATAAAATTCAATATTTATTAA |
| Protein Sequence | MDSRTAELIKASQAENGVFIWEIQNPLYFKITEHNNRPFLMKEDIITVQIQFNYNLRKALEIHKCFLAYRIWMTSQPPTGQFLRVFKTQVLKYLNNLGIISINNVIRAVDHVLWDVLEHIVYVDQSYSIKFNIY |
| NCBI Accession | NP_598189.1 |
|---|---|
| Location | 1205-1609 |
| Gene Name | C2 |
| Protein Name | C2 protein |
| Coding Region | ATGCGATCTTCGTCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTAGCCAAGAAGGGGACGAGGCGTCGACGTGTTGATCTCCCTTGTGGGTGTTCATACTTCATAGCATTAGCCTGCCACAACCATGGATTCACGCACAGCGGAACTCATCAAAGCTTCTCAAGCAGAGAATGGCGTGTTTATCTGGGAGATTCAAAATCCCCTGTATTTCAAGATAACAGAACACAACAACCGGCCATTTCTTATGAAAGAGGACATCATCACCGTCCAAATACAGTTCAATTACAACCTGAGGAAAGCGTTGGAGATACACAAGTGTTTTCTAGCCTACCGAATCTGGATGACTTCACAGCCTCCGACTGGGCAATTCTTAAGGGTCTTTAA |
| Protein Sequence | MRSSSPSKAHSTQVPIKVQHRLAKKGTRRRRVDLPCGCSYFIALACHNHGFTHSGTHQSFSSREWRVYLGDSKSPVFQDNRTQQPAISYERGHHHRPNTVQLQPEESVGDTQVFSSLPNLDDFTASDWAILKGL |
| NCBI Accession | NP_598190.1 |
|---|---|
| Location | 1512-2597 |
| Gene Name | Rep |
| Protein Name | replication associated protein |
| Coding Region | ATGGCAGCCCCGAATCGGTTAAAAATAAATGCCAAAAATTATTTTCTCACTTATCCCAAGTGCTCCCTTACTAAAGAAGAGGCACTTTCCCAATTATTAAATCTCCAACCCCCAACAAACAAAAAATACATCAAGATCTGCAGAGAACTACACGAAGATGGGAGCCCTCATCTCCATGTGCTCATCCAGTTCGAAGGGAAATATCAGTGCAAGAATCAACGATTCTTCGACCTGGTCTCCCCAAACAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCACCGACGTCAAGTCCTACATCGACAAGGACGGAGACACCCTCGAATGGGGAGAGTTCCAGATCGATGGGAGATCTGCACGAGGAGGTCAACAGACAGCTAATGATGCTGCTGCAGAAGCCCTAAATGCAGGTTCTAAAGAAGCTGCAATGGCTATAATAAAGGAGAAACTCCCAGAAAAATTTATTTTTCAATATCATAATTTAAATTCTAATTTAGATAGGATTTTTACTCCTCCGTTGGAGGTTTATGTTTCGCCTTTTTTATCTTCTTCTTTTGATCAAGTTCCTGAAGAACTTGAAGAATGGGTCTCAGAAAATGTCATGAATGCCGCTGCGCGGCCTCTGAGGCCTCAAAGTATAGTAATTGAGGGAGACAGTCGTACGGGTAAAACGATGTGGGCTAGGTCATTAGGGCCTCATAATTACCTATGCGGTCATTTAGATCTAAGCCCCAAAGTTTACAGCAATGATGCGTGGTATAACATCATCGATGACGTAGATCCTCACTACCTAAAGCACTTTAAGGAATTCATGGGGGCCCAAAGGGACTGGCAATCAAATACCAAGTACGGAAAGCCAGTTCAAATTAAAGGCGGAATTCCCACTATCTTCCTCTGCAATCCAGGACCTAATTCAAGTTATAAAGAGTTCTTGGATGAAGAGAAGAATAATGCTCTCAAAAATTGGGCTTTAAAGAATGCGATCTTCGTCACCCTCGAAGGCCCACTCTACTCAGGTTCCAATCAAAGTGCAGCACAGGCTAGCCAAGAAGGGGACGAGGCGTCGACGTGTTGA |
| Protein Sequence | MAAPNRLKINAKNYFLTYPKCSLTKEEALSQLLNLQPPTNKKYIKICRELHEDGSPHLHVLIQFEGKYQCKNQRFFDLVSPNRSAHFHPNIQGAKSSTDVKSYIDKDGDTLEWGEFQIDGRSARGGQQTANDAAAEALNAGSKEAAMAIIKEKLPEKFIFQYHNLNSNLDRIFTPPLEVYVSPFLSSSFDQVPEELEEWVSENVMNAAARPLRPQSIVIEGDSRTGKTMWARSLGPHNYLCGHLDLSPKVYSNDAWYNIIDDVDPHYLKHFKEFMGAQRDWQSNTKYGKPVQIKGGIPTIFLCNPGPNSSYKEFLDEEKNNALKNWALKNAIFVTLEGPLYSGSNQSAAQASQEGDEASTC |
| NCBI Accession | NP_598191.1 |
|---|---|
| Location | 2183-2440 |
| Gene Name | C4 |
| Protein Name | C4 protein |
| Coding Region | ATGGGAGCCCTCATCTCCATGTGCTCATCCAGTTCGAAGGGAAATATCAGTGCAAGAATCAACGATTCTTCGACCTGGTCTCCCCAAACAGGTCAGCACATTTCCATCCGAACATTCAGGGAGCTAAATCCAGCACCGACGTCAAGTCCTACATCGACAAGGACGGAGACACCCTCGAATGGGGAGAGTTCCAGATCGATGGGAGATCTGCACGAGGAGGTCAACAGACAGCTAATGATGCTGCTGCAGAAGCCCTAA |
| Protein Sequence | MGALISMCSSSSKGNISARINDSSTWSPQTGQHISIRTFRELNPAPTSSPTSTRTETPSNGESSRSMGDLHEEVNRQLMMLLQKP |
References More References in PubMed
| 1 |
Ageratum enation virus-a begomovirus of weeds with the potential to infect crops. Tahir M, et al. Viruses. 2015 Feb 10;7(2):647-65. doi: 10.3390/v7020647. PMID: 25674770 |
|---|---|
| 2 |
Srivastava A, et al. Front Plant Sci. 2017 Jul 6;8:1172. doi: 10.3389/fpls.2017.01172. eCollection 2017. PMID: 28729873 |
| 3 |
Srivastava A, et al. Plant Dis. 2014 Sep;98(9):1285. doi: 10.1094/PDIS-04-14-0338-PDN. PMID: 30699665 |
| 4 |
Srivastava A, et al. Virus Genes. 2013 Dec;47(3):584-90. doi: 10.1007/s11262-013-0971-6. Epub 2013 Aug 21. PMID: 23963765 |
| 5 |
Genomic characterization of two new viruses infecting Ageratum conyzoides in China. Zhao F, et al. Arch Virol. 2023 May 5;168(5):155. doi: 10.1007/s00705-023-05781-y. PMID: 37145192 |
| 6 |
Srivastava S, et al. Phytochemistry. 2012 Aug;80:8-16. doi: 10.1016/j.phytochem.2012.05.007. Epub 2012 Jun 7. PMID: 22683210 |
| 7 |
Mo C, et al. Plant Dis. 2023 Oct;107(10):2944-2948. doi: 10.1094/PDIS-11-22-2688-SC. Epub 2023 Oct 23. PMID: 37125842 |
| 8 |
First Report of Ageratum yellow vein China virus Infecting Zinnia elegans in Vietnam. Li ZB, et al. Plant Dis. 2013 Mar;97(3):431. doi: 10.1094/PDIS-10-12-0943-PDN. PMID: 30722387 |
| 9 |
Srivastava A, et al. J Virol Methods. 2022 Feb;300:114432. doi: 10.1016/j.jviromet.2021.114432. Epub 2021 Dec 14. PMID: 34919973 |
| 10 |
Li P, et al. Arch Virol. 2018 Dec;163(12):3443-3446. doi: 10.1007/s00705-018-4004-6. Epub 2018 Aug 25. PMID: 30145682 |